Amazon SageMaker Canvasを使用して、ノーコードの機械学習を活用して、公衆衛生の洞察をより迅速にキャプチャーしましょう
Use Amazon SageMaker Canvas to capture public health insights more quickly using no-code machine learning.
公衆衛生機関は、さまざまな種類の疾患、健康動向、リスク要因に関する豊富なデータを持っています。彼らのスタッフは、治療薬を持つ病気の最も高いリスク要因を持つ人口をターゲットにしたり、懸念すべき発生の進行を予測したりするなど、重要な意思決定をするために長い間統計モデルと回帰分析を使用してきました。
公衆衛生上の脅威が現れると、データの速度が増加し、入力データセットが大きくなり、データ管理がより困難になります。これにより、データを包括的に分析し、洞察を得ることがより困難になります。そして、時間が重要な場合、データを分析し、洞察を得るためのスピードと機敏さは、迅速かつ堅牢な健康対応の形成における主要な障害となります。
ストレスのかかる時期に直面する典型的な公衆衛生機関の質問には以下があります:
- 特定の場所に十分な治療薬があるか?
- 健康の結果に影響を及ぼすリスク要因は何か?
- どの人口が再感染のリスクが高いですか?
これらの質問に答えるには、多くの異なる要因間の複雑な関係を理解する必要があります。そのため、私たちの手元にある1つの強力なツールは、機械学習(ML)です。機械学習は、これらの複雑な数量的問題を分析、予測、解決するために展開することができます。私たちは、画像解析による脳腫瘍の分類や早期介入プログラムを展開するための精神保健の必要性を予測するなど、MLが難しい健康関連の問題に適用されるのをますます目にします。
- フィールドからフォークへ:スタートアップが食品業界にAIのスモーガスボードを提供
- 誰が雨を止めるのか? 科学者が気候協力を呼びかける
- このスペースを見る:AIを使用してリスクを推定し、資産を監視し、クレームを分析する新しい空間金融の分野
しかし、公衆衛生機関がこれらの質問に対して必要なスキルの供給が不足している場合、MLを公衆衛生問題に適用することが妨げられ、公衆衛生機関は強力な数量的ツールを使用して課題に対処する能力を失います。
では、これらのボトルネックを取り除くにはどうすればよいでしょうか?答えは、MLを民主化し、深いドメイン知識を持つ多くの保健専門家がそれを使用し、解決しようとする質問に適用できるようにすることです。
Amazon SageMaker Canvasは、疫学者、情報学者、生物統計学者などの公衆衛生専門家がMLを自分の質問に適用するためのノーコードのMLツールです。データサイエンスのバックグラウンドやMLの専門知識は必要ありません。彼らはデータに時間を費やし、ドメインの専門知識を適用し、仮説を迅速にテストし、洞察を定量化することができます。Canvasは、MLを民主化することで公衆衛生をより公平にするのに役立ち、保健専門家が大規模なデータセットを評価し、MLを使って高度な洞察を得ることができるようにします。
この記事では、公衆衛生の専門家がCanvasを使用して次の30日間の特定の治療薬の需要を予測する方法を示します。Canvasは、MLの経験やコードの記述は不要で、独自に正確なML予測を生成するための視覚インターフェースを提供します。
ソリューション概要
たとえば、米国全体の州から収集したデータで作業しているとしましょう。特定の自治体や場所には、今後数週間で十分な治療薬がないという仮説を立てるかもしれません。これを迅速かつ高い精度でテストするにはどうすればよいでしょうか?
