キャッシュの遷移に対する自動フィードバックによる優先学習
'キャッシュの遷移に対する自動フィードバックによる優先学習' can be condensed to 'キャッシュ遷移への自動フィードバックによる優先学習'.
Googleのソフトウェアエンジニア、Ramki GummadiとYouTubeのソフトウェアエンジニア、Kevin Chenによって投稿されました。
キャッシュは、リクエストパターンに基づいてクライアントに近い場所に人気のあるアイテムの一部を保存することで、ストレージおよび検索システムのパフォーマンスを大幅に向上させる、コンピュータサイエンスにおける普遍的なアイデアです。キャッシュの管理における重要なアルゴリズムの一部は、格納されるアイテムのセットを動的に更新するために使用される決定ポリシーであり、数十年にわたって広範に最適化されてきました。これにより、いくつかの効率的で堅牢なヒューリスティクスが生まれました。機械学習をキャッシュポリシーに適用することは、最近の研究で有望な結果を示していますが(例:LRB、LHD、ストレージアプリケーションなど)、競争力のある計算およびメモリの負荷を維持しながら、信頼性のあるヒューリスティクスをベンチマークを超えて信頼性のある汎用的な設定に対して上回ることはまだ課題です。
NSDI 2023で発表された「YouTubeコンテンツデリバリーネットワークのためのヒューリスティック支援学習優先エヴィクションポリシー(HALP)」では、学習された報酬を基にしたスケーラブルな最先端のキャッシュエヴィクションフレームワークを紹介しています。HALPフレームワークは、軽量なヒューリスティックベースラインエヴィクションルールと学習された報酬モデルを組み合わせるメタアルゴリズムです。報酬モデルは、オフラインのオラクルを模倣するために設計された選好比較に基づく継続的な自動フィードバックでトレーニングされる軽量なニューラルネットワークです。HALPがYouTubeのコンテンツデリバリーネットワークのインフラストラクチャの効率性とユーザーのビデオ再生遅延を改善した方法について説明します。
キャッシュエヴィクションの決定のための学習済みの選好
HALPフレームワークは、2つのコンポーネントに基づいてキャッシュエヴィクションの決定を行います:(1)自動フィードバックを介した選好学習によってトレーニングされたニューラル報酬モデル、および(2)学習された報酬モデルと高速ヒューリスティックを組み合わせるメタアルゴリズム。キャッシュが入力リクエストを観察すると、HALPはペアワイズの選好フィードバックを介した選好学習法として、各アイテムに対してスカラー報酬を予測する小規模なニューラルネットワークを継続的にトレーニングします。HALPのこの側面は、人間のフィードバックからの強化学習(RLHF)システムに似ていますが、2つの重要な違いがあります:
- フィードバックは自動化されており、オフラインの最適キャッシュエヴィクションポリシーの構造に関するよく知られた結果を活用しています。
- モデルは、自動フィードバックプロセスから構築されたトレーニングの例の一時バッファを使用して継続的に学習されます。
エヴィクションの決定は、2つのステップを持つフィルタリングメカニズムに依存しています。まず、パフォーマンスの観点ではサブオプティマルですが、効率的なヒューリスティックを使用して、小さな候補のサブセットが選択されます。次に、再ランキングステップによって、ベースラインの候補から内部の最終的な決定の品質を「ブーストする」ために、ニューラルネットワークのスコアリング関数が使用されます。
HALPは、エヴィクションの決定だけでなく、効率的なフィードバックの構築とモデルの更新に使用されるペアワイズの選好クエリのサンプリングのエンドツーエンドのプロセスを包括しています。
ニューラル報酬モデル
