機械学習モデルのための高度な特徴選択技術
Advanced feature selection techniques for machine learning models.

機械学習は、新しい時代の輝かしい星です。異なる主要な技術のバックボーンを形成し、私たちの日常生活に不可欠な存在となっています。たとえば、顔認識(畳み込みニューラルネットワークまたはCNNによってサポートされる)、音声認識(CNNと再帰的ニューラルネットワークまたはRNNを利用する)、そしてChatGPTのようなますます人気を集めるチャットボット(人間のフィードバックからの強化学習によって動作する)。
今日は、機械学習モデルの性能を向上させるために利用可能な多数の方法の中でも、特徴量選択技術の世界に深く入り込んでみましょう。しかし、進む前に、何が特徴量選択とは何かを明確にしましょう。
特徴量選択とは何ですか?
特徴量選択は、モデルに最適な特徴量を選択するプロセスです。このプロセスは、技術によって異なる場合がありますが、主な目的は、どの特徴量がモデルに最も影響を与えるかを見つけることです。
なぜ特徴量選択を行う必要がありますか?
ときには、特徴量が多すぎると、機械学習モデルに損害を与える可能性があります。どうして?
さまざまな理由があるかもしれません。たとえば、これらの特徴量が互いに関連している場合、多重共線性を引き起こして、モデルの性能を損なう可能性があります。
別の潜在的な問題は、計算能力に関連しています。特徴量が多すぎると、タスクを並列実行するためにより多くの計算能力が必要になり、より多くのリソースとそれに伴うコストが必要になる可能性があります。
確かに、他にも理由があるかもしれません。しかし、これらの例は、潜在的な問題の一般的なアイデアを与えるはずです。しかし、このトピックにさらに深く踏み込む前に、理解する必要があるもう1つの重要な側面があります。
どの特徴量選択方法が私のモデルに適しているでしょうか?
はい、それは素晴らしい質問です。しかし、プロジェクトを開始する前に答える必要があります。一般的な答えを与えることは簡単ではありません。
特徴量選択モデルの選択は、持っているデータのタイプとプロジェクトの目的に依存します。
たとえば、カテゴリカルデータの特徴量選択には、カイ二乗検定または相互情報量のようなフィルター型の手法が一般的に使用されます。数値データには、フォワードまたはバックワード選択などのラッパー型の手法が適しています。
しかし、多くの特徴量選択方法は、カテゴリカルデータと数値データの両方を扱うことができます。
たとえば、Lasso回帰、決定木、ランダムフォレストは、両方のデータタイプに対して非常によく機能します。
監視付きおよび非監視付きの特徴量選択に関しては、再帰的特徴量削減または決定木のような監視付きの手法がラベル付きデータに適しています。主成分分析(PCA)または独立成分分析(ICA)のような非監視付きの手法は、ラベルのないデータに使用されます。
最終的には、特定のデータの特性とプロジェクトの目標に基づいて、特徴量選択方法を選択する必要があります。
記事で取り上げるトピックの概要を見てください。それを理解して、監視付き特徴量選択技術から始めましょう。 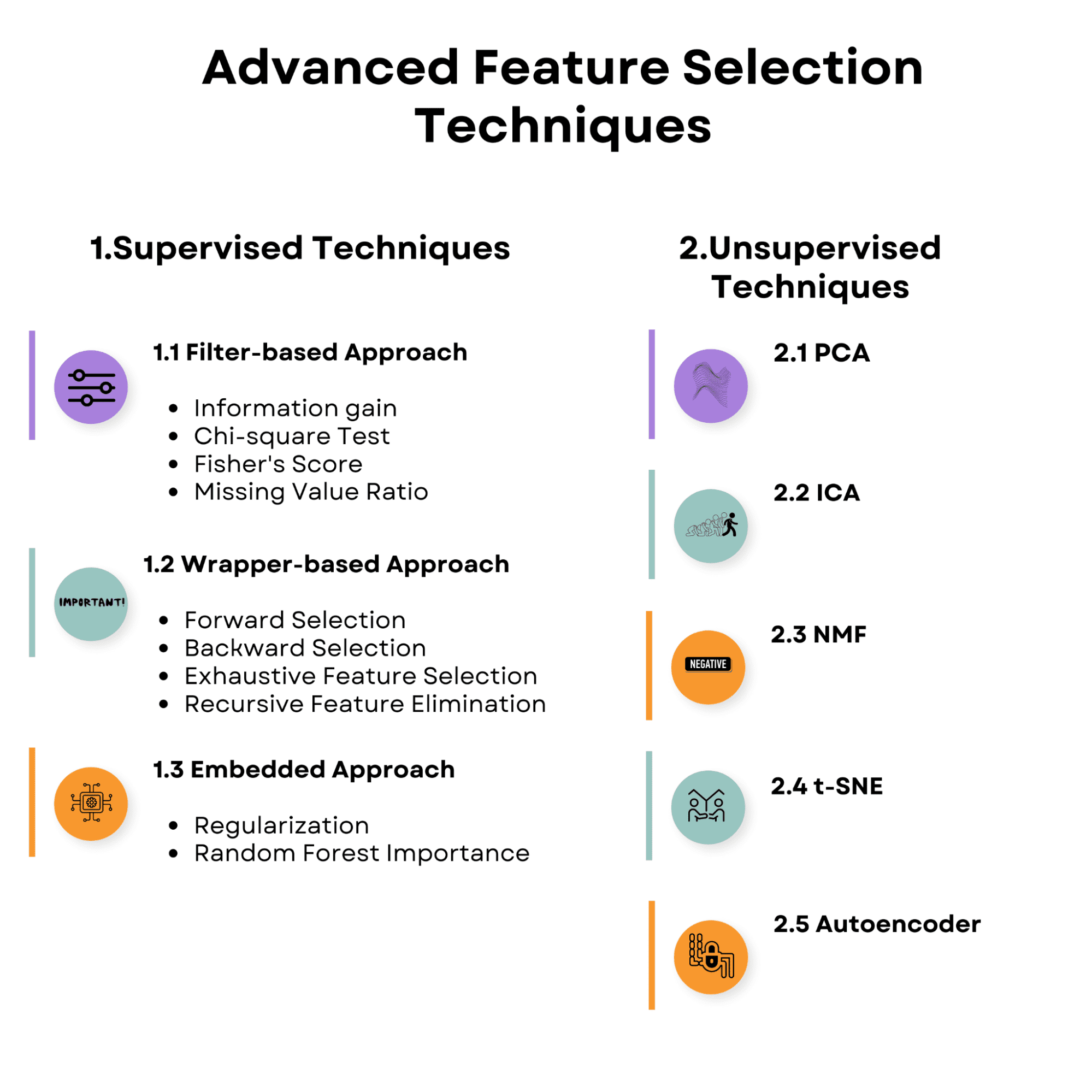
1. 監視付き特徴量選択技術
監視学習における特徴量選択戦略は、入力特徴量とターゲット変数の関係を利用して、ターゲット変数を予測するための最も関連性の高い特徴量を発見することを目的としています。これらの戦略は、モデルの性能を向上させ、過剰適合を減らし、モデルのトレーニングに必要な計算コストを低下させることができます。
ここでは、監視付き特徴量選択技術の概要を示します。
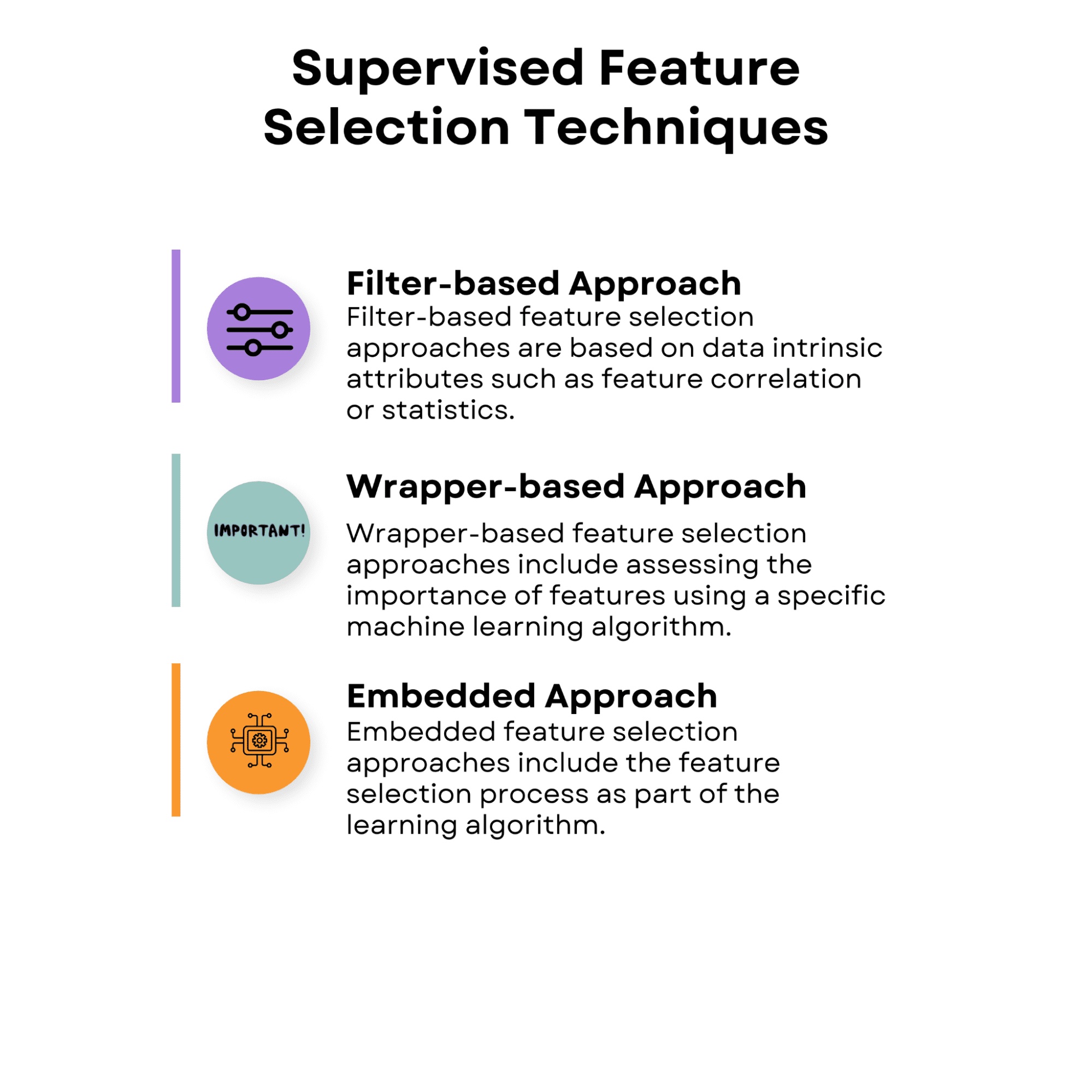
1.1 フィルター型アプローチ
フィルター型特徴量選択アプローチは、特徴量の相関や統計量など、データ固有の属性に基づいています。これらのアプローチでは、特定の学習アルゴリズムのパフォーマンスを考慮せずに、各特徴量の価値を単独またはペアで評価します。
フィルター型アプローチは計算効率が高く、様々な学習アルゴリズムで使用できるため、利用価値があります。ただし、特徴量間の相互作用や学習手法を考慮しないため、特定のアルゴリズムに最適な特徴量のサブセットを常に捉えることができない場合があります。
フィルタベースの手法の概要を確認してから、それぞれについて議論します。

情報利得
情報利得は、その特徴に応じてデータを分割することによって、特定の特徴のエントロピー(不確実性)の低下を測定する統計量です。決定木アルゴリズムでよく使用され、有用な機能もあります。特徴の情報利得が高いほど、決定に役立ちます。
さて、事前に構築された糖尿病データセットを使用して、情報利得を適用しましょう。
糖尿病データセットには、糖尿病の進行を予測するために関連する生理学的特徴が含まれています。
- age:年齢
- sex:性別(1 = 男性、0 = 女性)
- BMI:体重(キログラム)を身長(メートル)の二乗で割ったものによって計算される体格指数
- bp:平均血圧(mmHg)
- s1、s2、s3、s4、s5、s6:6つの異なる血液化学物質(グルコースを含む)の血清測定値
次のコードは、Information Gainメソッドを適用する方法を示しています。このコードは、例としてsklearnライブラリから糖尿病データセットを使用しています。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# 糖尿病データセットをロード