この記事では、米国保健福祉省から入手可能なデータセットを使用しています。このデータセットには、COVID-19に関連する州別集計の時系列データが含まれており、病院の利用状況、特定の治療薬の入手可能性などが含まれています。このデータセット(COVID-19 Reported Patient Impact and Hospital Capacity by State Timeseries(RAW))は、healthdata.govからダウンロードでき、135の列と6万行以上のデータがあります。データセットは定期的に更新されます。
次のセクションでは、探索的データ分析と準備、ML予測モデルの構築、およびCanvasを使用した予測の生成方法を示します。
探索的データ分析と準備の実施
Canvasで時系列予測を行う場合、サービスのクオータに応じて特徴量または列の数を減らす必要があります。最初に、最も関連性のあると思われる12の列に列を減らします。たとえば、年齢別の列は除外し、総需要を予測することを目指しています。また、他の列と似たデータを持つ列も削除しました。将来の反復では、他の列を保持し、Canvasの特徴量の説明可能性を使用してこれらの特徴量の重要性と保持するものを定量化することを検討することも合理的です。また、state列をlocationに名前を変更します。
データセットを見ると、2020年のすべての行を削除することも決定しました。その時点では、利用可能な治療薬が限られていました。これにより、ノイズを減らし、MLモデルが学習するためのデータの品質を向上させることができます。
列の数を減らす方法はさまざまです。スプレッドシートでデータセットを編集するか、ユーザーインターフェースを使用してCanvas内で直接編集することができます。
さまざまなソースからCanvasにデータをインポートできます。これには、コンピューターのローカルファイル、Amazon Simple Storage Service(Amazon S3)バケット、Amazon Athena、Snowflake(Snowflakeの統合を使用してファシーズ分類のトレーニングおよび検証データセットを準備し、Amazon SageMaker Canvasを使用してトレーニングする方法については、こちらをご覧ください)、および40以上の追加のデータソースが含まれます。
