Word2Vec、GloVe、FastText、解説
Word2Vec, GloVe, FastText - explanations.
コンピュータが単語を理解する方法
コンピュータは私たちと同じように単語を理解しません。彼らは数字で作業することを好みます。したがって、コンピュータが単語とその意味を理解するのを助けるために、私たちは埋め込みと呼ばれるものを使用します。これらの埋め込みは、単語を数学的ベクトルとして数値的に表します。
これらの埋め込みの素晴らしいところは、適切に学習すると、意味が似ている単語は類似した数値値を持つということです。言い換えれば、彼らの数値はお互いに近くなります。これにより、コンピュータは数値表現に基づいて、異なる単語間のつながりや類似点を把握することができます。
単語埋め込みを学習するための一つの主要な方法はWord2Vecです。この記事では、Word2Vecの複雑さについて掘り下げ、その様々なアーキテクチャとバリアントを探求します。
Word2Vec
初期の時代には、n-gramベクトルで文章を表現しました。これらのベクトルは、単語のシーケンスを考慮して、文章のエッセンスを捉えることを目的としていました。しかし、これらにはいくつかの制限がありました。n-gramベクトルはしばしば大きくてまばらであり、計算的に作成することが困難でした。これが次元の呪いと呼ばれる問題を引き起こしました。本質的に、高次元空間では、単語を表すベクトルが遠く離れすぎているため、どの単語が本当に似ているのかを決定することが困難になりました。
そして、2003年には、ニューラル確率言語モデルの導入により、驚くべきブレイクスルーが起こりました。このモデルは、連続的な密なベクトルと呼ばれるものを使用することによって、単語をどのように表現するかを完全に変えました。離散的でまばらなn-gramベクトルとは異なり、これらの密なベクトルは連続的な表現を提供しました。これらのベクトルに少しの変更を加えるだけで、意味のある表現が得られますが、それらは直接的に特定の英単語に対応するとは限りません。
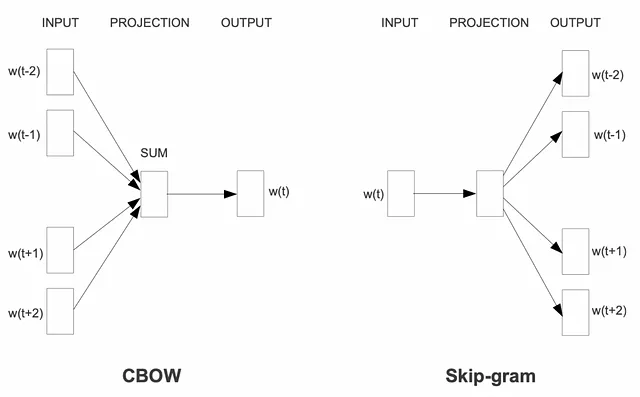
この素晴らしい進歩を基に、Word2Vecフレームワークが2013年に登場しました。これは、単語の意味を連続的な密なベクトルにエンコードする強力な方法を提供しました。Word2Vec内では、Continuous Bag of Words(CBoW)とSkip-gramの2つの主要なアーキテクチャが導入されました。
これらのアーキテクチャにより、高品質の単語埋め込みを生成する効率的なトレーニングモデルを実現しました。膨大な量のテキストデータを活用することで、Word2Vecは単語を数字の世界で生き生きとさせました。これにより、コンピュータは文脈に基づく意味や単語間の関係を理解し、自然言語処理に革新的なアプローチを提供することができました。
Continuous Bag-of-Words(CBoW)
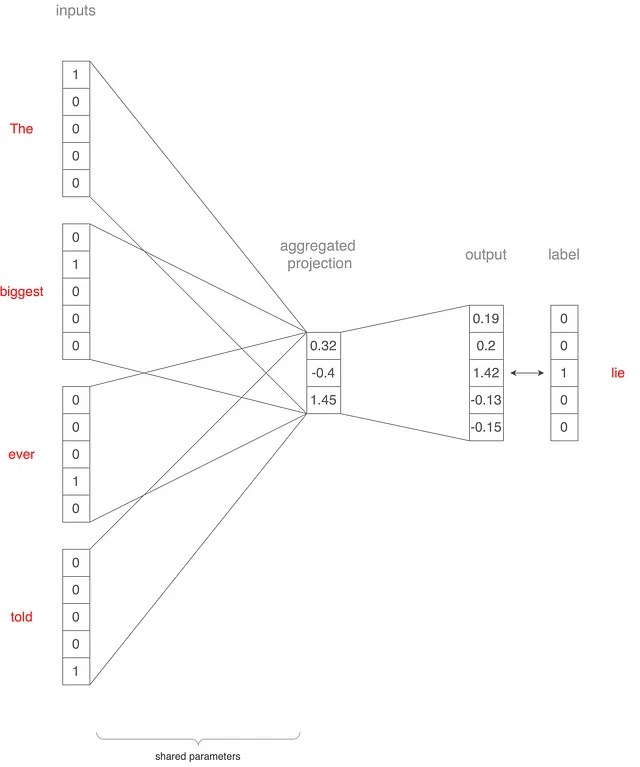
このセクションと次のセクションでは、CBoWとSkip-gramモデルが5つの単語(biggest、ever、lie、told、the)の小さな語彙を使用してトレーニングされる方法を理解しましょう。そして、例文「The biggest lie ever told」をどのようにCBoWアーキテクチャに渡すかを説明します。これは上図2に示されていますが、プロセスも説明します。
文脈ウィンドウサイズを2に設定したと仮定しましょう。 “The”、”biggest”、”ever”、”told”という単語を取り、5×1のワンホットベクトルに変換します。
これらのベクトルは、入力としてモデルに渡され、射影層にマップされます。この射影層にはサイズ3が設定されているとします。各単語のベクトルは、5×3の重み行列(入力に共有される)で乗算され、4つの3×1ベクトルが生成されます。これらのベクトルの平均値を取ると、1つの3×1ベクトルが得られます。このベクトルは、別の3×5重み行列を使用して、5×1ベクトルに再投影されます。