data = load_diabetes()
# データセットを特徴量とターゲットに分割
X = data.data
y = data.targetこのコードの主な目的は、情報利得に基づく特徴重要度スコアを計算し、予測モデルに最も関連する特徴を特定することです。これらのスコアを決定することにより、分析から除外するべき特徴と含めるべき特徴についての情報を得ることができます。これにより、モデルのパフォーマンスが向上し、過学習が減少し、トレーニング時間が短縮されます。
これを実現するために、このコードは、データセット内の各特徴の情報利得スコアを計算し、それらを辞書に格納します。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# 糖尿病データセットをロード
data = load_diabetes()
# データセットを特徴量とターゲットに分割
X = data.data
y = data.target
# 情報利得を適用
ig = mutual_info_regression(X, y)
# 特徴重要度スコアの辞書を作成
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]その後、特徴はスコアに従って降順でソートされます。
# 特徴を重要度スコアの降順でソート
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# 特徴重要度スコアとソートされた特徴を出力
for feature, score in sorted_features:
print('Feature:', feature, 'Score:', score)次に、ソートされた特徴重要度スコアを水平棒グラフとして可視化し、与えられたタスクで異なる特徴の関連性を簡単に比較できるようにします。
この視覚化は、機械学習モデルを構築する際に保持すべき特徴を決定する際に特に役立ちます。
# 特徴重要度スコアの水平棒グラフをプロット
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # ラベルは上から下に読む
ax.set_xlabel("重要度スコア")
ax.set_title("特徴重要度スコア(情報利得)")
# 水平棒グラフに重要度スコアをラベルとして追加
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()全体のコードを見てみましょう。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.feature_selection import mutual_info_regression
# 糖尿病データセットをロード
data = load_diabetes()
# データセットを特徴量とターゲットに分割
X = data.data
y = data.target
# 情報利得を適用
ig = mutual_info_regression(X, y)
# 特徴重要度スコアの辞書を作成
feature_scores = {}
for i in range(len(data.feature_names)):
feature_scores[data.feature_names[i]] = ig[i]
# 特徴を重要度スコアの降順でソート
sorted_features = sorted(feature_scores.items(), key=lambda x: x[1], reverse=True)
# 特徴重要度スコアとソートされた特徴を出力
for feature, score in sorted_features:
print("Feature:", feature, "Score:", score)
# 特徴重要度スコアの水平棒グラフをプロット
fig, ax = plt.subplots()
y_pos = np.arange(len(sorted_features))
ax.barh(y_pos, [score for feature, score in sorted_features], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels([feature for feature, score in sorted_features])
ax.invert_yaxis() # ラベルは上から下に読む
ax.set_xlabel("重要度スコア")
ax.set_title("特徴重要度スコア(情報利得)")
# 水平棒グラフに重要度スコアをラベルとして追加
for i, v in enumerate([score for feature, score in sorted_features]):
ax.text(v + 0.01, i, str(round(v, 3)), color="black", fontweight="bold")
plt.show()以下が出力です。 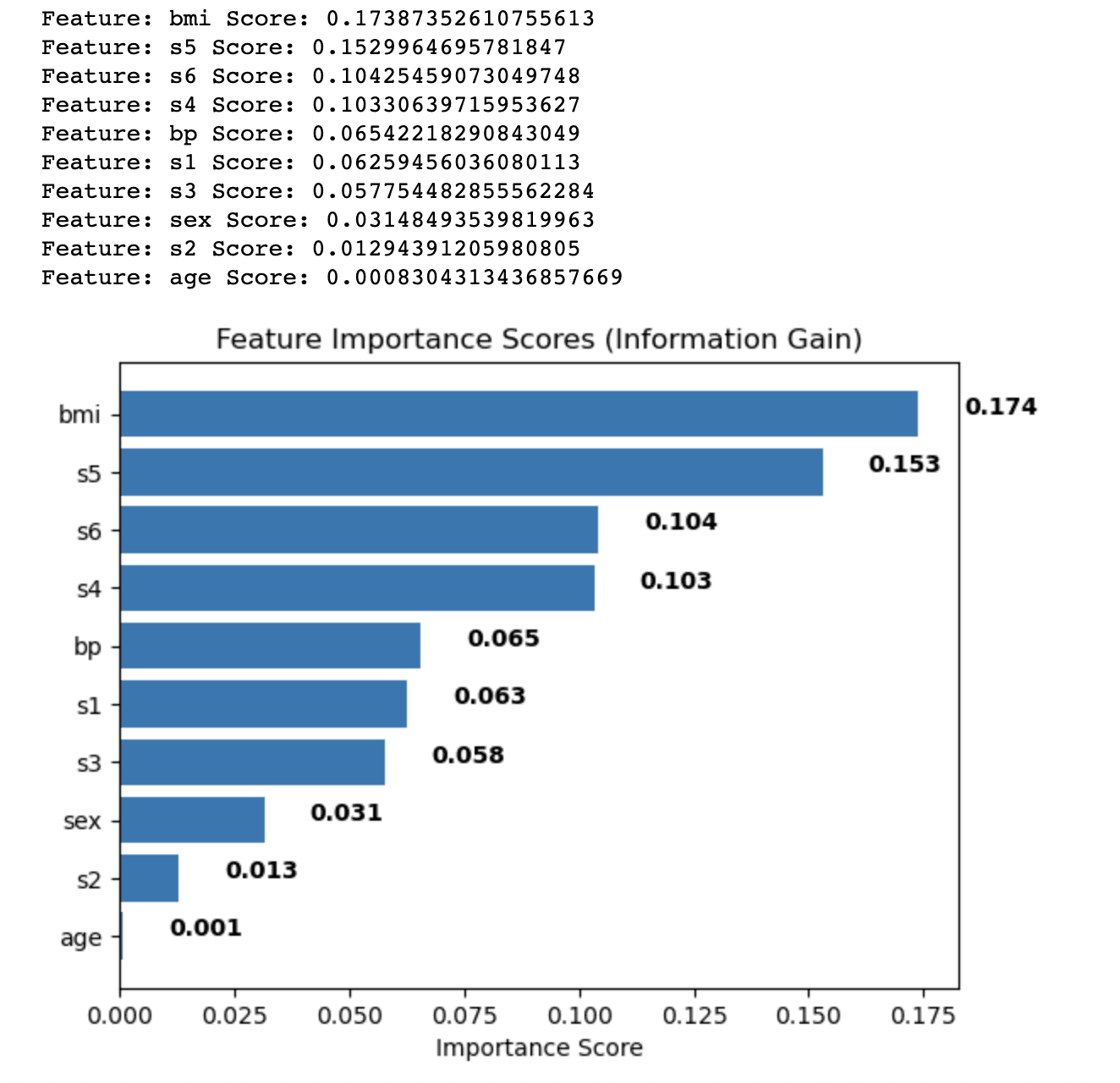
出力には、糖尿病データセットの各特徴量に対して情報利得法を使用して計算された特徴量の重要度スコアが表示されます。スコアに基づいて各特徴量が降順で並べ替えられ、目的変数を予測する上での相対的な重要性を示します。
結果は以下の通りです:
- 身体質量指数(BMI)が最も重要性スコア(0.174)を持ち、糖尿病データセットで目的変数に最も重要な影響を与えることを示しています。