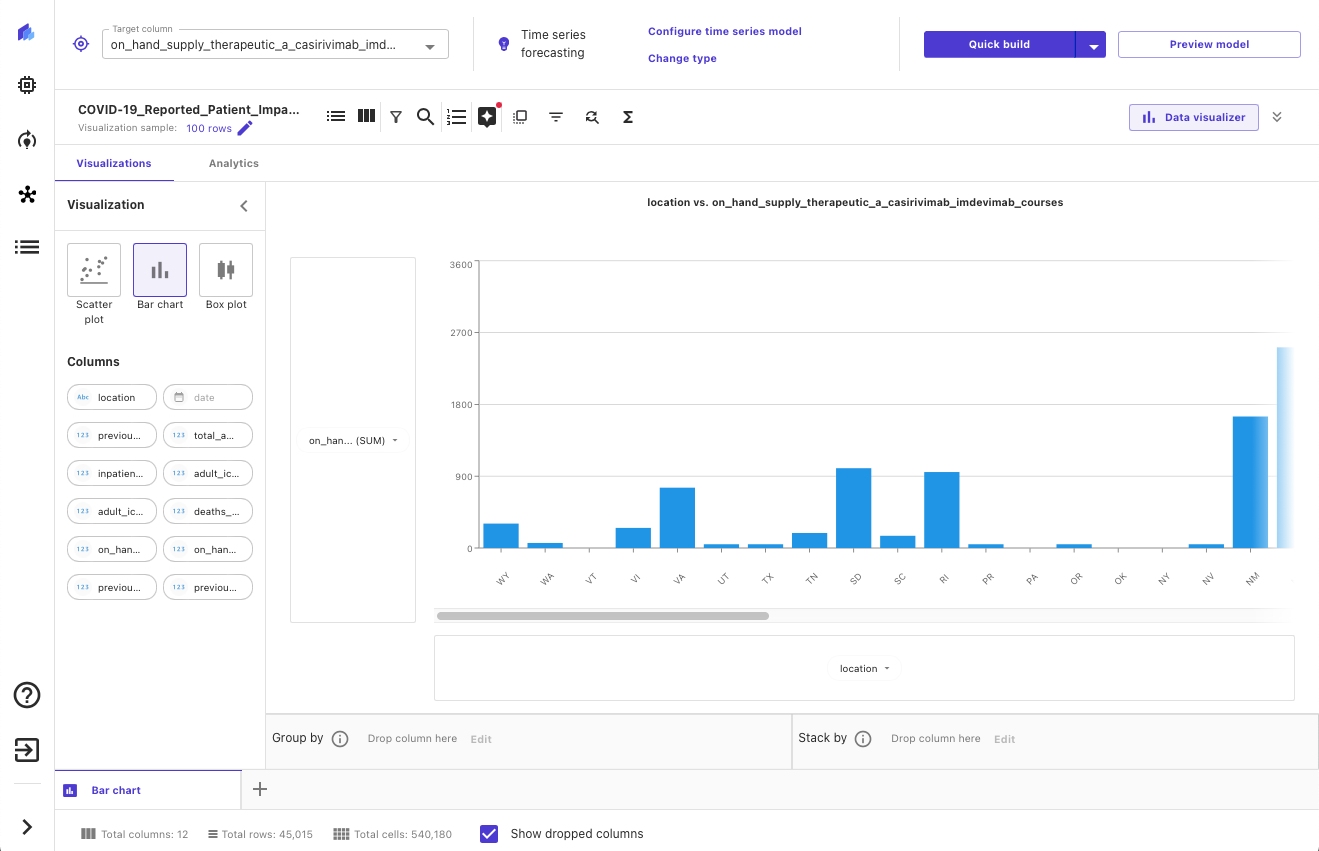
データのインポートが完了したら、散布図や棒グラフなどを使用してデータを探索し、可視化してさらなる洞察を得ることができます。さらに、異なる特徴間の相関関係も確認し、最善と考えられるものを選択していることを確認します。以下のスクリーンショットは、可視化の例を示しています。
ML予測モデルを構築する
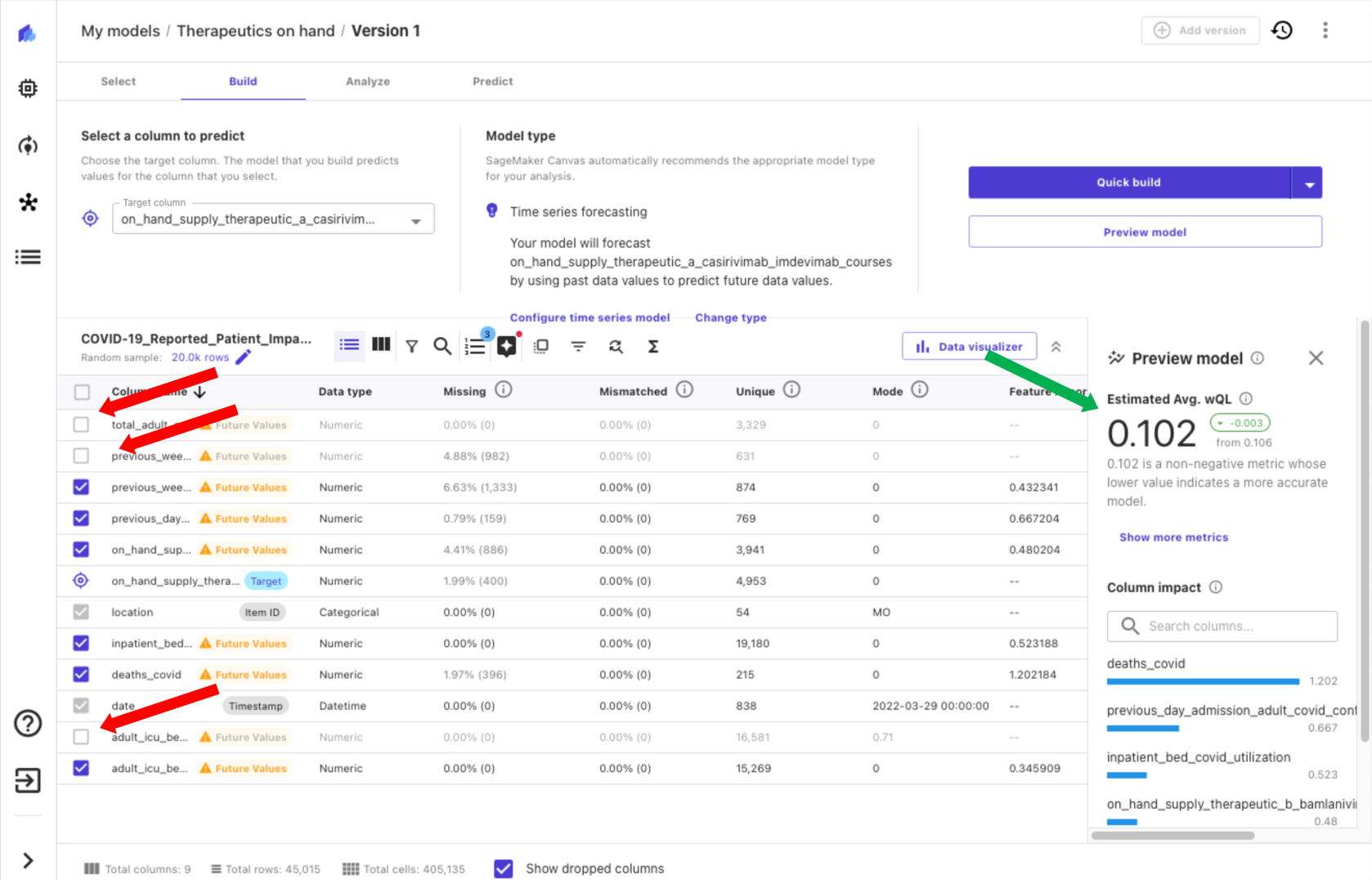
さあ、いくつかのクリックでモデルを作成する準備が整いました。ターゲットとして、在庫保有セラピューティクスを識別する列を選択します。Canvasは、選択したターゲット列に基づいて、問題を時系列予測として自動的に識別し、必要なパラメータを設定できます。
データセットが場所(米国の州)ごとに提供されているため、一意の識別子であるitem_idを場所として設定します。時系列予測を作成しているため、データセット内のdateをタイムスタンプとして選択する必要があります。最後に、何日先まで予測するかを指定します(この例では30日を選択します)。Canvasでは、精度を向上させるために休日スケジュールを含めることもできます。この場合、米国の祝日を使用します。
Canvasでは、モデルを構築する前にデータから洞察を得るためにモデルのプレビューを選択できます。これにより、結果が満足できない場合にはモデルを構築せずに時間とコストを節約できます。モデルをプレビューすることで、いくつかの列の影響が低いことがわかります。つまり、モデルへの列の期待値が低いということです。これらの列をCanvasで選択解除することで(以下のスクリーンショットの赤い矢印)、推定品質メトリックスが改善されることがわかります(緑の矢印)。
