Rによるディープラーニング
Deep Learning with R
はじめに
人工知能の進歩には、AlexaやTeslaの自動運転車など、数多くの革新的なものがあり、誰もが驚嘆することでしょう。私自身もこれらの進歩に感嘆していますが、それらの革新の背後にあるものを知ることがさらに興味深いと思います。ここでは、人工知能と深層学習の無限の可能性について紹介します。深層学習に関心を持っている方は、ぜひお読みください。
このチュートリアルでは、用語を分解し、Rで深層学習タスクを実行する方法を説明します。この記事では、回帰、分類、クラスタリングなどの機械学習の基本的な理解があることを前提としています。
まず、深層学習という概念に関連する用語の定義から始めましょう。
深層学習は、人間の脳の認知機能を模倣することで、コンピューターに機械学習を教える機械学習の一分野です。これは、データセット内の複雑なパターンを解析するのに役立つ人工ニューラルネットワークを使用して実現されます。深層学習を使用すると、コンピューターは音、画像、テキストなどを分類することができます。
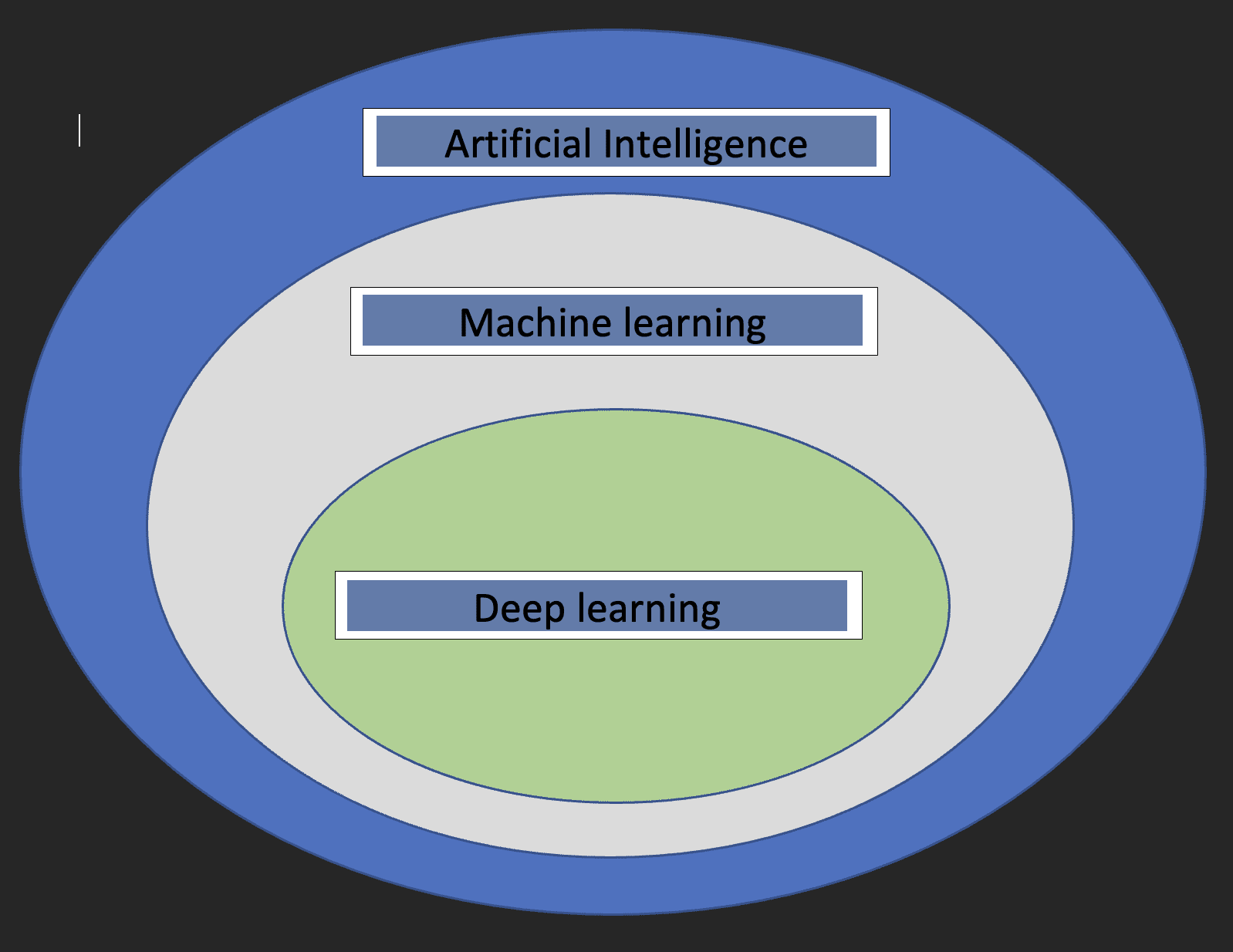
深層学習の詳細について説明する前に、機械学習と人工知能が何であるか、そしてこれらの3つの概念がどのように関連しているかを理解することが重要です。
人工知能:これは、コンピュータサイエンスの分野であり、人間の脳の機能を模倣するマシンの開発に関心があります。
機械学習:これは、コンピューターがデータから学習することを可能にする人工知能のサブセットです。
上記の定義から、深層学習が人工知能と機械学習とどのように関連しているかがわかりました。
以下の図は、この関係を示すのに役立ちます。
深層学習について注意すべき2つの重要な点は次のとおりです。
- 膨大な量のデータが必要
- 高性能なコンピューティングパワーが必要
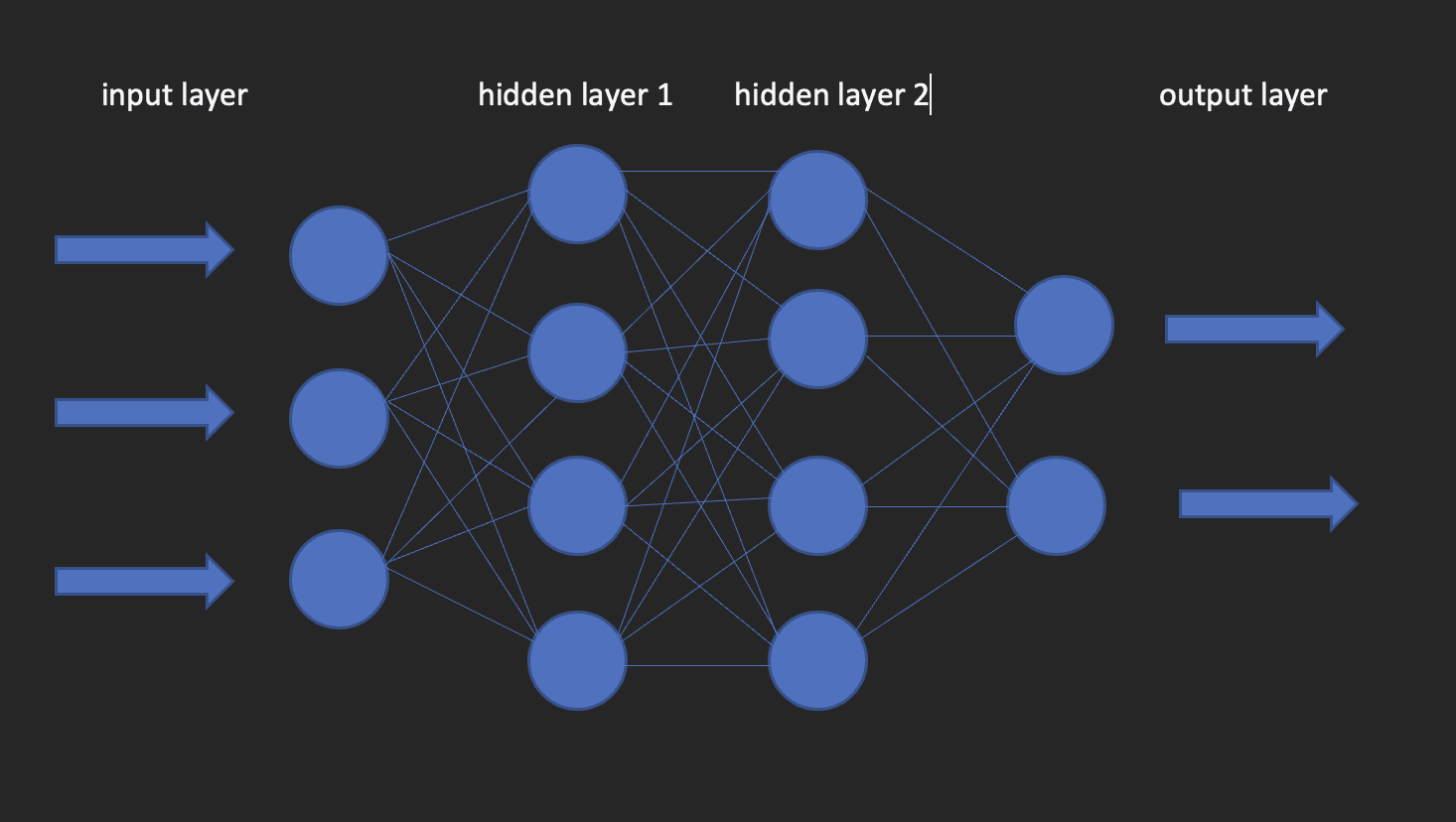
ニューラルネットワーク
これらは、深層学習モデルの構成要素です。名前のとおり、ニューラルは、人間の脳のニューロンから来ています。実際、深層ニューラルネットワークのアーキテクチャは、人間の脳の構造からインスピレーションを得ています。
ニューラルネットワークには、入力層、1つの隠れ層、および出力層があります。このネットワークは、浅いニューラルネットワークと呼ばれます。複数の隠れ層がある場合、層は100層以上になり、深層ニューラルネットワークになります。
以下の画像は、ニューラルネットワークの外観を示しています。
これで、Rで深層学習モデルを構築する方法について考えてみましょう。ここで、keraが登場します!
Kerasは、機械学習においてニューラルネットワークを使用することを簡単にするオープンソースの深層学習ライブラリです。このライブラリは、バックエンドエンジンとしてTensorFlowを使用するラッパーです。ただし、TheanoやCNTKなどのバックエンドのオプションもあります。
TensorFlowとKerasの両方をインストールしましょう。
reticulateを使用して仮想環境を作成して開始します。
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3")
install.packages(“tensorflow”) #これは1度だけ行います!
library(tensorflow)
install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu")