- 血清測定5(s5)がスコア0.153で続き、2番目に重要な特徴量となります。
- 血清測定6(s6)、血清測定4(s4)および血圧(bp)は、0.104から0.065までの中程度の重要度スコアを持ちます。
- 性別や年齢などの残りの特徴量である血清測定1、2、および3(s1、s2、s3)、性別、年齢などは、比較的低い重要度スコアを持ち、モデルの予測力に対して貢献度が低いことを示しています。
これらの特徴量の重要度スコアを分析することで、機械学習モデルのパフォーマンスを改善するために分析から含めるか含めないかを決定できます。この場合、BMIやs5などの重要性スコアが高い特徴量を保持し、s2や年齢などのスコアが低い特徴量を削除するかさらに調査するかを検討することができます。
カイ二乗検定
カイ二乗検定は、2つのカテゴリカル変数間の関係を評価するために使用される統計検定です。カテゴリカル特徴量と目的変数の関係を分析するために特徴量選択に使用されます。カイ二乗スコアが大きいほど、特徴量と目的変数の関係が強く、分類にとって特徴量がより重要であることを示します。
カイ二乗検定は、特徴量と目的変数が離散的であるカテゴリカルデータで一般的に使用されます。
フィッシャーのスコア
フィッシャーの判別比率、一般的にはフィッシャーのスコアとして知られる、データセット内のさまざまなクラスを区別する能力に基づいて特徴量をランク付けする特徴量選択アプローチです。分類問題の連続的な特徴量に使用できます。
フィッシャーのスコアは、クラス間分散とクラス内分散の比率として計算されます。フィッシャーのスコアが高いほど、特徴量がより区別的であり、分類にとってより価値があることを示します。
フィッシャーのスコアを特徴量選択に使用するには、各連続的な特徴量にスコアを計算し、スコアに基づいてランク付けします。モデルは、フィッシャーのスコアが高い特徴量により重要性を付けます。
欠損値比率
欠損値比率は、特徴量の欠損値の数に基づいて決定を下す簡単な特徴量選択方法です。
多数の欠損値を持つ特徴量は、情報がなく、モデルのパフォーマンスに悪影響を与える可能性があります。許容できる欠損値比率の閾値を指定して、欠損値が多すぎる特徴量をフィルタリングできます。
欠損値比率を特徴量選択に使用するには、次の手順に従います。
- 各特徴量の欠損値比率を、データセットの総インスタンス数で欠損値の数を割って計算します。
- 許容できる欠損値比率の閾値(たとえば、最大80%の値が欠損している場合は、80%以下の欠損値比率を持つ特徴量のみを考慮する)を設定します。
- 閾値を超える欠損値比率を持つ特徴量をフィルタリングします。
1.2 ラッパーベースのアプローチ
ラッパーベースの特徴量選択アプローチでは、特定の機械学習アルゴリズムを使用して特徴量の重要性を評価します。さまざまな特徴量の組み合わせを試行し、選択した手法でのパフォーマンスを評価することで、最適な特徴量のサブセットを探します。
使用可能な特徴量サブセットの数が非常に多いため、高次元のデータセットで作業する場合、ラッパーベースのアプローチは計算上のコストが高くなることがあります。
ただし、フィルターベースのアプローチよりも特徴量と学習アルゴリズムの関係を考慮するため、しばしば優れたパフォーマンスを発揮します。
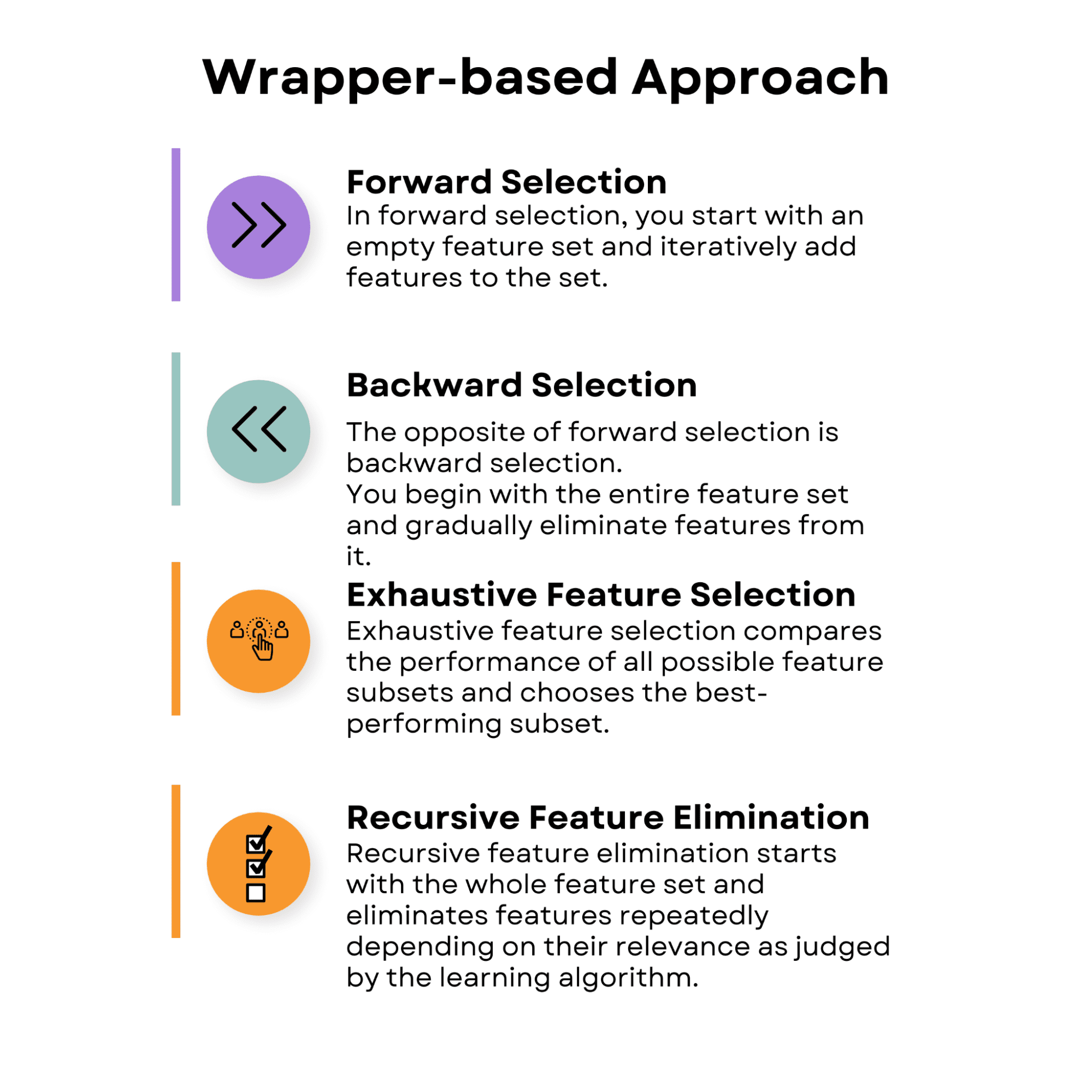
前向き選択
前向き選択では、空の特徴量セットから始めて、順次特徴量を追加していきます。各ステップで、現在の特徴量セットと追加の特徴量でモデルのパフォーマンスを評価します。パフォーマンスの改善が最も大きい特徴量がセットに追加されます。
プロセスは、性能の改善が見られなくなるか、あらかじめ定義された特徴量の数に達するまで続きます。
以下のコードは、ラッパーベースの教師あり特徴量選択技術である前向き選択の適用を示しています。
この例では、sklearnライブラリから乳がんデータセットを使用します。乳がんデータセットは、ウィスコンシン診断乳がん(WDBC)データセットとしても知られており、分類のためによく使われる事前に構築されたデータセットです。そして、ここでは、乳がんを悪性(がん)または良性(非がん)と診断する予測モデルを構築することが主な目的です。
モデルのために、性能がどのように変化するかを見るために、異なる数の特徴量を選択しますが、まずはライブラリ、データセット、変数をロードしましょう。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 乳がんデータセットをロードする
data = load_breast_cancer()
# データセットを特徴量とターゲットに分割する
X = data.data
y = data.targetこのコードの目的は、指定された評価指標に基づいてモデルの性能を向上させる特徴量の最適なサブセットを特定することです。この手法は、空の特徴量セットから始まり、指定された評価指標に基づいて、モデルの性能を向上させる特徴量を反復的に追加することから始まります。この場合、使用されるメトリックは正確度です。
次のコードでは、mlxtendライブラリのSequentialFeatureSelectorを使用して、前向き選択を実行します。これは、ロジスティック回帰モデル、望ましい特徴量の数、および5つの交差検証で構成されています。前向き選択オブジェクトはトレーニングデータに適合し、選択された特徴量が表示されます。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 乳がんデータセットをロードする
data = load_breast_cancer()