次に、モデルの構築に進みます。 クイックビルド と スタンダードビルド の2つのオプションがあります。クイックビルドは、正確性よりも速度を優先し、20分以内でトレーニング済みのモデルを生成します。これは実験に最適であり、プレビューモデルよりも詳細なモデルです。スタンダードビルドは、正確性を優先し、最適なモデルを自動的に選択するために複数のモデル構成を反復処理することで、4時間以内でトレーニング済みのモデルを生成します。
まず、クイックビルドでモデルプレビューを検証します。その後、モデルに満足した場合は、Canvasにデータセットに最適なモデルを構築するのを手助けしてもらうためにスタンダードビルドを選択します。クイックビルドモデルが満足のいく結果を出さなかった場合は、入力データを調整してより高い精度を捉えることができます。たとえば、元のデータセットに列や行を追加または削除することでこれを実現できます。クイックビルドモデルは、希少なデータサイエンスリソースに依存することなく、完全なモデルの完成を待つことなく迅速に実験を行うことができます。
予測を生成する
モデルが構築されたので、locationごとにセラピューティクスの入手可能性を予測することができます。次の30日間、この場合はワシントンDCの在庫状況を見てみましょう。
Canvasは、セラピューティクスの需要に対する確率的な予測を出力します。これにより、中央値だけでなく上限値と下限値も理解することができます。以下のスクリーンショットでは、過去のデータ(元のデータセットのデータ)の末尾が表示されています。その後、紫色の中央値(50番目の分位数)の予測、薄い青色の下限値(10番目の分位数)、および濃い青色の上限値(90番目の分位数)が表示されます。
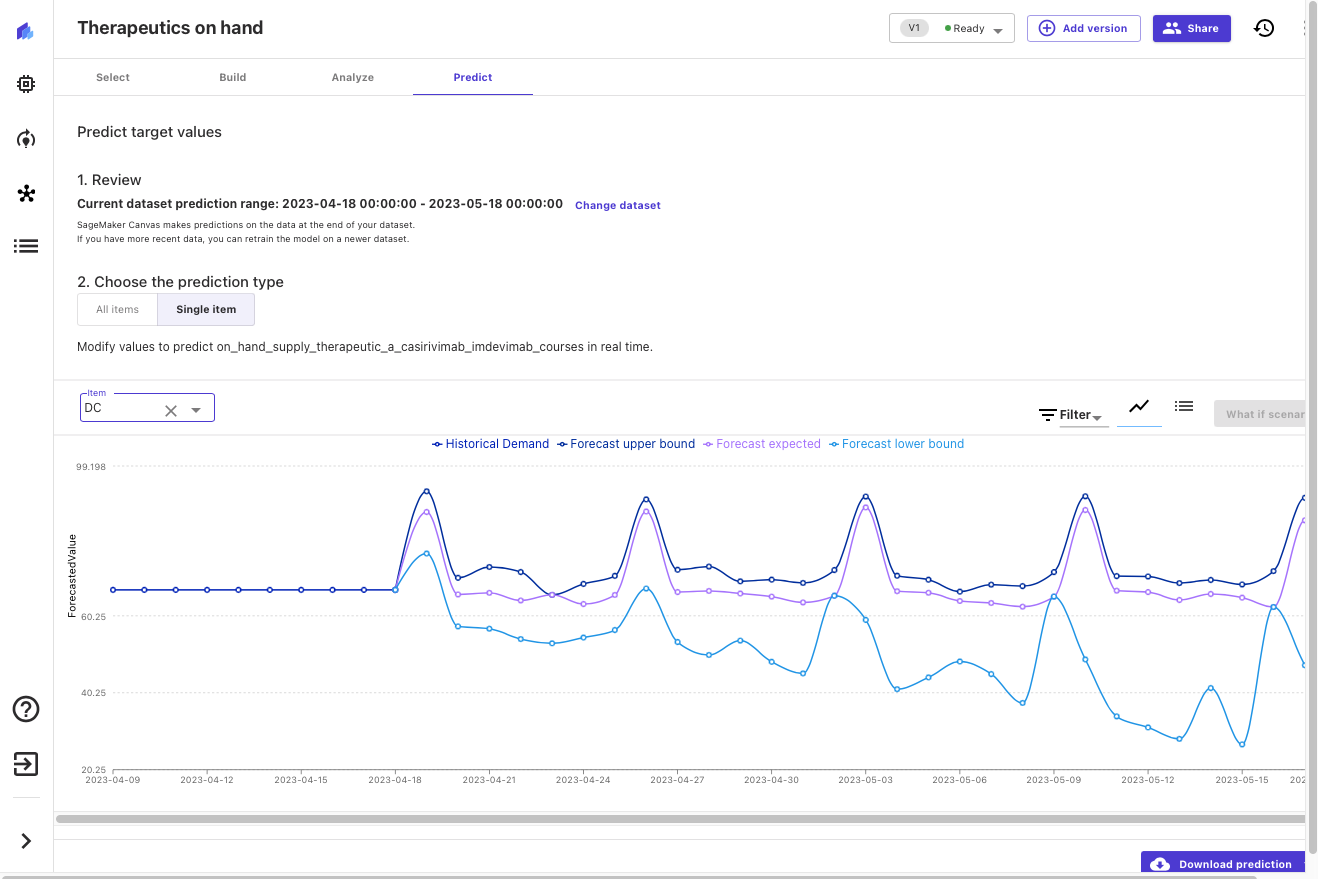
上限と下限を調べることにより、予測の確率分布を分析し、この治療法の望ましい地域在庫レベルに関する情報を得ることができます。この情報を他のデータ(たとえば、疾患進行予測や治療効果・普及率など)と組み合わせることで、将来の発注や在庫レベルに関する的確な決定を行うことができます。