HALPは、キャッシュ内の個々のアイテムを選択的にスコアリングするために、軽量な2層のマルチレイヤーパーセプトロン(MLP)を報酬モデルとして使用します。特徴は、メタデータのみの「ゴーストキャッシュ」として構築および管理されます(ARCなどの古典的なポリシーと同様)。任意のルックアップリクエストの後、通常のキャッシュ操作に加えて、HALPはダイナミックな内部表現を更新するために必要なブックキーピング(例:キャッシュルックアップリクエストと共にユーザーから提供される外部のタグ付き特徴、および各アイテムで観測されたルックアップ時間から構築された内部的な動的特徴など)を実行します。
HALPは、ランダムな重み初期化から完全にオンラインで報酬モデルを学習します。これは、報酬モデルを最適化するためにのみ決定が行われる場合、悪いアイデアのように思えるかもしれません。ただし、エヴィクションの決定は、学習された報酬モデルとLRUなどのサブオプティマルでシンプルかつ堅牢なヒューリスティックの両方に依存しています。これにより、報酬モデルが完全に一般化された場合に最適なパフォーマンスが得られる一方で、一時的に一般化されていないまたは変化する環境に追いつく途中の情報の少ない報酬モデルにも堅牢性があります。
オンライントレーニングのもう一つの利点は、専門化です。キャッシュサーバーはそれぞれ異なる環境(地理的位置など)で実行されるため、ローカルのネットワーク状況やローカルで人気のあるコンテンツなどに影響を受けます。オンライントレーニングは、この情報を自動的にキャプチャする一方で、単一のオフライントレーニングソリューションとは異なり、一般化の負担を軽減します。
ランダム化された優先度キューからのスコアリングサンプル
エヴィクションの決定の品質を排他的に学習された目的に最適化することは、2つの理由で実用的ではありません。
- 計算効率の制約: 学習されたネットワークによる推論は、実際のキャッシュポリシーの計算に比べてかなり高コストになることがあります。これはネットワークと特徴の表現力だけでなく、各エビクションの決定時にこれらがどれくらい頻繁に呼び出されるかも制約します。
- 分布外の汎化のための堅牢性: HALPは、継続的な学習を伴うセットアップで展開されており、急速に変化するワークロードによって、以前に見たデータに関して一時的に分布外になるリクエストパターンが生成される可能性があります。
これらの問題に対処するために、HALPはまず、エビクションの優先順位に対応する安価なヒューリスティックスコアリングルールを適用し、小さな候補サンプルを特定します。このプロセスは、正確な優先順位キューを近似する効率的なランダムサンプリングに基づいています。候補サンプルを生成するための優先関数は、既存の手動調整アルゴリズム(例:LRU)を使用して素早く計算することを意図しています。ただし、これは簡単なコスト関数を編集することによって他のキャッシュ置換ヒューリスティックを近似するように構成できます。以前の研究とは異なり、ランダム化は近似と効率のトレードオフに使用されるものでしたが、HALPでは、トレーニングと推論の両方でサンプルされた候補の時間ステップごとの固有のランダム化にも依存しています。
最終的なエビクトされるアイテムは、提供された候補から選ばれ、ニューラル報酬モデルに従って予測された優先スコアを最大化するために再ランクされたサンプルに相当します。エビクションの決定に使用される候補のプールは、サンプル間のトレーニングと推論のズレを最小限に抑えるために、ペアワイズの優先クエリの構築にも使用されます。
 |
| エビクションの各決定に対して呼び出される2段階プロセスの概要。 |
オンラインでの自動フィードバックによる優先学習
報酬モデルは、自動的に割り当てられた優先ラベルに基づくオンラインフィードバックを使用して学習されます。このフィードバックは、各クエリされたアイテムの時間による将来の再アクセスの受信にかかる時間のランク付け順序をできるだけ示す優先順位順序を示します。これは、キャッシュ内のすべてのアイテムから最も遠い将来のアクセスを削除するオラクル最適ポリシーに類似しています。