この最終的なベクトルは、中央の単語「lie」を表します。真のワンホットベクトルと実際の出力ベクトルを計算することにより、バックプロパゲーションを介してネットワークの重みが更新される損失が得られます。
我々は、コンテキストウィンドウをスライドさせて数千の文章に適用することで、このプロセスを繰り返します。トレーニングが完了した後、モデルの最初のレイヤーは、次元5×3(語彙サイズx射影サイズ)であり、学習されたパラメータを含んでいます。これらのパラメータは、各単語を対応するベクトル表現にマップするためのルックアップテーブルとして使用されます。
Skip-gram
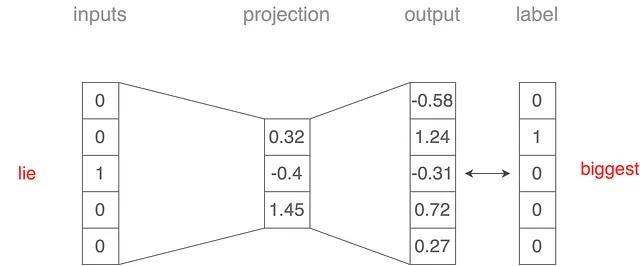
Skip-gramモデルでは、continuous bag-of-words(CBoW)の場合と同様のアーキテクチャを使用します。ただし、周囲の単語に基づいてターゲット単語を予測する代わりに、シナリオを反転させ、図3に示すように単語「lie」が入力となり、そのコンテキスト単語を予測するようにします。「skip-gram」という名前は、数単語を「スキップ」する可能性のあるコンテキスト単語を予測することを反映しています。
これを説明するために、いくつかの例を考えてみましょう。
- 入力単語「lie」は、出力単語「the」とペアになります。
- 入力単語「lie」は、出力単語「biggest」とペアになります。
- 入力単語「lie」は、出力単語「ever」とペアになります。
- 入力単語「lie」は、出力単語「told」とペアになります。
このプロセスをトレーニングデータのすべての単語で繰り返します。トレーニングが完了したら、語彙サイズx射影サイズの最初のレイヤーのパラメータが、入力単語とそれらに対応するベクトル表現との関係を捉えます。これらの学習されたパラメータにより、Skip-gramモデルにおいて入力単語をそれに対応するベクトル表現にマップすることができます。
利点
- 単純さで次元の呪いを克服:Word2Vecは、単語を密なベクトルとして表現することで、n-gramベクトルなどの従来の方法に関連する疎らさや計算の複雑さを軽減し、次元の呪いに対する簡単で効率的な解決策を提供します。
- 意味が似ている単語は、近いベクトル値を持つベクトルを生成:Word2Vecの埋め込みは、意味が似ている単語が数値的に近いベクトルで表現されるという貴重な特性を示します。これにより、意味的な関係を捉え、単語の類似性や類推検出などのタスクを実行することができます。
- 様々なNLPアプリケーションに対する事前学習済みの埋め込み:Word2Vecの事前学習済みの埋め込みは広く利用可能であり、感情分析、固有表現認識、機械翻訳などのタスクに利用することができます。これらの埋め込みは、大規模なコーパスでトレーニングされており、貴重なリソースを提供します。
- データ拡張とトレーニングのための自己監督フレームワーク:Word2Vecは、既存のデータを利用して単語表現を学習する自己監督形式で動作します。これにより、ラベル付きのデータセットを必要としないため、より多くのデータを収集し、モデルをトレーニングすることが容易になります。このフレームワークは、大量の未ラベルのテキストに適用することができ、トレーニングプロセスを強化します。
欠点
- グローバル情報の保存が限られている:Word2Vecの埋め込みは、主にローカルコンテキスト情報を捉えることに焦点を当てており、単語間のグローバルな関係を保存できない場合があります。この制限は、ドキュメント分類または文書レベルでの感情分析など、テキストの広い理解が必要なタスクに影響を与える可能性があります。