install.packages(“keras”) #これは1度だけ行います!
library(keras)
install_keras(envname = "/path/to/your/virtualenv")
# インストールが成功したことを確認します
tf$constant("Hello TensorFlow!")これで、設定が完了したので、ディープラーニングを使用して分類問題を解決する方法について説明します。
データの概要
このチュートリアルで使用するデータは、https://www.askamanager.org によって実施されている給与調査から取得したものです。
フォームで尋ねられる主な質問は、どのくらいのお金を稼いでいるかであり、業界、年齢、経験年数などの詳細を含みます。詳細はGoogleシートに収集され、そこからデータを取得しました。
データを使用して解決したい問題は、年齢、性別、経験年数、最高学歴などの情報を与えた場合に、誰かが潜在的に稼ぐことができる金額を予測する深層学習モデルを作成することです。
必要なライブラリを読み込みます。
library(dplyr)
library(keras)
library(caTools)データをインポートします。
url <- “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv”
salary_data <- read.csv(url)必要な列を選択します。
salary_data <- salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)データのクリーニング
コンピューターサイエンスにおけるGIGOコンセプトを覚えていますか?(ゴミを入れればゴミが出る)このコンセプトは、他の分野と同様に、ここでも完全に適用できます。トレーニングの結果は、使用するデータの品質に大きく依存するため、データクリーニングと変換は、どのデータサイエンスプロジェクトにおいても重要なステップです。
データクリーニングが対処しようとする主な問題のいくつかは、一貫性、欠損値、スペルミス、外れ値、およびデータ型です。これらの問題がどのように対処されるかについては詳しく説明しませんが、この記事の主題から逸れたくないという単純な理由からです。したがって、データのクリーニングがどのように処理されたか知りたい場合は、この記事を確認してください。
データの変換
人工ニューラルネットワークは数字のみを受け入れます。そのため、いくつかの変数がカテゴリー的な性質を持っているため、それらを数字にエンコードする必要があります。これは、モデリングに使用できるデータがすでに用意されているわけではないことがほとんどであるため、データ前処理の一部を形成します。
# エンコード関数を作成する
encode_ordinal <- function(x, order = unique(x)) {
x <- as.numeric(factor(x, levels = order, exclude = NULL))
}
salary_data <- salary_data %>% mutate(
highest_edu_level = encode_ordinal(highest_edu_level, order = c("High School","College degree","Master's degree","Professional degree (MD, JD, etc.)","PhD")),
