検索増強視覚言語事前学習
Enhancement of search through visual and language pre-training.
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿
T5、GPT-3、PaLM、Flamingo、PaLIなどの大規模なモデルは、数百億のパラメータにスケーリングされ、大規模なテキストおよび画像データセットでトレーニングされると、多大な量の知識を格納する能力を示しました。これらのモデルは、画像キャプション、ビジュアルクエスチョンアンサリング、オープンボキャブラリー認識などのダウンストリームタスクで最先端の結果を達成しています。しかし、これらのモデルはトレーニングに膨大な量のデータを必要とし、数十億のパラメータ(多くの場合)を持ち、著しい計算要件を引き起こします。また、これらのモデルをトレーニングするために使用されるデータは古くなる可能性があり、世界の知識が更新されるたびに再トレーニングが必要になる場合があります。たとえば、2年前にトレーニングされたモデルは、現在のアメリカ合衆国大統領に関する古い情報を提供する可能性があります。
自然言語処理(RETRO、REALM)およびコンピュータビジョン(KAT)の分野では、検索増強モデルを使用してこれらの課題に取り組む研究がなされてきました。通常、これらのモデルは、単一のモダリティ(テキストのみまたは画像のみ)を処理できるバックボーンを使用して、知識コーパスから情報をエンコードおよび取得します。ただし、これらの検索増強モデルは、クエリと知識コーパスのすべての利用可能なモダリティを活用できず、モデルの出力を生成するために最も役立つ情報を見つけられない場合があります。
これらの問題に対処するために、「REVEAL:Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory」(CVPR 2023に掲載予定)では、複数のソースのマルチモーダル「メモリ」を利用して知識集中型クエリに答えることを学ぶビジュアル言語モデルを紹介します。REVEALは、ニューラル表現学習を使用して、さまざまな知識ソースをキー-バリューペアから成るメモリ構造に変換し、エンコードします。キーはメモリアイテムのインデックスとして機能し、対応する値はそれらのアイテムに関する関連情報を格納します。トレーニング中、REVEALは、キーエンベッディング、値トークン、およびこのメモリから情報を取得する能力を学習して、知識集中型クエリに対処します。このアプローチにより、モデルパラメータは暗記に専念するのではなく、クエリに関する推論に焦点を当てることができます。
- AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
- ビジュアルキャプション:大規模言語モデルを使用して、動的なビジュアルを備えたビデオ会議を補完する
- 多言語での音声合成の評価には、SQuIdを使用する
 |
| 多様な知識ソースから複数の知識エントリを取得する能力を持つビジュアル言語モデルを拡張することで、生成を支援します。 |
マルチモーダル知識コーパスからのメモリ構築
私たちのアプローチは、異なるソースからの知識アイテムのキーと値のエンベッディングを事前に計算し、キー-バリューペアにエンコードして統一された知識メモリにインデックスするREALMと似ています。各知識アイテムは、より詳細に表現されたトークンエンベッディングのシーケンスである値としてエンコードされます。以前の研究とは異なり、REVEALは、WikiData知識グラフ、Wikipediaのパッセージと画像、Web画像テキストペア、ビジュアルクエスチョンアンサリングデータなど、多様なマルチモーダル知識コーパスを活用しています。各知識アイテムは、テキスト、画像、両方の組み合わせ(たとえば、Wikipediaのページ)、または知識グラフからの関係または属性(たとえば、バラク・オバマは6’2 “の背丈)の場合があります。トレーニング中、モデルパラメータが更新されるたびに、REVEALはキーと値のエンベッディングを連続的に再計算します。ステップごとにメモリを非同期に更新します。
圧縮を使用したメモリのスケーリング
メモリ値をエンコードするための素朴な解決策は、各知識アイテムのトークンのすべてのシーケンスを保持することです。次に、モデルは、すべてのトークンを連結してトランスフォーマーエンコーダーデコーダーパイプラインに送信することで、入力クエリとトップkの取得されたメモリ値を融合することができます。このアプローチには2つの問題があります。1つ目は、数億の知識アイテムをメモリに保持する場合、各メモリ値が数百のトークンから構成されている場合、実用的ではないことです。2つ目は、トランスフォーマーエンコーダーが自己注意のために合計トークン数×kに対して2次の複雑度を持っていることです。そのため、Perceiverアーキテクチャを使用して知識アイテムをエンコードおよび圧縮することを提案しています。Perceiverモデルは、トランスフォーマーデコーダーを使用して、フルトークンシーケンスを任意の長さに圧縮します。これにより、kが100にもなるトップkメモリエントリを取得できます。