# データセットを特徴量とターゲットに分割する
X = data.data
y = data.target
# データセットをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# ロジスティック回帰モデルを定義する
model = LogisticRegression()
# 前向き選択オブジェクトを定義する
sfs = SFS(model,
k_features=5,
forward=True,
floating=False,
scoring='accuracy',
cv=5)
# トレーニングセットで前向き選択を実行する
sfs.fit(X_train, y_train)さらに、選択された特徴量のパフォーマンスをテストセットで評価し、線グラフで異なる特徴量サブセットのモデルのパフォーマンスを視覚化する必要があります。
グラフは、特徴量の数の関数として交差検証された正確度を示し、モデルの複雑さと予測性能のトレードオフについて洞察を提供します。
出力とグラフを分析することで、モデルに含める最適な特徴量の数を決定し、最終的にパフォーマンスを向上させ、過剰適合を減らすことができます。
# 選択された特徴量を表示する
print('Selected Features:', sfs.k_feature_names_)
# 選択された特徴量のパフォーマンスをテストセットで評価する
accuracy = sfs.k_score_
print('Accuracy:', accuracy)
# 異なる特徴量サブセットでのモデルのパフォーマンスをプロットする
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df['avg_score'] = sfs_df['avg_score'].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind='line', y='avg_score', ax=ax)
ax.set_xlabel('Number of Features')
ax.set_ylabel('Accuracy')
ax.set_title('Forward Selection Performance')
plt.show()以下は、全体のコードです。
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 乳がんデータセットをロードする
data = load_breast_cancer()
# データセットを特徴量とターゲットに分割する
X = data.data
y = data.target
# データセットをトレーニングセットとテストセットに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# ロジスティック回帰モデルを定義する
model = LogisticRegression()
# 前向き選択オブジェクトを定義する
sfs = SFS(model, k_features=5, forward=True, floating=False, scoring="accuracy", cv=5)
# トレーニングセットで前向き選択を実行する
sfs.fit(X_train, y_train)
# 選択された特徴量を表示する
print("Selected Features:", sfs.k_feature_names_)
# 選択された特徴量のパフォーマンスをテストセットで評価する
accuracy = sfs.k_score_
print("Accuracy:", accuracy)
# 異なる特徴量サブセットでのモデルのパフォーマンスをプロットする
sfs_df = pd.DataFrame.from_dict(sfs.get_metric_dict()).T
sfs_df["avg_score"] = sfs_df["avg_score"].astype(float)
fig, ax = plt.subplots()
sfs_df.plot(kind="line", y="avg_score", ax=ax)
ax.set_xlabel("Number of Features")
ax.set_ylabel("Accuracy")
ax.set_title("Forward Selection Performance")
plt.show()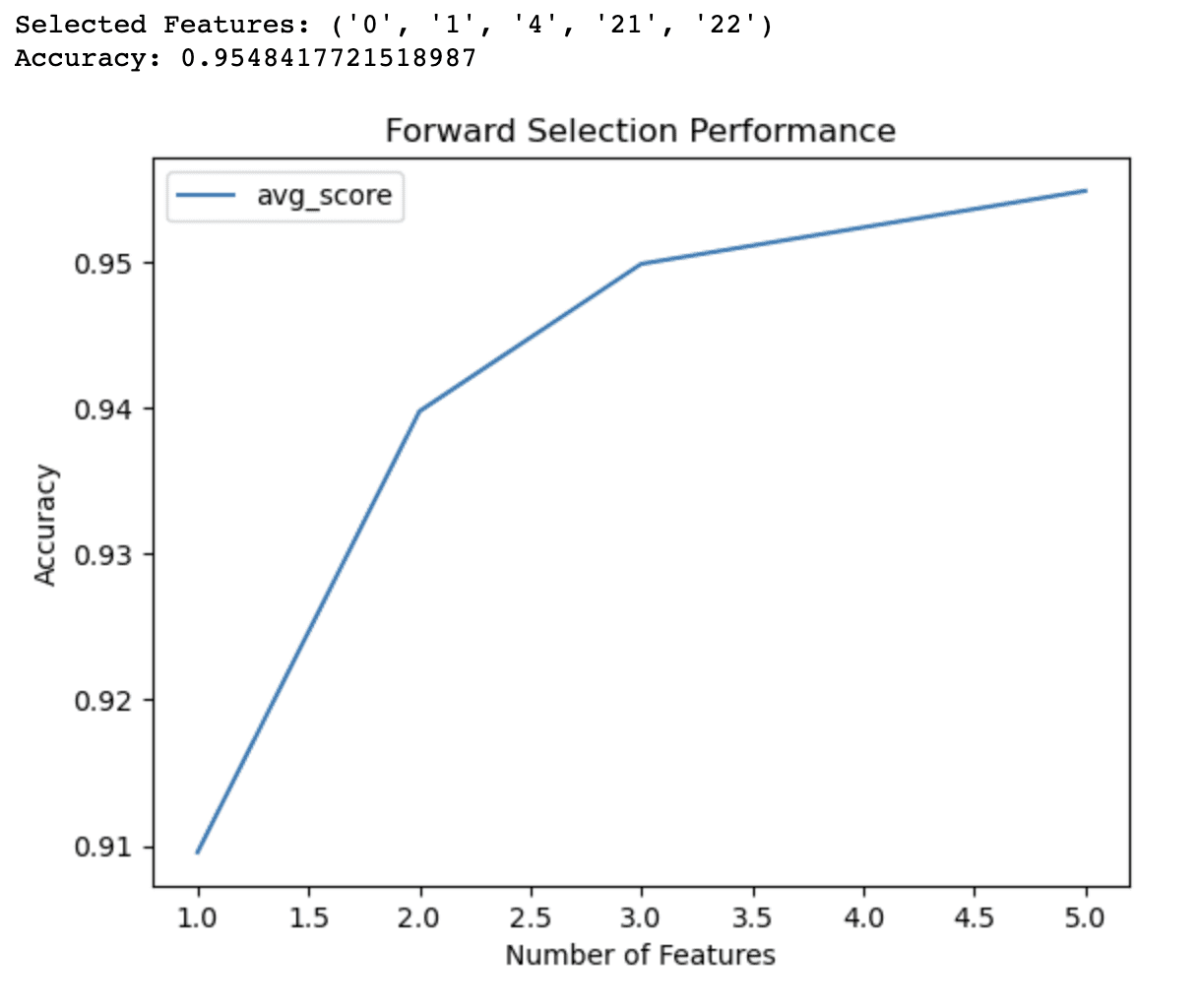
フォワード選択の出力により、乳がんデータセット上のロジスティック回帰モデルに対して最高の精度(0.9548)をもたらす5つの特徴量のサブセットが識別されたことが示されます。これらの選択された特徴量は、そのインデックスによって識別されます: 0、1、4、21、22。
ライングラフは、異なる特徴量の数でのモデルのパフォーマンスに関する追加の洞察を提供します。これにより、以下のことが示されます:
- 1つの特徴量だけで、モデルは約91%の精度を達成します。
- 2番目の特徴量を追加すると、精度が94%に向上します。
- 3つの特徴量で、精度はさらに95%に向上します。
- 4つの特徴量を含めると、精度がわずかに95%を超えます。
4つ以上の特徴量を使用すると、精度の改善は無視できるほどになります。この情報は、モデルの複雑さと予測性能のトレードオフに関する明確な判断を下すのに役立ちます。これらの結果に基づいて、精度と単純さのバランスを取るためにモデルに3つまたは4つの特徴量のみを使用することを決定するかもしれません。
逆選択
