DeepSpeedを使用してPyTorchを加速し、Intel Habana GaudiベースのDL1 EC2インスタンスを使用して大規模言語モデルをトレーニングします
Using DeepSpeed to accelerate PyTorch and training large language models using Intel Habana Gaudi-based DL1 EC2 instances.
数十億のパラメータを持つ大規模言語モデル(LLM)のトレーニングは、挑戦的なものとなることがあります。モデルアーキテクチャを設計するだけでなく、混合精度サポート、勾配蓄積、およびチェックポイントなどの分散トレーニングの最新のトレーニング技術を設定する必要があります。大規模なモデルでは、トレーニングセットアップはさらに難しくなります。単一のアクセラレータデバイスの利用可能なメモリは、データ並列処理のみを使用してトレーニングされたモデルのサイズを制限し、モデル並列トレーニングを使用する場合は、トレーニングコードの追加レベルの修正が必要になります。DeepSpeed(PyTorch用のオープンソースの深層学習最適化ライブラリ)などのライブラリは、これらの課題のいくつかを解決し、モデルの開発とトレーニングを加速するのに役立ちます。
この記事では、Intel Habana GaudiベースのAmazon Elastic Compute Cloud(Amazon EC2)DL1インスタンスでのトレーニングをセットアップし、DeepSpeedなどのスケーリングフレームワークを使用する利点を定量化します。エンコーダタイプのトランスフォーマーモデル(340万〜150億のパラメータを持つBERT)のスケーリング結果を示します。 150億パラメータのモデルでは、DeepSpeed ZeROステージ1最適化を使用して、128のアクセラレータ(16個のdl1.24xlargeインスタンス)全体でスケーリング効率が82.7%に達しました。オプティマイザーステートは、データ並列パラダイムを使用して大規模モデルをトレーニングするために DeepSpeed によってパーティション化されました。このアプローチは、データ並列処理を使用して500億パラメータのモデルをトレーニングするために拡張されました。また、GaudiはBF16データ型のネイティブサポートを使用して、メモリサイズを縮小し、FP32データ型を使用する場合よりもトレーニングパフォーマンスを向上させました。その結果、wikicorpus-enデータセットを使用してBERT 150億パラメータモデルの事前トレーニング(フェーズ1)の収束を16時間以内に達成しました(大規模なモデルを1日以内にトレーニングすることが目標でした)。
トレーニングセットアップ
AWS Batchを使用して構成された16個のdl1.24xlargeインスタンスからなるマネージドコンピュートクラスタをプロビジョニングしました。AWS Batchワークショップを開発して、AWS Batchで分散トレーニングクラスタをセットアップする手順を説明します。各dl1.24xlargeインスタンスには、32 GBのメモリを持つHabana Gaudiアクセラレータが8つあり、カード間のトータルバイダイレクショナル相互接続帯域幅が700 Gbps(詳細についてはAmazon EC2 DL1インスタンスの深堀りを参照)のフルメッシュRoCEネットワークがあります。dl1.24xlargeクラスタは、4つのAWS Elastic Fabric Adapter(EFA)も使用し、ノード間の合計帯域幅が400 Gbpsです。
分散トレーニングワークショップでは、AWS Batchを使用して分散トレーニングクラスタをセットアップする手順を説明します。ワークショップでは、完全に管理されたクラスタ上で大規模なコンテナ化されたトレーニングジョブを起動するためのマルチノード並列ジョブ機能に焦点を当てて説明します。より具体的には、完全に管理されたAWS Batchコンピューティング環境がDL1インスタンスで作成されます。コンテナはAmazon Elastic Container Registry(Amazon ECR)からプルされ、マルチノード並列ジョブ定義に基づいてクラスタ内のインスタンスに自動的に起動されます。ワークショップは、PyTorchとDeepSpeedを使用したマルチノード、マルチHPUデータ並列トレーニングを実行して終了します。
DeepSpeedによるBERT 1.5Bの事前トレーニング
Habana SynapseAI v1.5およびv1.6は、DeepSpeed ZeRO1最適化をサポートしています。 HabanaのDeepSpeed GitHubリポジトリのフォークには、Gaudiアクセラレータをサポートするために必要な変更が含まれています。分散データ並列(マルチカード、マルチインスタンス)、ZeRO1最適化、BF16データ型に完全に対応しています。