以下の図は、メモリのキー-バリューペアを構築する手順を示しています。各知識項目は、マルチモーダル視覚言語エンコーダを介して処理され、画像とテキストのトークンのシーケンスに変換されます。キー・ヘッドはこれらのトークンをコンパクトな埋め込みベクトルに変換します。バリュー・ヘッド(パーセプター)は、これらのトークンを少なくし、知識項目に関する適切な情報を保持します。
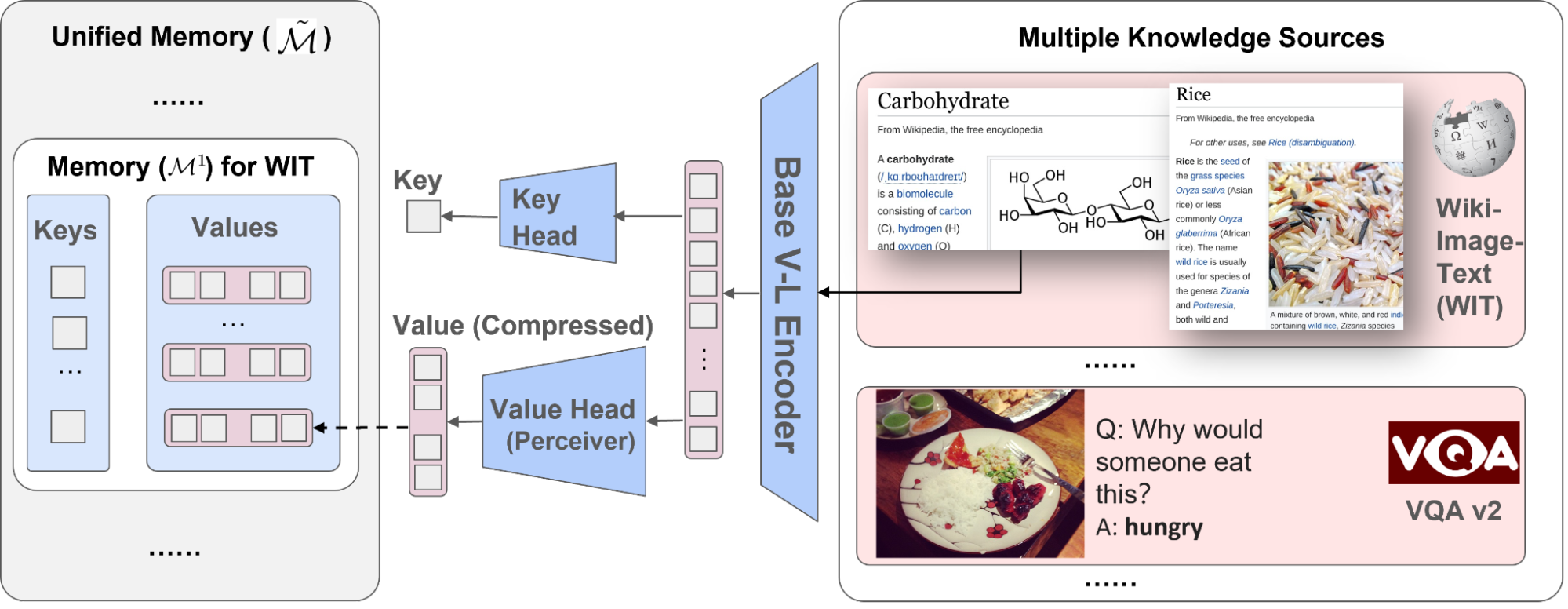 |
| 異なるコーパスからの知識エントリを統一されたキーとバリューの埋め込みペアにエンコードし、キーはメモリのインデックスに使用され、値にはエントリに関する情報が含まれます。 |
画像とテキストのペアに対する大規模な事前学習
REVEALモデルをトレーニングするために、LiTで紹介された公開Webから収集された30億の画像altテキストのキャプションペアを含む大規模なコーパスから始めます。データセットがノイズに汚染されているため、キャプションの文字数が50以下のデータポイントを除外するフィルターを追加し、およそ13億の画像キャプションペアが得られました。これらのペアをSimVLMで使用されたテキスト生成目的と組み合わせて、REVEALをトレーニングします。画像-テキストの例が与えられた場合、最初のいくつかのトークンを含むプレフィックスをランダムにサンプリングします。残りのテキストを出力する目的で、テキストプレフィックスと画像をモデルに入力します。トレーニングの目標は、プレフィックスを条件として残りのテキストシーケンスを自己回帰的に生成することです。
REVEALモデルのすべてのコンポーネントをエンドツーエンドでトレーニングするには、モデルを良好な状態にウォームスタートする必要があります(モデルパラメータの初期値を設定します)。そうでなければ、ランダムな重み(コールドスタート)から始めると、リトリーバーは有用なトレーニングシグナルを生成しない無関係なメモリアイテムを返すことがよくあります。このコールドスタート問題を避けるために、擬似-グラウンドトゥルース知識を使用した初期リトリーバーデータセットを構築します。
この目的のために、WITデータセットの変更版を作成します。WITの各画像キャプションペアには、対応するWikipediaのパッセージ(テキストの周囲の単語)が付属しています。周囲のパッセージをクエリ画像と組み合わせて、入力クエリに対応する擬似グラウンドトゥルース知識として使用します。このパッセージは、モデルを初期化するのに役立つ、画像とキャプションに関する豊富な情報を提供します。