結論
ノーコードの機械学習ツールは、公衆衛生専門家が迅速かつ効果的に機械学習を公衆衛生上の脅威に適用することを可能にします。この機械学習の民主化により、公衆衛生機関は公衆衛生の保護活動においてより俊敏で効率的になります。公衆衛生上の重要なトレンドや転換点を特定することができるアドホックな分析は、専門家が直接実行できるようになり、限られた機械学習の専門家リソースを競わなくてもよくなり、対応時間や意思決定の遅延を防ぐことができます。
この記事では、機械学習の知識がない人でも、Canvasを使用して特定の治療法の在庫を予測する方法を紹介しました。クラウドテクノロジーとノーコードの機械学習の力によって、この分析は現場のアナリストなら誰でも実行することができます。これにより、能力が広く分散し、公衆衛生機関はより迅速に対応し、集中管理されたリソースや現場オフィスのリソースを効率的に活用して、より良い公衆衛生の結果を提供することができます。
自分自身の定量的な健康問題に対して機械学習を適用するために、どのような質問が浮かびますか?もしCanvasについてさらに学びたい場合は、Amazon SageMaker Canvasを参照し、ご自身の健康問題に対して機械学習を適用してみてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
- Meet ChatGLM2-6B:オープンソースのバイリンガル(中国語-英語)チャットモデルChatGLM-6Bの第2世代バージョンです
- 専門AIトレーニングの変革- LMFlowの紹介:優れたパフォーマンスのために大規模な基盤モデルを効率的に微調整し、個別化するための有望なツールキット
- プロンプトエンジニアリングへの紹介
- MosaicMLは、彼らのMPT-30BをApache 2.0の下でリリースしました
- キャッシュの遷移に対する自動フィードバックによる優先学習
- ニューラルネットワークにおける活性化関数の種類