professional_experience_years = encode_ordinal(professional_experience_years,
order = c("1 year or less", "2 - 4 years","5-7 years", "8 - 10 years", "11 - 20 years", "21 - 30 years", "31 - 40 years", "41 years or more")),
age = encode_ordinal(age, order = c( "under 18", "18-24","25-34", "35-44", "45-54", "55-64","65 or over")),
gender = case_when(gender== "Woman" ~ 0,
gender == "Man" ~ 1))分類を解決するために、年収を2つのクラスに分類する必要があります。これを応答変数として使用するためです。
salary_data <- salary_data %>%
mutate(categories = case_when(
annual_salary <= 100000 ~ 0,
annual_salary > 100000 ~ 1))
salary_data <- salary_data %>% select(-annual_salary)データの分割
基本的な機械学習アプローチである回帰、分類、クラスタリングと同様に、データをトレーニングセットとテストセットに分割する必要があります。これは、データセットの80%をトレーニング、20%をテストに使用する80-20ルールを使用して行います。これは、固定されたものではありません。必要に応じて、任意の分割率を使用できますが、トレーニングセットが割合の良いシェアを持っていることを忘れないでください。
set.seed(123)
sample_split <- sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set <- subset(x=salary_data, sample_split == TRUE)
test_set <- subset(x = salary_data, sample_split == FALSE)
y_train <- train_set$categories
y_test <- test_set$categories
x_train <- train_set %>% select(-categories)
x_test <- test_set %>% select(-categories)Kerasは、行列または配列の形式で入力を受け入れます。変換のためにas.matrix関数を使用します。また、予測変数をスケーリングする必要があります。その後、応答変数をカテゴリーデータ型に変換します。
x <- as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x))))
y <- to_categorical(y_train, num_classes = 2)モデルのインスタンス化
パイプ演算子を使用してレイヤーを追加していくシーケンシャルモデルを作成します。
model = keras_model_sequential()レイヤーの設定