リトリーバーがリトリーブに低レベルの画像特徴を依存しないようにするため、入力クエリ画像にランダムなデータ拡張を適用します。この擬似リトリーバルグラウンドトゥルースを含む変更版データセットを使用して、クエリとメモリキー埋め込みをトレーニングして、モデルをウォームスタートします。
REVEALのワークフロー
REVEALの全体的なワークフローは、主に4つのステップから構成されています。まず、REVEALはマルチモーダル入力をトークン埋め込みのシーケンスとコンデンスされたクエリ埋め込みにエンコードします。次に、モデルは各マルチソース知識エントリを統一されたキーとバリューの埋め込みペアに変換し、キーはメモリインデックスに使用され、値はエントリ全体の情報を包括します。その後、REVEALは複数の知識ソースからトップ-kに関連する知識ピースをリトリーブし、メモリに格納された事前処理されたバリュー埋め込みを返し、値を再エンコードします。最後に、REVEALは、リトリーブスコア(クエリ埋め込みとキー埋め込みのドット積)を注入することで、注意計算中の事前情報としてリトリーブスコアを使用する注意力融合レイヤーを経由して、トップ-kの知識ピースを融合します。この構造は、メモリ、エンコーダ、リトリーバー、およびジェネレータを同時にエンドツーエンドでトレーニングすることを可能にするのに役立ちます。
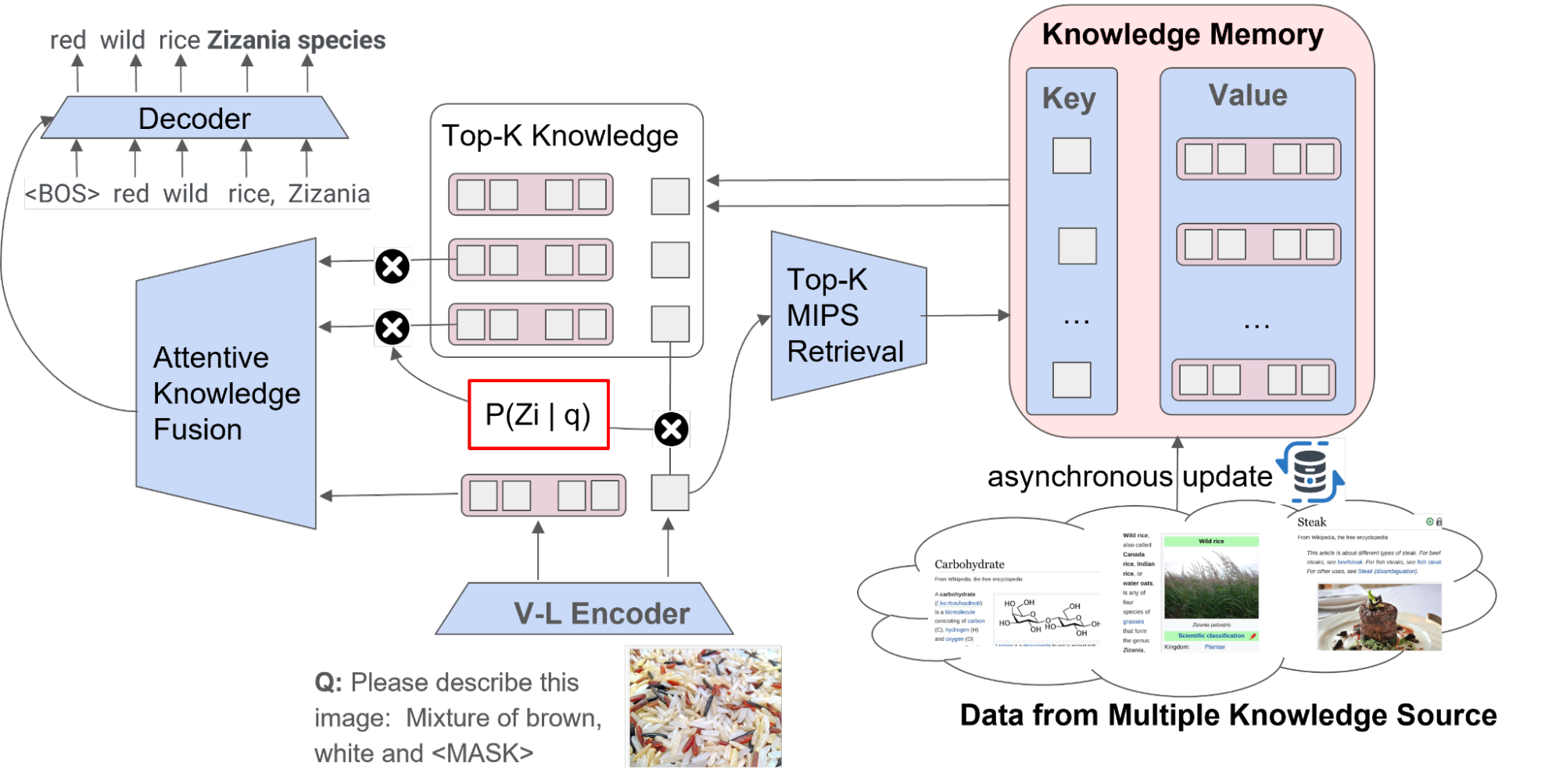 |
| REVEALの全体的なワークフロー。 |
結果
我々は、OK-VQAおよびA-OKVQAデータセットを使用した知識ベースの視覚的質問応答タスクにおいて、REVEALを評価しました。私たちは、同じ生成目的を使用して、事前に学習したモデルをVQAタスクに微調整しました。モデルは、画像-質問ペアを入力として受け取り、テキスト回答を出力として生成します。私たちは、REVEALが、固定された知識を組み込んだ以前の試みや、大規模言語モデル(例:GPT-3)を暗黙の知識源として利用する作品よりも、A-OKVQAデータセットでより良い結果を達成することを示しました。
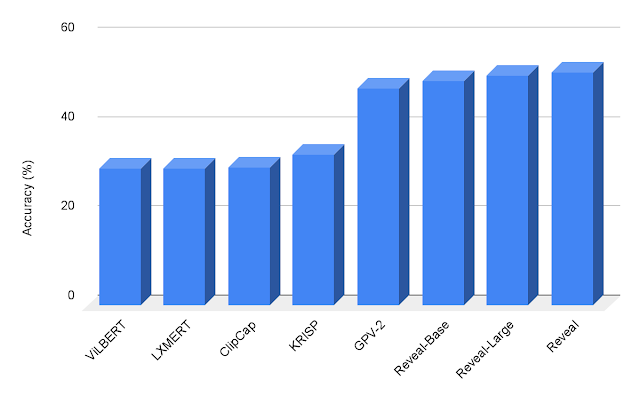 |
| A-OKVQAの視覚的質問応答の結果。REVEALは、ViLBERT、LXMERT、ClipCap、KRISP、GPV-2を含む以前の作品に比べて、より高い精度を達成します。 |