逆選択は、フォワード選択の反対です。全体の特徴量セットから始め、徐々に特徴量を削除していきます。
各フェーズで、削除される特徴量を除いた現在の特徴量セットでモデルのパフォーマンスを測定します。
性能低下が最も少ない特徴量がセットから除外されます。
この手順は、性能の実質的な増加がなくなるか、あらかじめ設定された特徴量数に達するまで繰り返されます。
逆選択とフォワード選択は、逐次特徴量選択として分類されます。ここで詳細を学ぶことができます。
網羅的特徴量選択
網羅的特徴量選択は、すべての可能な特徴量のサブセットのパフォーマンスを比較し、最もパフォーマンスの良いサブセットを選択します。このアプローチは、大規模なデータセットの場合には計算量が多くなりますが、最適な特徴量サブセットを保証します。
再帰的特徴量削減
再帰的特徴量削減は、学習アルゴリズムによって判断される特徴量の関連性に応じて、全体の特徴量セットから開始し、特徴量を繰り返し削除していきます。最も重要でない特徴量が各ステップで削除され、モデルが再学習されます。この手法は、あらかじめ決定された特徴量数に達するまで繰り返されます。
1.3 埋め込みアプローチ
埋め込み特徴量選択アプローチには、学習アルゴリズムの一部として特徴量選択プロセスが含まれます。
これは、トレーニングフェーズ全体で、学習アルゴリズムがモデルパラメータを最適化するだけでなく、最も重要な特徴を選択することを意味します。埋め込み方法は、外部の特徴量選択手順を必要としないため、ラッパー方法よりも効果的である場合があります。
 Image by Author
Image by Author
正則化
正則化は、機械学習モデルの過学習を防止するために損失関数にペナルティ項を追加する方法です。
ラッソ(L1正則化)やリッジ(L2正則化)などの正則化手法は、重要でない特徴量の係数をゼロに近づけるために特徴量選択と組み合わせて使用することができます。
ランダムフォレストの重要性
ランダムフォレストは、複数の決定木の予測を組み合わせるアンサンブル学習手法です。ランダムフォレストは、ツリー構築プロセスの一部として各特徴量の重要性スコアを計算し、関連性に基づいて特徴量を順序付けるために使用することができます。モデルは、より高い重要性評価を持つ特徴をより重要と見なします。
ランダムフォレストについて詳しく学びたい場合は、こちらの記事「決定木とランダムフォレストアルゴリズム」を参照してください。
以下の例では、異なる森林のタイプに関する情報が含まれるCovertypeデータセットを使用しています。
Covertypeデータセットの目的は、北コロラドのルーズベルト国立森林内の森林被覆タイプ(支配的な樹種)を予測することです。
以下のコードの主な目的は、ランダムフォレスト分類器を使用して特徴量の重要性を決定することです。各特徴量が全体的な分類パフォーマンスにどの程度貢献しているかを評価することで、この方法は、予測モデルを構築するための最も関連性の高い特徴量を特定するのに役立ちます。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Covertypeデータセットを読み込む
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz", header=None)
# カラム名を割り当てる
cols = ["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology",
"Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways",
"Hillshade_9am", "Hillshade_Noon", "Hillshade_3pm",
"Horizontal_Distance_To_Fire_Points"] + ["Wilderness_Area_"+str(i) for i in range(1,5)] + ["Soil_Type_"+str(i) for i in range(1,41)] + ["Cover_Type"]
data.columns = colsまず、ランダムフォレスト分類器オブジェクトを作成し、トレーニングデータに適合させます。トレーニング済みモデルから特徴の重要度を抽出し、重要度スコアに基づいて上位10の特徴が選択され、ランキングで表示されます。
# データセットをトレーニングセットとテストセットに分割
X_train、X_test、y_train、y_test = train_test_split(X、y、test_size = 0.3、random_state = 42)
# ランダムフォレスト分類器オブジェクトを作成
rfc = RandomForestClassifier(n_estimators = 100、random_state = 42)
# トレーニングデータにモデルを適合
rfc.fit(X_train、y_train)
# トレーニング済みモデルから特徴の重要度を取得
importances = rfc.feature_importances_
# 特徴の重要度を降順でソート
indices = np.argsort(importances)[:: -1]
# 上位10の特徴を選択
num_features = 10
top_indices = indices [: num_features]
top_importances = importances [top_indices]
# 上位10の特徴ランキングを表示
print("上位10の特徴ランキング:")