input_shape : 入力データの形状を指定します。この例では、ncol 関数を使用して取得しました。 activation : 次のレイヤーに渡す前に、出力を所望の非線形形式に変換する数学関数を指定します。
units : ニューラルネットワークの各レイヤーのニューロンの数を指定します。
model %>%
layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>%
layer_dense(units = 10, activation = "relu") %>%
layer_dense(units = 2, activation = "sigmoid")モデルの学習プロセスの設定
コンパイルメソッドを使用して、モデルの学習プロセスを設定します。3つの引数を受け取ります。
optimizer : トレーニング手順を指定するオブジェクトです。 loss : 最小化する関数です。mse(平均二乗誤差)、binary_crossentropy、categorical_crossentropy などのオプションがあります。
metrics : トレーニングを監視するために使用するものです。分類問題の場合は精度を使用します。
model %>%
compile(
loss = "binary_crossentropy",
optimizer = "adagrad",
metrics = "accuracy"
)モデルのフィッティング
Keras の fit メソッドを使用して、モデルをフィットさせることができます。 fit が受け取る引数の一部は以下の通りです。
epochs : トレーニングデータセットの反復です。
batch_size : モデルは、トレーニング中に渡された行列/配列を小さなバッチにスライスし、その上で反復処理を行います。
validation_split : Keras は、各エポックでモデルのパフォーマンスを評価するために使用される検証セットを取得するために、トレーニングデータの一部をスライスする必要があります。
shuffle : 各エポックの前にトレーニングデータをシャッフルするかどうかを指定します。
fit = model %>%
fit(
x = x,
y = y,
shuffle = T,
validation_split = 0.2,
epochs = 100,
batch_size = 5
)モデルの評価
下記のように evaluate 関数を使用して、モデルの精度値を取得することができます。
y_test <- to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)予測
新しいデータで予測するには、下記のように keras ライブラリの predict_classes 関数を使用します。
model %>% predict(as.matrix(x_test))結論
この記事では、Keras を使用したディープラーニングの基本を紹介しました。パラメータを調整したり、データの準備に手を加えたり、クラウドコンピューティングの力を利用して演算をスケールしたりすることで、さらに深く理解することができます。データ可視化、データ整形、機械学習のスキルを持つデータサイエンティストとして、Clinton Oyogo 氏は、分析可能な洞察を得るためのデータの分析が日々の業務の重要な部分であると考えています。
元の記事はこちらから。許可を得て再掲載しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles