Amazon AIコンテンツモデレーションサービスを使用した安全な画像生成と拡散モデル
'安全な画像生成と拡散モデル using Amazon AIコンテンツモデレーションサービス'
生成AI技術は急速に改善しており、テキスト入力に基づいてテキストや画像を生成することが可能になりました。Stable Diffusionはテキストから画像を生成するモデルであり、Amazon SageMaker JumpStartを通じてStable Diffusionモデルを使用して簡単に画像を生成することができます。
以下は、Stable Diffusionによって生成された入力テキストと対応する出力画像の例です。入力は「テーブルの上で踊るボクサー」、「水着姿のビーチで泳ぐ女性、水彩スタイル」、「スーツを着た犬」です。

生成AIソリューションは強力で便利ですが、操作や悪用にも弱い場合があります。画像生成に使用する顧客は、ユーザー、プラットフォーム、ブランドの保護のため、強力なモデレーション手法を実装し、安全でポジティブなユーザーエクスペリエンスを作りながら、プラットフォームとブランドの評判を守るために、コンテンツモデレーションを優先する必要があります。
この記事では、AWS AIサービスであるAmazon RekognitionとAmazon Comprehendを使用し、近リアルタイムでStable Diffusionモデルが生成したコンテンツを効果的にモデレートする方法を探ります。AWS上でStable Diffusionモデルを起動し、テキストから画像を生成する方法については、「Amazon SageMaker JumpStartで安定した拡散モデルを使用してテキストから画像を生成する」を参照してください。
ソリューションの概要
Amazon RekognitionとAmazon Comprehendは、APIインターフェースを介して事前トレーニングされたカスタマイズ可能なMLモデルを提供するマネージドAIサービスです。Amazon Rekognition Content Moderationは、画像とビデオのモデレーションを自動化し効率化します。Amazon Comprehendは、テキストを分析し、価値ある洞察と関係性を明らかにするためにMLを利用します。
以下のリファレンスは、近リアルタイムでStable Diffusionテキストから画像モデルが生成した画像をモデレートするためのRESTfulプロキシAPIの作成を示しています。このソリューションでは、JumpStartを使用してStable Diffusionモデル(v2-1ベース)を起動および展開しました。ソリューションでは、ネガティブプロンプトとテキストモデレーションソリューション(Amazon Comprehendやルールベースのフィルタなど)を使用して、入力プロンプトをモデレートしています。また、生成された画像をモデレートするためにAmazon Rekognitionも利用しています。RESTful APIは、以前の手順でプロンプトまたは生成された画像に不適切な情報が検出された場合に、生成された画像とモデレーションの警告をクライアントに返します。
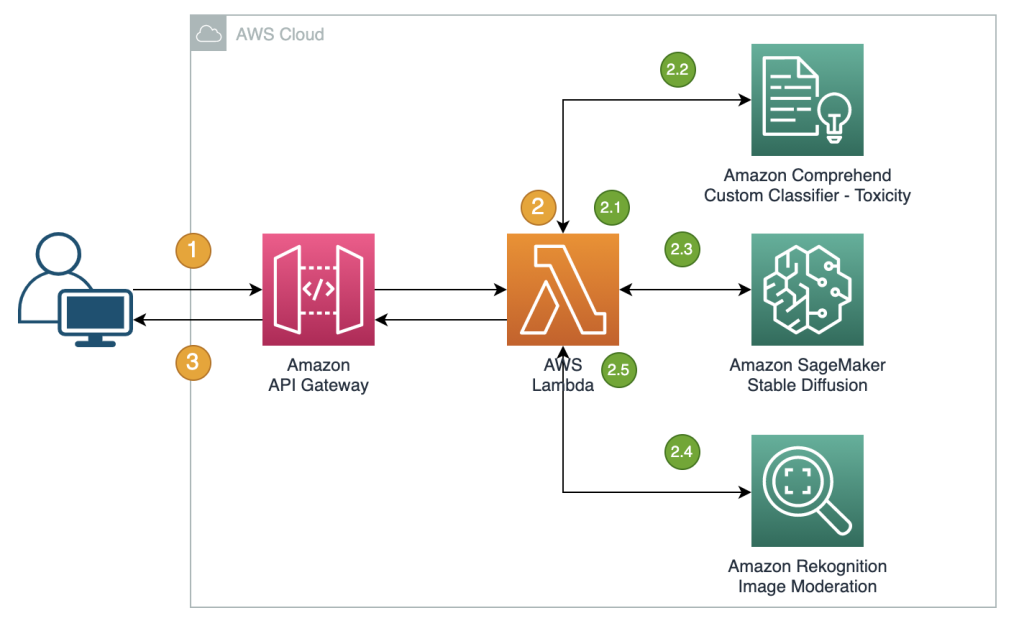
ワークフローの手順は以下の通りです:
- ユーザーが画像を生成するためのプロンプトを送信します。
- AWS Lambda関数が、Amazon Comprehend、JumpStart、およびAmazon Rekognitionを使用して画像生成とモデレーションを調整します:
- Lambda関数内でルールベースの条件を入力プロンプトに適用し、禁止ワードの検出によるコンテンツモデレーションを強制します。
- Amazon Comprehendのカスタム分類器を使用して、プロンプトテキストを有害性の分類に分析します。
- SageMakerエンドポイントを介してStable Diffusionモデルにプロンプトを送信し、ユーザー入力のプロンプトと事前定義されたリストからのネガティブプロンプトの両方を渡します。
- SageMakerエンドポイントから返された画像バイトをAmazon Rekognitionの
DetectModerationLabelAPIに送信して画像モデレーションを行います。 - 前の手順でプロンプトまたは生成された画像に不適切な情報が検出された場合、画像バイトと警告を含むレスポンスメッセージを作成します。
- レスポンスをクライアントに送信します。
以下のスクリーンショットは、上記のアーキテクチャを使用して構築されたサンプルアプリです。Web UIはユーザーの入力プロンプトをRESTfulプロキシAPIに送信し、レスポンスで受け取った画像とモデレーションの警告を表示します。デモアプリは、生成された画像に不適切なコンテンツが含まれている場合は実際の生成画像をぼかします。サンプルのプロンプト「セクシーな女性」でアプリをテストしました。
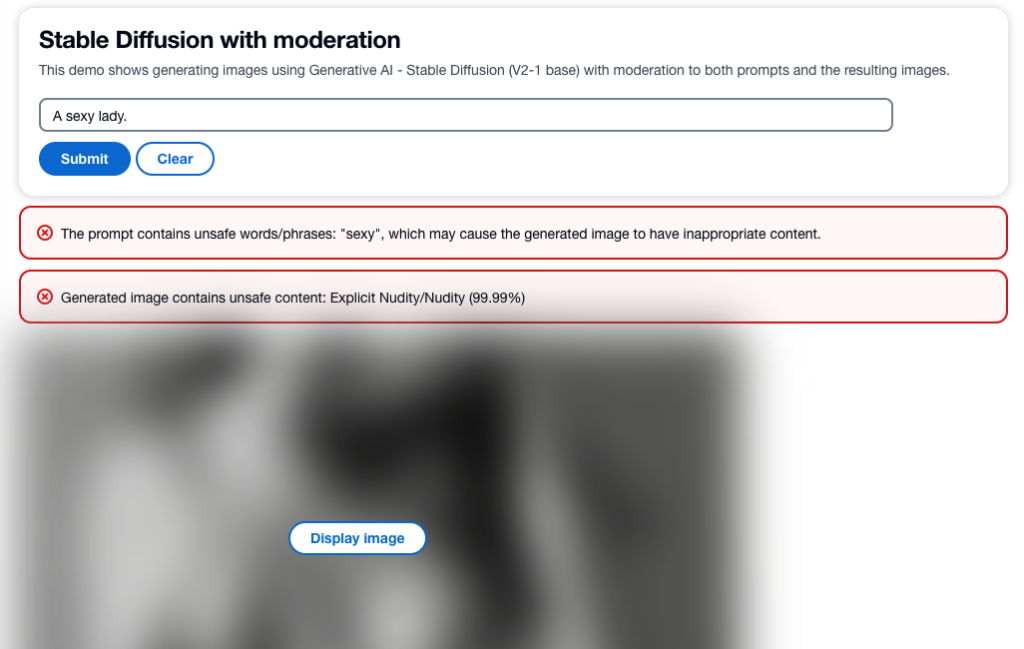
より良いユーザーエクスペリエンスのために、プロンプトに不適切な情報が含まれている場合はリクエストを拒否するなど、より洗練されたロジックを実装することもできます。また、プロンプトは安全であるが出力が安全でない場合、イメージを再生成するためのリトライポリシーを持つこともできます。
ネガティブなプロンプトのリストを事前定義する
Stable Diffusionは、ネガティブなプロンプトをサポートしており、イメージ生成中に回避するプロンプトを指定することができます。モデルが安全でないイメージを生成しないようにするために、ネガティブなプロンプトの事前定義リストを作成することは、実践的かつ積極的なアプローチです。プロンプトに「裸」「セクシー」「ヌード」といった、不適切または攻撃的なイメージを引き起こすとされるものを含めることで、モデルはそれらを認識し回避することができ、安全でないコンテンツの生成リスクを低減させます。
実装は、Stable Diffusionモデルの推論を実行するためにSageMakerエンドポイントを呼び出すLambda関数で管理することができます。ユーザーの入力からのプロンプトと事前定義リストからのネガティブなプロンプトの両方を渡すようにします。
このアプローチは効果的ですが、Stable Diffusionモデルが生成する結果に影響を与え、機能を制限する可能性があります。これは、Amazon ComprehendとAmazon Rekognitionを使用したテキストとイメージのモデレーションと組み合わせるなど、モデレーションの手法の1つとして考慮することが重要です。
入力プロンプトをモデレートする
テキストのモデレーションの一般的なアプローチは、事前定義リストから禁止ワードやフレーズをキーワード検索するルールベースの方法を使用することです。この方法は実装が比較的容易で、パフォーマンスへの影響が少なく、コストも低いです。ただし、このアプローチの主な欠点は、事前定義リストに含まれている単語だけを検出し、リストに含まれていない禁止ワードの新しいまたは変更されたバリエーションを検出できないことです。ユーザーは、代替スペルや特殊文字を使用してルールを回避しようとすることもあります。
ルールベースのテキストモデレーションの制限に対処するために、多くのソリューションは、ルールベースのキーワード検索とMLベースの有害度検出を組み合わせたハイブリッドアプローチを採用しています。両方のアプローチの組み合わせにより、より包括的で効果的なテキストモデレーションソリューションが可能となり、不適切なコンテンツのさまざまな範囲を検出し、モデレーションの結果の精度を向上させることができます。
このソリューションでは、Amazon Comprehendカスタム分類器を使用して有害度検出モデルをトレーニングし、明示的な禁止ワードが検出されない場合に入力プロンプトの潜在的に有害なコンテンツを検出するために使用します。機械学習の力を活用することで、ルールベースのアプローチでは容易に検出できないテキストのパターンをモデルに学習させることができます。
Amazon Comprehendは管理されたAIサービスとして、トレーニングと推論を簡素化します。Amazon Comprehendカスタム分類を2つのステップで簡単にトレーニングおよび展開できます。Amazon Comprehendカスタム分類器を使用した有害度検出モデルに関する詳細については、ワークショップラボをご覧ください。このラボでは、カスタム有害度分類器を作成してアプリケーションに統合するためのステップバイステップガイドが提供されます。次の図は、このソリューションアーキテクチャを示しています。
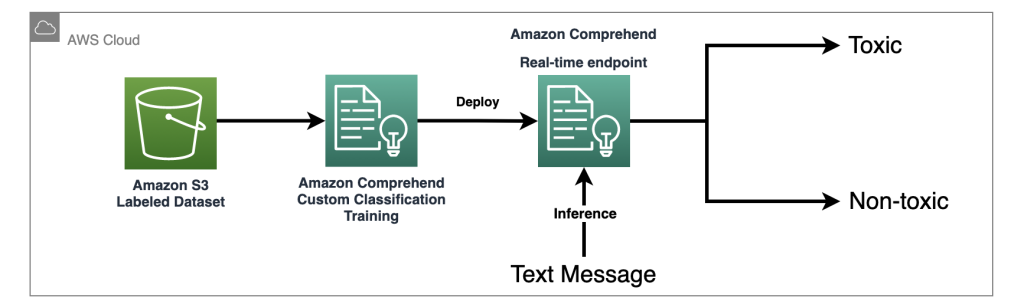
このサンプル分類器は、ソーシャルメディアのトレーニングデータセットを使用し、バイナリ分類を実行します。ただし、テキストモデレーションのニーズによっては、Amazon Comprehendカスタム分類器のトレーニングにより特化したデータセットを使用することを検討してください。
出力イメージをモデレートする
入力テキストプロンプトのモデレーションは重要ですが、Stable Diffusionモデルによって生成されるすべてのイメージが対象の視聴者にとって安全であることを保証するものではありません。なぜなら、モデルの出力にはある程度のランダム性が含まれる場合があるためです。そのため、Stable Diffusionモデルによって生成されたイメージもモデレートすることが同様に重要です。
このソリューションでは、Amazon Rekognitionコンテンツモデレーションを利用して、イメージやビデオの不適切なコンテンツを検出します。このソリューションでは、Amazon Rekognition DetectModerationLabel APIを使用して、Stable Diffusionモデルによって生成されたイメージをリアルタイムでモデレートします。Amazon Rekognitionコンテンツモデレーションは、暴力、ヌード、憎悪のシンボルなど、さまざまな不適切または攻撃的なコンテンツを分析するためのプリトレーニング済みAPIを提供しています。Amazon Rekognitionコンテンツモデレーションのタクソノミの包括的なリストについては、コンテンツのモデレーションを参照してください。
以下のコードは、PythonのBoto3ライブラリを使用してLambda関数内でAmazon RekognitionのDetectModerationLabel APIを呼び出し、イメージをモデレーションする方法を示しています。この関数は、SageMakerから返されたイメージバイトを受け取り、それらをイメージモデレーションAPIに送信します。
import boto3
# Amazon Rekognitionクライアントオブジェクトの初期化
rekognition = boto3.client('rekognition')
# RekognitionイメージモデレーションAPIを呼び出して結果を保存する
response = rekognition.detect_moderation_labels(
Image={
'Bytes': base64.b64decode(img_bytes)
}
)
# APIのレスポンスを出力する
print(response)Amazon Rekognition Image Moderation APIの追加の例については、Content Moderation Image Labを参照してください。
モデルの微調整のための効果的な画像モデレーション技術