私たちはまた、MSCOCOおよびNoCapsデータセットを使用したイメージキャプショニングのベンチマークでREVEALを評価しました。私たちは、交差エントロピー生成目的を介して、MSCOCOトレーニング分割でREVEALを直接微調整しました。私たちは、MSCOCOテスト分割とNoCaps評価セットで、単語の選択、文法、意味、および内容に関して参照キャプションと似ているべきであるという考えに基づいたCIDErメトリックを使用してパフォーマンスを測定しました。MSCOCOキャプションとNoCapsデータセットの結果を以下に示します。
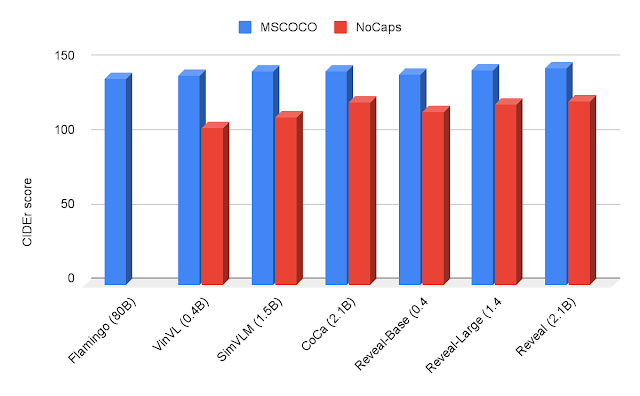 |
| CIDErメトリックを使用したMSCOCOおよびNoCapsのイメージキャプショニング結果。REVEALは、Flamingo、VinVL、SimVLM、CoCaに比べて、より高いスコアを達成します。 |
以下に、REVEALが視覚的質問に答えるために関連するドキュメントを検索する方法のいくつかの質的な例を示します。
 |
| REVEALは、異なるソースからの知識を正しく利用して質問に答えることができます。 |
結論
私たちは、様々なモダリティを持つ多様な知識源を利用する知識検索型のビジュアル言語(REVEAL)モデルを提案しました。私たちは、4つの異なる知識コーパスを含む大規模な画像テキストコーパスでREVEALをトレーニングし、知識集約型の視覚的質問応答およびイメージキャプションタスクにおいて最先端の結果を達成しました。将来的には、このモデルの帰属能力を探求し、より広範なマルチモーダルタスクに適用したいと考えています。
謝辞
この研究は、Ziniu Hu、Ahmet Iscen、Chen Sun、Zirui Wang、Kai-Wei Chang、Yizhou Sun、Cordelia Schmid、David A. Ross、Alireza Fathiによって実施されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- スピードは必要なすべてです:GPU意識の最適化による大規模拡散モデルのオンデバイス加速化
- アクセラレータの加速化:科学者がGPUとAIでCERNのHPCを高速化
- Microsoft BingはNVIDIA Tritonを使用して広告配信を高速化
- 魚の養殖スタートアップ、AIを投入して水産養殖をより効率的かつ持続可能にする
- AIを活用した空中監視:UCSBイニシアチブがNVIDIA RTXを使い、宇宙の脅威を撃退する目的で立ち上がる
- メイカーに会おう:ソフトウェアエンジニアがNVIDIA Jetsonを活用して自律運転スケートパークを構築
- 焼け落ちた炎:スタートアップが生成AI、コンピュータビジョンを融合して山火事と戦う