for f in range(num_features):# 10の代わりにnum_featuresを使用
print(f"{f + 1}。{X_train.columns [indices [f]]}:{importances [indices [f]]} ")さらに、コードは上位10の特徴の重要度を水平バーチャートで視覚化します。
# 上位10の特徴の重要度を水平バーチャートでプロット
plt.barh(range(num_features)、top_importances、align ='center')
plt.yticks(range(num_features)、X_train.columns [top_indices])
plt.xlabel("特徴の重要度")
plt.ylabel("特徴")
plt.show()この視覚化により、重要度スコアを簡単に比較し、分析から含めるか除外するかを決定するための情報を提供することができます。
出力とチャートを調べることで、予測モデルに最も関連性の高い特徴を選択し、パフォーマンスを向上させ、過剰適合を減らし、トレーニング時間を短縮することができます。
以下が全体のコードです。
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Covertypeデータセットをロード
data = pd.read_csv(
"https://archive.ics.uci.edu/ml/machine-learning-databases/covtype/covtype.data.gz",
header=None,
)
# 列名を割り当てる
cols = (
[
"標高",
"方位",
"傾斜",
"水平距離_水道",
"垂直距離_水道",
"水平距離_道路",
"日陰_午前9時",
"日陰_正午",
"日陰_午後3時",
"水平距離_火災ポイント",
]
+ ["野生エリア_" + str(i) for i in range(1, 5)]
+ ["土壌タイプ_" + str(i) for i in range(1, 41)]
+ ["被覆タイプ"]
)
data.columns = cols
# データセットを特徴とターゲットに分割
X = data.iloc [:、-1]
y = data.iloc [:、-1]
# データセットをトレーニングセットとテストセットに分割
X_train、X_test、y_train、y_test = train_test_split(
X、y、test_size = 0.3、random_state = 42
)
# ランダムフォレスト分類器オブジェクトを作成
rfc = RandomForestClassifier(n_estimators = 100、random_state = 42)
# トレーニングデータにモデルを適合
rfc.fit(X_train、y_train)
# トレーニング済みモデルから特徴の重要度を取得
importances = rfc.feature_importances_
# 特徴の重要度を降順でソート
indices = np.argsort(importances)[:: -1]
# 上位10の特徴を選択
num_features = 10
top_indices = indices [: num_features]
top_importances = importances [top_indices]
# 上位10の特徴ランキングを表示
print("上位10の特徴ランキング:")
for f in range(num_features):# 10の代わりにnum_featuresを使用
print(f"{f + 1}。{X_train.columns [indices [f]]}:{importances [indices [f]]} ")
# 上位10の特徴の重要度を水平バーチャートでプロット
plt.barh(range(num_features)、top_importances、align ="center")
plt.yticks(range(num_features)、X_train.columns [top_indices])
plt.xlabel("特徴の重要度")
plt.ylabel("特徴")
plt.show()以下が出力です。
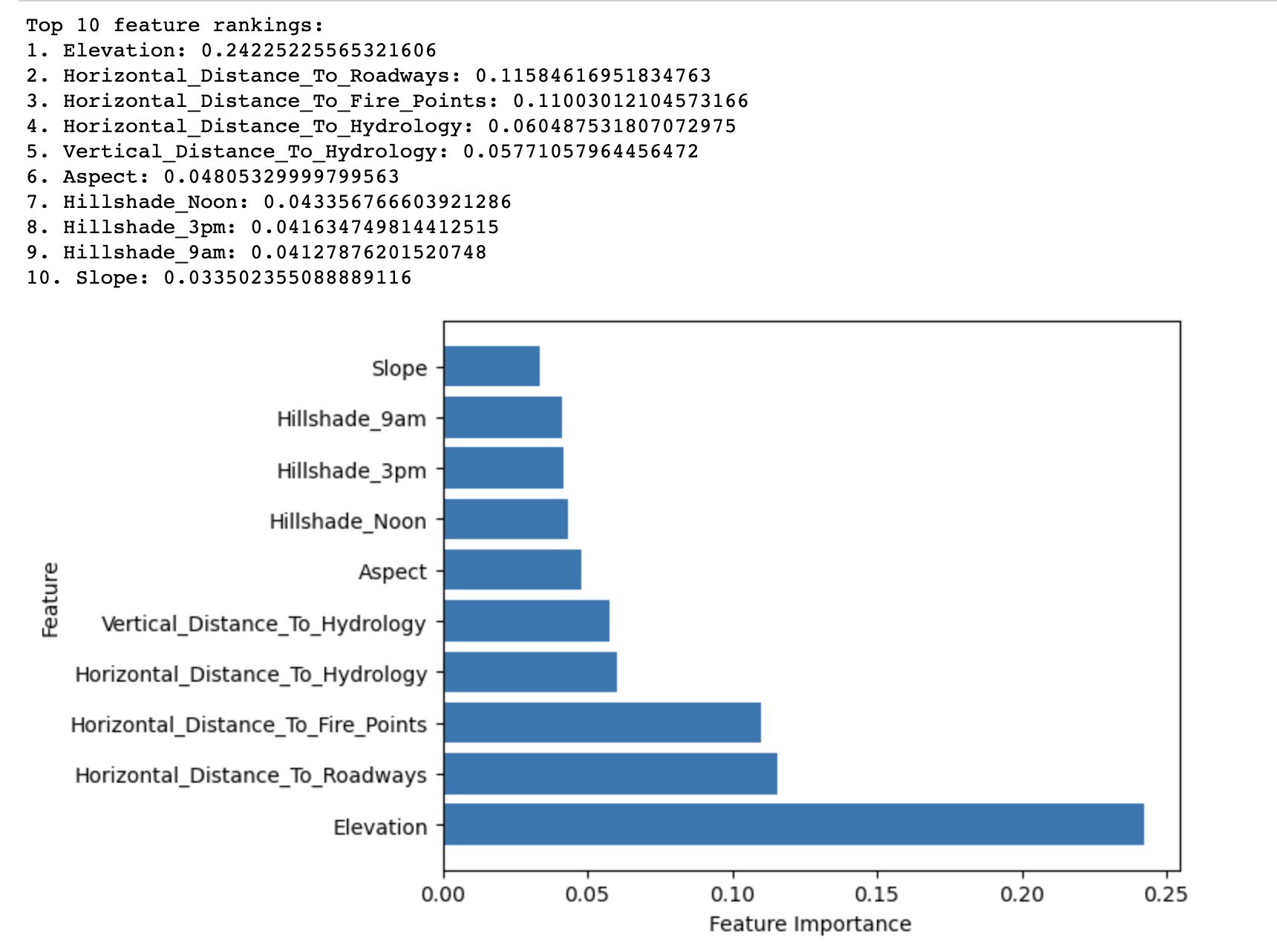
ランダムフォレスト重要度法の出力は、Covertypeデータセットでの森林被覆タイプの予測において、上位10の重要な特徴量が重要度に基づいてランク付けされたものが表示されます。
これにより、標高が森林被覆タイプを予測する上で最も重要なスコア(0.2423)を持つことが明らかになります。これは、ローズベルト国立森林の主要な樹種を決定するために標高が重要な役割を果たしていることを示唆しています。
その他の重要度スコアが比較的高い特徴には、道路への水平距離(0.1158)および火災発生地点への水平距離(0.1100)が含まれます。これらは、道路や火災発生地点への近接が森林被覆タイプにも大きな影響を与えることを示しています。
上位10のリストに残った特徴は、重要度スコアが比較的低いですが、モデルの全体的な予測性能に寄与しています。これらの特徴は、主に水文学的要因、傾斜、方位、および山影指数に関連しています。
要約すると、結果はローズベルト国立森林における森林被覆タイプの分布に影響を与える最も重要な要因を強調し、森林被覆タイプ分類のより効果的かつ効率的な予測モデルの構築に役立ちます。
2. 非教師あり特徴量選択手法