- 形態論が豊かな言語には適していない:形態論が豊かな言語は、複雑な語形や活用を特徴としており、Word2Vecにとっては課題を提供する場合があります。Word2Vecは、各単語を原子的な単位として扱うため、こうした言語に存在する豊かな形態論や意味的なニュアンスを捉えることができない場合があります。
- 広範なコンテキストの意識が欠けている:Word2Vecモデルは、トレーニング中にターゲット単語を囲む単語のローカルコンテキストウィンドウのみを考慮します。この限られたコンテキスト意識は、特定の文脈における単語の意味を完全に理解することができず、特定の言語現象に存在する長期的な依存関係や複雑な意味的関係を捉えるのに苦労する可能性があります。
次のセクションでは、これらの欠点に対処するいくつかの単語埋め込みアーキテクチャを見ていきます。
GloVe:グローバルベクトル
Word2Vecは、一定程度までローカルコンテキストを捉えることに成功していますが、コーパスで利用可能なグローバルコンテキストを十分に活用していません。グローバルコンテキストとは、コーパス全体の複数の文を使用して情報を集めることを指します。ここでGloVeが登場し、単語-単語の共起性を利用して単語埋め込みを学習します。
単語共起行列の概念はGloveにとって重要です。これは、コーパス内の他のすべての単語の文脈での各単語の出現を捉える行列です。行列の各セルは、別の単語の文脈での1つの単語の出現回数を表します。
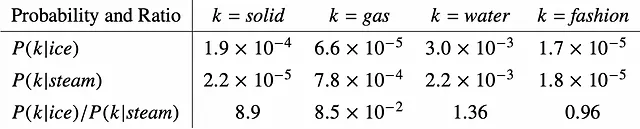
Gloveは、Word2Vecのように共起確率の確率を直接扱う代わりに、共起確率の比率から始めます。図4の文脈において、P(k | ice)は、単語kが「ice」の文脈で出現する確率を表し、P(k | steam)は、単語kが「steam」の文脈で出現する確率を表します。比率P(k | ice)/ P(k | steam)を比較することで、単語kのiceまたはsteamとの関連性を判断できます。比率が1よりもはるかに大きい場合、iceとの強い関連を示します。逆に、0に近い場合は、steamとの強い関連を示します。1に近い比率は、iceまたはsteamとの明確な関連がないことを示唆しています。
例えば、k =「solid」の場合、確率比は1よりもはるかに大きく、iceとの強い関連性を示しています。一方、k =「gas」の場合、確率比は0に近く、steamとの強い関連性を示唆しています。単語「water」や「fashion」については、iceまたはsteamとの明確な関連性は示されません。
確率比に基づく単語の関連性は、正確にはGloVeで学習する埋め込みで達成したい目的です。
FastText
従来のWord2Vecアーキテクチャは、グローバル情報の活用が欠けており、形態的に豊かな言語を効果的に扱うことができません。
形態的に豊かな言語とは何を意味するのでしょうか?このような言語では、単語は使用される文脈に基づいて形式を変更することができます。南インドの言語である「カンナダ語」の例を取りましょう。
カンナダ語では、「家」の単語は「ಮನೆ」(mane)と書かれます。しかし、「家の中で」と言うと、「ಮನೆಯಲ್ಲಿ」(maneyalli)になり、「家から」と言うと、「ಮನೆಯಿಂದ」(maneyinda)になります。見ての通り、前置詞のみが変わり、翻訳された単語には異なる形式があります。英語では、すべてが単に「家」です。その結果、従来のWord2Vecアーキテクチャは、これらすべてのバリエーションを同じベクトルにマップします。しかし、形態的に豊かなカンナダ語のWord2Vecモデルを作成した場合、これらの3つの場合それぞれに異なるベクトルが割り当てられます。さらに、カンナダ語の「家」という単語は、これら3つの例だけでなく、より多くの形式を取ることができます。コーパスにすべてのバリエーションが含まれていないため、従来のWord2Vecトレーニングは多様な単語表現を捉えることができない場合があります。