微調整は、事前にトレーニングされたモデルを特定のタスクに適応させるための一般的なテクニックです。Stable Diffusionの場合、微調整を使用して、特定のオブジェクト、スタイル、キャラクターを組み入れた画像を生成することができます。不適切または攻撃的な画像の生成を防止するため、コンテンツモデレーションはStable Diffusionモデルのトレーニング時に重要です。これには、そのような画像の生成につながる可能性があるデータを注意深くレビューし、フィルタリングすることが含まれます。これにより、モデルはより多様で代表的なデータポイントから学習し、その精度を向上させ、有害なコンテンツの伝播を防止します。
JumpStartは、DreamBoothメソッドを使用した転移学習スクリプトを提供することで、Stable Diffusionモデルの微調整を簡単に行うことができます。トレーニングデータを準備し、ハイパーパラメータを定義し、トレーニングジョブを開始するだけです。詳細については、Amazon SageMaker JumpStartを使用してテキストから画像のStable Diffusionモデルを微調整するを参照してください。
微調整のためのデータセットは、Amazon Simple Storage Service(Amazon S3)のディレクトリ内に画像とインスタンスの設定ファイルdataset_info.jsonを含める必要があります。以下のコードに示すように、JSONファイルは画像をインスタンスのプロンプトに関連付けます:{'instance_prompt':<<instance_prompt>>}。
input_directory
|---instance_image_1.png
|---instance_image_2.png
|---instance_image_3.png
|---instance_image_4.png
|---instance_image_5.png
|---dataset_info.jsonもちろん、画像を手動でレビューしてフィルタリングすることもできますが、これは時間がかかるし、多くのプロジェクトやチーム全体でスケールして行う場合には実用的ではありません。そのような場合、バッチプロセスを自動化してすべての画像をAmazon RekognitionのDetectModerationLabel APIで一括チェックし、トレーニングデータを汚染しないように画像にフラグを立てるか削除することができます。
モデレーションのレイテンシとコスト
このソリューションでは、テキストと画像をモデレートするために順次パターンが使用されています。テキストのモデレーションにはルールベースの関数とAmazon Comprehendが呼び出され、画像のモデレーションにはStable Diffusionの呼び出し前後にAmazon Rekognitionが使用されます。このアプローチは、入力プロンプトと出力画像を効果的にモデレートしますが、ソリューション全体のコストとレイテンシを増加させる可能性がありますので、考慮する必要があります。
レイテンシ
Amazon RekognitionとAmazon Comprehendは、高い可用性と組み込みのスケーラビリティを持つ管理されたAPIを提供しています。入力サイズやネットワーク速度によるレイテンシの変動があるかもしれませんが、このソリューションで使用される両サービスのAPIはほぼリアルタイムの推論を提供します。Amazon Comprehendのカスタム分類器エンドポイントでは、100文字未満のテキストサイズに対して200ミリ秒未満の速度を提供できます。一方、Amazon Rekognition Image Moderation APIは、平均ファイルサイズが1MB未満の場合に約500ミリ秒かかります。(これは、ほぼリアルタイムの要件として認められるテストに基づいています。)