 |
| 報酬モデルを学習するための自動フィードバックの生成。 |
このフィードバックプロセスを有益にするために、HALPはエビクションの決定に関連する可能性が最も高いペアワイズの優先クエリを構築します。通常のキャッシュ操作と同期して、HALPは各エビクションの決定時に少数のペアワイズの優先クエリを発行し、それらを保留中の比較セットに追加します。これらの保留中の比較のラベルは、ランダムな将来の時点でのみ解決できます。オンラインで動作するために、HALPは現在のリクエストの後にラベル付けが逐次的に行える保留中の比較を処理するための追加のブックキーピングも行います。HALPは、比較に関与する各要素で保留中の比較バッファをインデックス付けし、再アクセスを受ける可能性のない比較のメモリをリサイクルして、フィードバック生成に関連するメモリオーバーヘッドが時間とともに増大しないようにします。
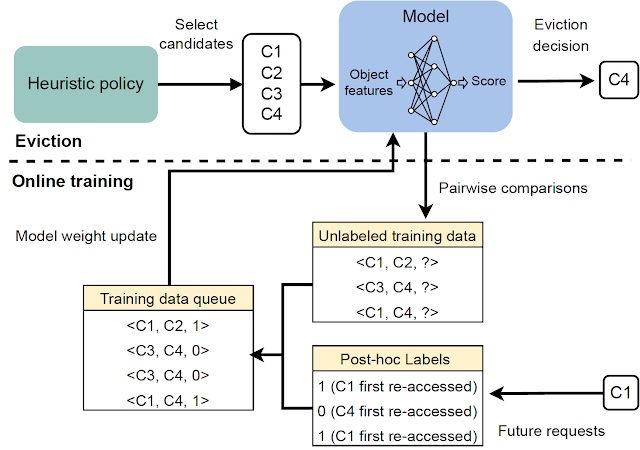 |
| HALPのすべての主要なコンポーネントの概要。 |
結果: YouTube CDNへの影響
経験的な分析により、HALPはキャッシュミス率の観点で、公開ベンチマークトレースにおいて最新のキャッシュポリシーと比較して有利な結果を示しています。ただし、公開ベンチマークは有用なツールである一方で、世界全体の使用パターンや既に展開されている多様なハードウェア構成を完全に捉えることは滅多にありません。
最近まで、YouTubeサーバーはメモリキャッシュの最適化されたLRU変種を使用していました。HALPは、YouTubeのメモリ出力/入力(CDNによって提供される総帯域出力と取得(入力)のキャッシュミスによる消費量の比率)を約12%増加させ、メモリヒット率を6%向上させます。これにより、ユーザーのレイテンシが低下し、ディスクボンドマシンの出力容量が向上し、ディスクトラフィックからディスクを保護することができます。
以下の図は、YouTube CDN上でHALPの最終展開後の日々におけるバイトミス率の顕著な低下を示しており、キャッシュ内からエンドユーザーへのコンテンツの提供が大幅に増加し、レイテンシが低下し、運用コストを増やすことなくより高価な取得に頼る必要がありません。
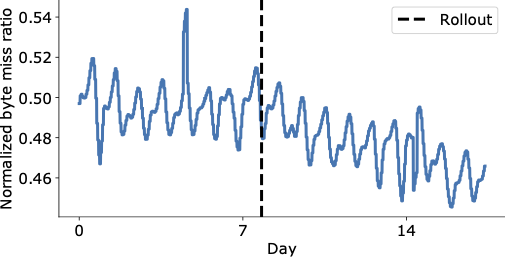 |
| 展開前後の世界中のYouTubeバイトミス率の集計。 |
集計されたパフォーマンスの改善は、重要な回帰を隠す可能性があります。全体的な影響を測定するだけでなく、論文ではマシンレベルの分析を使用してさまざまなラックへの影響を理解し、圧倒的にポジティブであることがわかりました。
結論
学習された報酬に基づくスケーラブルな最新のキャッシュ削除フレームワークを紹介しました。HALPは、他のキャッシュポリシーと同様に展開できるように設計されており、ラベル付きの例、トレーニング手順、モデルバージョンを別個に管理する運用オーバーヘッドはありません。これは、ほとんどの機械学習システムに共通のオフラインパイプラインへの追加コストだけを負担します。そのため、他の古典的なアルゴリズムと比較してわずかな追加コストしかかかりませんが、アクセスパターンの変化に対応するための追加の特徴を利用してキャッシュ削除の決定を行い、継続的に適応する利点があります。
これは、広く使用され、高トラフィックのCDNへの学習されたキャッシュポリシーの大規模な展開の最初であり、CDNインフラの効率を大幅に向上させると同時に、ユーザーにより良い体験を提供します。
謝辞
Ramki Gummadiは現在、Google DeepMindの一員です。イラストに関するJohn Guilyardへの協力と、この投稿に対するRichard Schoolerからのフィードバックに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