ターゲット変数が利用できない場合、非教師あり特徴量選択手法を使用して、データセットの次元を削減しながら、その基本構造を保持することができます。これらの手法には、初期の特徴空間をデータ内の多くの変動を捉えるように変更する新しい低次元空間に変換することが含まれます。
 Image by Author
Image by Author
2.1 主成分分析(PCA)
PCAは、元の特徴空間を主成分によって定義される新しい直交空間に変換する線形次元削減法です。これらの成分は、データ内の最高レベルの分散を捉えるように選択された元の特徴量の線形結合です。
PCAは、最も多くの変動を表す上位k個の主成分を選択することで、データセットの次元を下げることができます。
これが実際にどのように機能するかを示すために、Wineデータセットを使用して作業します。これは、イタリアの同じ地域から出荷された3つの異なる品種からの異なるワインを表す178のサンプルから構成される、機械学習の分類および特徴選択タスクで広く使用されているデータセットです。
Wineデータセットを使用する目的は、その化学特性に基づいてワインサンプルを3つの品種の1つに正確に分類できる予測モデルを構築することです。
次のコードは、非教師あり特徴量選択手法である主成分分析(PCA)をWineデータセットに適用する方法を示しています。
これらの成分(主成分)は、データ内の最も多くの分散を捉えながら情報損失を最小限に抑えます。
コードは、異なるワインの化学特性を説明する13の特徴量で構成されるWineデータセットをロードすることから始まります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Wineデータセットをロードする
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_namesこれらの特徴量は、PCAが入力特徴量の異なるスケールに影響を受けないようにするために、StandardScalerを使用して標準化されます。
# 特徴量を標準化する
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)次に、PCAがsklearn.decompositionモジュールのPCAクラスを使用して標準化されたデータ上で実行されます。
# PCAを実行する
pca = PCA()
X_pca = pca.fit_transform(X_scaled)各主成分の説明された分散比を計算し、各成分がデータ内の合計分散のどの程度を説明するかを示します。
# 説明された分散比を計算する
explained_variance_ratio = pca.explained_variance_ratio_最後に、説明された分散比と主成分による累積説明された分散を可視化するために2つのプロットが生成されます。
最初のプロットは、各個々の主成分ごとの説明された分散比を示し、2番目のプロットは、より多くの主成分が含まれるにつれて累積説明された分散がどのように増加するかを示しています。
これらのプロットにより、次元削減と情報の保持のトレードオフをバランスしながら、モデルで使用する最適な主成分数を決定するのに役立ちます。
# 2x1のグリッドのサブプロットを作成する
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# 1番目のサブプロットに説明された分散比をプロットする
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel('主成分')
ax1.set_ylabel('説明された分散比')
ax1.set_title('主成分ごとの説明された分散比')
# 累積説明された分散を計算する
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# 2番目のサブプロットに累積説明された分散をプロットする
ax2.plot(range(1, len(cumulative_explained_variance) + 1), cumulative_explained_variance, marker='o')
ax2.set_xlabel('主成分の数')
ax2.set_ylabel('累積説明された分散')
ax2.set_title('主成分による累積説明された分散')
# 図を表示する
plt.tight_layout()
plt.show()全体のコードを見てみましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# ワインデータセットをロードします
wine = load_wine()
X = wine.data
y = wine.target
feature_names = wine.feature_names
# 特徴量を標準化します
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCAを実行します
pca = PCA()
X_pca = pca.fit_transform(X_scaled)
# 説明された分散比を計算します
explained_variance_ratio = pca.explained_variance_ratio_
# 2x1のサブプロットグリッドを作成します
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16, 8))