これらのすべての機能は、48層、1600隠れ層、25ヘッドの双方向エンコーダモデルを導出したBERT実装から派生したBERT 1.5Bモデルリファレンスリポジトリで有効になっています。リポジトリには、ベースラインとなるBERT Largeモデル実装も含まれています:24層、1024隠れ層、16ヘッド、340万パラメータのニューラルネットワークアーキテクチャ。事前トレーニングモデリングスクリプトは、wikicorpus_enデータをダウンロードし、生データをトークンに前処理し、データをより小さなh5データセットに分割して分散データ並列トレーニングに使用するために、NVIDIAのDeep Learning Examplesリポジトリから派生しています。 DL1インスタンスを使用して、カスタムのPyTorchモデルアーキテクチャを使用して、データセットを使用してトレーニングするために、この一般的なアプローチを採用できます。
事前トレーニング(フェーズ1)のスケーリング結果
大規模なモデルをスケールアップして事前トレーニングする場合、トレーニング時間と完全に収束したソリューションに到達するためのコスト効果に主に焦点を当てました。次に、BERT 1.5Bの事前トレーニングに関するこれら2つのメトリックスについて詳しく説明します。
パフォーマンスとトレーニング時間のスケーリング
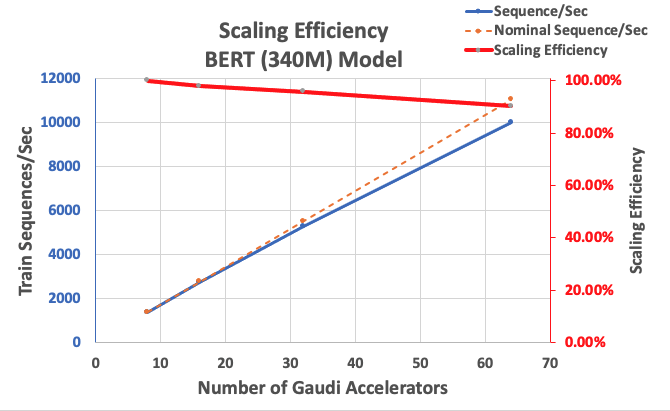
BERT Largeの実装のパフォーマンスをスケーラビリティのベースラインとして測定を開始します。以下の表は、1-8 dl1.24xlargeインスタンス(1インスタンスあたり8つのアクセラレータデバイス)からの秒あたりシーケンスの測定スループットを示しています。単一インスタンスのスループットをベースラインとして使用し、複数インスタンスでのスケーリング効率を測定しました。これは、価格パフォーマンストレーニングメトリックを理解するための重要なレバーです。
| インスタンス数 | アクセラレータ数 | 秒あたりシーケンス数 | アクセラレータあたりの秒あたりシーケンス数 | スケーリング効率 |
| 1 | 8 | 1,379.76 | 172.47 | 100.0% |
| 2 | 16 | 2,705.57 | 169.10 | 98.04% |
| 4 | 32 | 5,291.58 | 165.36 | 95.88% |
| 8 | 64 | 9,977.54 | 155.90 | 90.39% |
以下の図は、スケーリング効率を示しています。
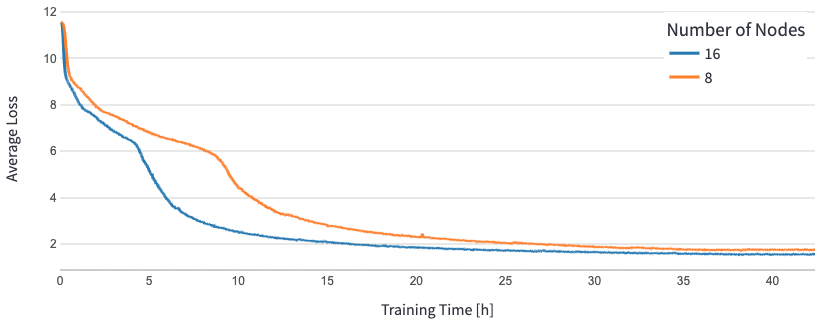
BERT 1.5Bでは、モデルのハイパーパラメータを変更して収束を保証しました。アクセラレータあたりの効果的なバッチサイズは384に設定され、マイクロバッチはステップあたり16、勾配蓄積は24回となりました。8ノードでは学習率0.0015、16ノードでは0.003を使用しました。これらの設定で、8 dl1.24xlargeインスタンス(64アクセラレータ)でBERT 1.5Bのフェーズ1のプレトレーニングを約25時間、16 dl1.24xlargeインスタンス(128アクセラレータ)で15時間で収束させました。以下の図は、アクセラレータの数を拡大するにつれて、トレーニングエポック数の平均損失を示しています。
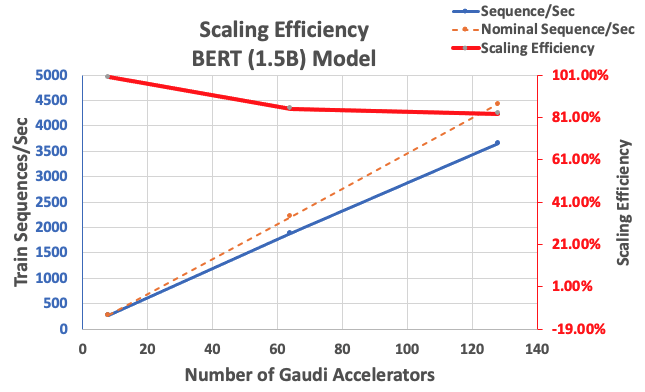
前述の設定で、単一インスタンスの8アクセラレータをベースラインとして、64アクセラレータで85%、128アクセラレータで83%のスケーリング効率を達成しました。以下の表は、パラメータをまとめたものです。
| インスタンス数 | アクセラレータ数 | 秒あたりシーケンス数 | アクセラレータあたりの秒あたりシーケンス数 | スケーリング効率 |
| 1 | 8 | 276.66 | 34.58 | 100.0% |
| 8 | 64 | 1,883.63 | 29.43 | 85.1% |
| 16 | 128 | 3,659.15 | 28.59 | 82.7% |
以下の図は、スケーリングの効率性を示しています。
結論
この投稿では、DeepSpeedのサポートをHabana SynapseAI v1.5/v1.6で評価し、それがHabana Gaudiアクセラレータ上でLLMトレーニングのスケーリングにどのように役立つかを評価しました。 15億パラメータのBERTモデルの事前トレーニングには、128のGaudiアクセラレータのクラスターで収束するのに16時間かかり、強いスケーリング率は85%でした。 AWSのワークショップで示されたアーキテクチャを参照し、DL1インスタンスを使用してカスタムPyTorchモデルアーキテクチャをトレーニングすることを検討していただくことをお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