この問題に対処するため、FastTextは、単語ベクトルを生成する際にサブワード情報を考慮することで解決策を提供します。FastTextは、各単語を文字nグラムに分解し、trigramから6-gramまでの範囲でベクトルにマップします。これらのnグラムは、それぞれベクトルにマップされ、その後、全体の単語を表すために集約されます。これらの集約されたベクトルは、skip-gramアーキテクチャにフィードされます。
このアプローチにより、言語内の異なる単語形式間で共有される特性を認識することができます。コーパス内のすべての単語形式を見たわけではありませんが、学習されたベクトルは、これらの形式の共通点と類似点を捉えます。アラビア語、トルコ語、フィンランド語、およびさまざまなインドの言語など、形態的に豊かな言語は、FastTextの異なる形式とバリエーションを考慮に入れた単語ベクトルを生成する機能によって利益を得ることができます。
コンテキスト意識
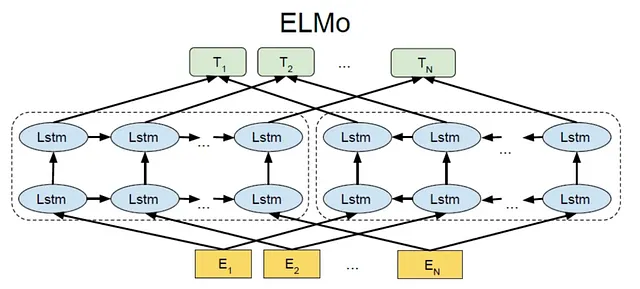
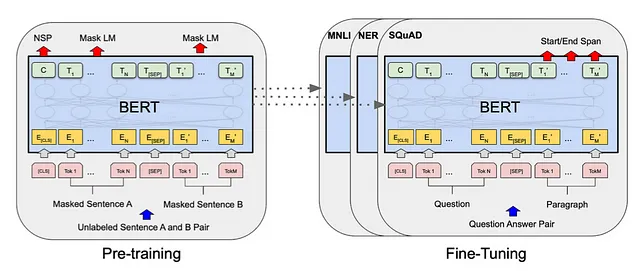
word2vecアーキテクチャには利点がありますが、次のような制限があります:文脈に関係なく、同じ単語に対して同じベクトル表現を生成します。
この点を説明するために、次の2つの文を考えてみましょう:
- 「That drag queen slays.」
- 「She has an ace and queen for a perfect hand.」
これらの文では、「queen」という単語には異なる意味があります。しかし、word2vecアーキテクチャでは、両方の場合に「queen」のベクトルが同じになります。これは理想的ではありません。なぜなら、単語ベクトルは、文脈に基づいて異なる意味を捉えて表現する必要があるからです。
この問題に対処するために、より高度なアーキテクチャ、例えばLSTMセルが導入されました。これらのアーキテクチャは、単語表現に文脈情報を組み込むように設計されています。その後、BERTやGPTなどのトランスフォーマーベースのモデルが登場し、現在見られる大規模言語モデルの開発につながりました。これらのモデルは、文脈を考慮して、周囲の単語や文章に敏感な単語表現を生成することに優れています。
これらの高度なアーキテクチャは、文脈を考慮することで、より微妙で意味のある単語ベクトルを作成し、同じ単語でも特定の文脈に応じて異なるベクトル表現を持つことができます。
結論
このブログ記事では、word2vecアーキテクチャと、単語を連続した密なベクトルを使用して表現する能力についての洞察を提供しました。GloVeなどの後続の実装はグローバルコンテキストを利用し、FastTextはアラビア語、フィンランド語、およびいくつかのインド言語のような形態的に豊かな言語のベクトルの効率的な学習を可能にしました。ただし、これらのアプローチの共通の欠点は、推論中に文脈に関係なく単語に同じベクトルを割り当てることで、単語の複数の意味を正確に表現するのに支障があることです。
この制限に対処するために、NLPの後続の進展では、LSTMセルとトランスフォーマーアーキテクチャが導入され、特定の文脈を捉えることに優れ、現代の大規模言語モデルの基盤となっています。これらのモデルは、異なるシナリオでの単語の微妙な意味を収容し、周囲の文脈に基づいて異なる単語表現を理解し生成する能力を持っています。
しかし、word2vecフレームワークは、自然言語処理の分野で多数のアプリケーションを支え続けているため、重要であることを認識することが重要です。その単純さと意味のある単語埋め込みを生成する能力は、単語の意味の文脈的な変動によって生じる課題にもかかわらず、価値があることが証明されています。
言語モデルの詳細については、このYouTubeプレイリストを参照してください。
Happy Learning!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