合計すると、Amazon RekognitionとAmazon ComprehendへのモデレーションAPI呼び出しは、API呼び出しに700ミリ秒を追加します。モデレーションによって導入されるレイテンシは、プロンプトの複雑さと基盤インフラストラクチャの能力によって通常のStable Diffusionリクエストよりも長くかかる場合があります。テストアカウントでは、ml.p3.2xlargeのインスタンスタイプを使用した場合、SageMakerエンドポイントを介したStable Diffusionモデルの平均応答時間は約15秒でした。したがって、モデレーションによって導入されるレイテンシは、システム全体のパフォーマンスにほぼ5%の影響を与えるため、全体の応答時間には最小限の影響です。
コスト
Amazon Rekognition Image Moderation APIは、リクエストの数に基づく都度課金モデルを採用しています。コストは使用されるAWSリージョンによって異なり、階層型の価格設定構造に従います。リクエストの数が増えるにつれて、リクエストあたりのコストが減少します。詳細については、Amazon Rekognitionの価格設定を参照してください。
このソリューションでは、Amazon Comprehendカスタム分類器を利用し、Amazon Comprehendエンドポイントとして展開してリアルタイム推論を行っています。この実装には、一度だけのトレーニングコストと継続的な推論コストが発生します。詳細については、Amazon Comprehendの価格設定を参照してください。
Jumpstartを使用すると、Stable Diffusionモデルを単一のパッケージとして迅速に起動して展開することができます。Stable Diffusionモデルでの推論実行には、Amazon Elastic Compute Cloud(Amazon EC2)インスタンスの基礎となるコスト、およびインバウンドとアウトバウンドのデータ転送にかかるコストが発生します。詳細については、Amazon SageMakerの価格設定を参照してください。
概要
この投稿では、Amazon ComprehendとAmazon Rekognitionを使用して、Stable Diffusionの入力プロンプトと出力イメージをモデレートする方法を示すサンプルソリューションの概要を提供しました。さらに、Stable Diffusionでネガティブプロンプトを定義することで、安全でないコンテンツの生成を防ぐことができます。複数のモデレーションレイヤーを実装することで、安全で信頼性の高いユーザーエクスペリエンスを確保し、安全で信頼性の高いユーザーエクスペリエンスを確保することができます。
AWSのコンテンツモデレーションとコンテンツモデレーションMLのユースケースについて詳しく学び、AWSを使用したコンテンツモデレーションオペレーションの効率化に向けた第一歩を踏み出してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 銀行向けのGoogleの新しいマネーロンダリング対策AIツールに会いましょう
- イスラエルの秘密エージェントが強力な生成AIで脅威と戦う方法
- Googleはチャットボットの使用について従業員に警告、ここにその理由があります
- Langchainを使用してYouTube動画用のChatGPTを構築する
- Earth.comとProvectusがAmazon SageMakerを使用してMLOpsインフラストラクチャを実装する方法
- Amazon SageMaker StudioでAmazon SageMaker JumpStartの独自の基盤モデルを使用してください
- A.I.はいつか医療の奇跡を起こすかもしれませんしかし今のところ、役立つのは書類作業です