# 最初のサブプロットに説明された分散比をプロットします
ax1.bar(range(1, len(explained_variance_ratio) + 1), explained_variance_ratio)
ax1.set_xlabel("主成分")
ax1.set_ylabel("説明された分散比")
ax1.set_title("主成分による説明された分散比")
# 累積説明された分散を計算します
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
# 2番目のサブプロットに累積説明された分散をプロットします
ax2.plot(
range(1, len(cumulative_explained_variance) + 1),
cumulative_explained_variance,
marker="o",
)
ax2.set_xlabel("主成分の数")
ax2.set_ylabel("累積説明された分散")
ax2.set_title("主成分による累積説明された分散")
# 図を表示します
plt.tight_layout()
plt.show()以下は出力結果です。
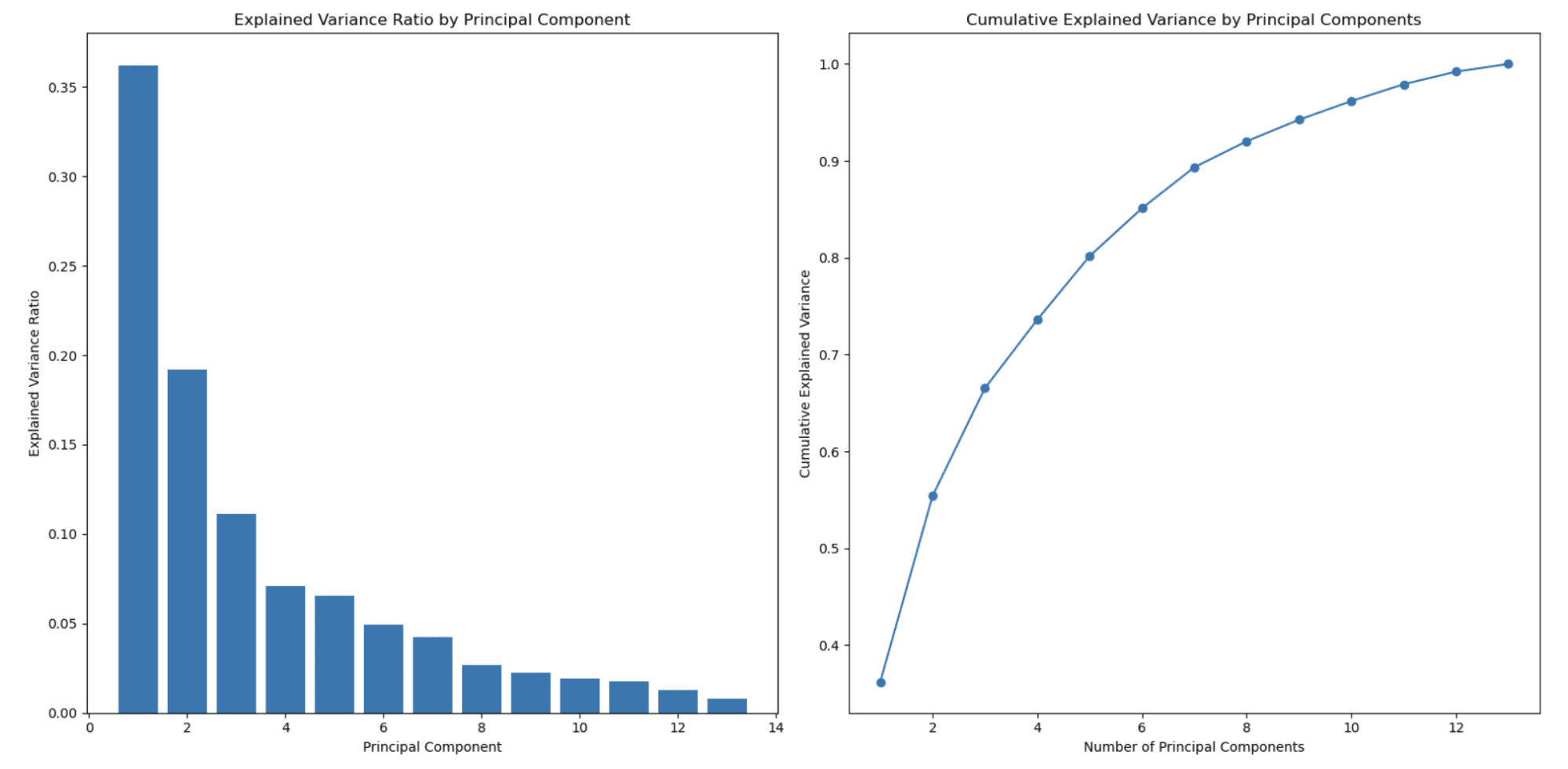
左側のグラフは、主成分の数が増加するにつれて説明された分散比が減少することを示しています。これは、主成分が説明する分散量に従って順序付けられるため、PCAで典型的に観察される動作です。
最初の主成分(特徴)は最も多くの分散をキャプチャし、2番目の主成分は次に多くの分散をキャプチャし、以降も同様になります。その結果、各主成分について説明された分散比は次第に減少します。
これは、PCAが次元削減に使用される主要な理由の1つです。
右側の2番目のグラフは、累積説明された分散を示しており、どの程度の主成分(特徴)を選択すればデータのパーセンテージを表現できるかを決定するのに役立ちます。x軸は主成分の数を、y軸は累積説明された分散を示しています。x軸を移動すると、その数の主成分を含めた場合にどれだけの総分散が維持されるかがわかります。
この例では、主成分を約3または4選択すると、総分散の80%以上がキャプチャされ、約8つの主成分を選択すると総分散の90%以上がキャプチャされることがわかります。
主成分の数は、次元削減と維持したい分散のトレードオフに基づいて選択できます。
この例では、Sci-kitを使用してPCAを適用したため、ここで公式ドキュメントを見つけることができます。
2.2 独立成分分析(ICA)
ICAは、多次元信号をその成分に分割する方法です。
特徴選択の文脈では、ICAを使用して元の特徴空間を、統計的に独立した成分で特徴づけられる新しい空間に変換することができます。トップkの独立成分を選択することで、データセットの次元を減らすことができます。
2.3 非負値行列因子分解(NMF)
非負値行列因子(NMF)は、非負のデータ行列を2つの低次元非負の行列の積として近似する次元削減手法です。
特徴選択の文脈では、NMFを使用して、元のデータの重要な構造を捉える新しい基本的な特徴のセットを抽出することができます。トップkの基底特徴を選択することで、データセットの次元を最小限に抑えることができます。
2.4 t分布確率的近傍埋め込み(t-SNE)
t-SNEは、高次元と低次元の場所のペアワイズ確率分布の差を減らすことにより、データセットの構造を保持しようとする非線形次元削減手法です。
特徴選択において、t-SNEを適用することで、元の特徴空間をデータの構造を保持する低次元空間に投影することができ、視覚化や評価が向上します。
「Unsupervised Learning Algorithms」について、より詳しい情報を見つけることができます。
2.5 オートエンコーダー
オートエンコーダーは、入力データを低次元表現にエンコードし、元のバージョンに戻すことを学習する、一種の人工ニューラルネットワークです。オートエンコーダーの低次元表現は、元のデータの潜在的な構造を捉えた別の特徴量を生成するために使用できます。
最後に
機械学習において、特徴量選択は重要です。データの次元を削減し、過学習のリスクを最小化し、モデルの全体的なパフォーマンスを改善するのに役立ちます。適切な特徴量選択方法を選択するには、特定の問題、データセット、およびモデリング要件を考慮する必要があります。
本記事では、フィルターベース、ラッパーベース、および埋め込みアプローチなどの教師あり手法を含む、広範な特徴量選択技術について説明しました。
主成分分析(PCA)、独立成分分析(ICA)、非負値行列因子分解(NMF)、t-SNE、オートエンコーダーなどの教師なし技術は、ターゲット変数を考慮せずに次元を削減するためにデータの潜在的な構造に焦点を当てます。
モデルに適切な特徴量選択方法を選択する際には、データの特性、各技術の潜在的な仮定、および関連する計算複雑度を考慮することが重要です。
適切な特徴量選択技術を慎重に選択および適用することにより、パフォーマンスを大幅に向上させ、より優れた洞察と意思決定を実現することができます。Nate Rosidiは、データサイエンティストであり、製品戦略に携わっています。また、分析を教える非常勤講師であり、StrataScratchの創設者でもあります。StrataScratchは、トップ企業からの実際のインタビュー質問を使って、データサイエンティストが面接に備えるのを支援するプラットフォームです。Twitter:StrataScratchまたはLinkedInで彼とつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






