機械学習における再現性の重要性
The importance of reproducibility in machine learning.

私が機械学習を独学していたとき、プロジェクトのチュートリアルに沿ってコードを書いてみたことがありました。著者が示した手順に従っています。しかし、私のモデルがチュートリアルの著者のモデルよりも悪いパフォーマンスを発揮することがありました。同じような状況に陥ったことがあるかもしれません。または、GitHubから同僚のコードを取得した場合、モデルのパフォーマンスメトリックが同僚の報告するものと異なることがあります。つまり、同じことをしても同じ結果が保証されないということです。これは機械学習における深刻な問題である再現性の課題です。
言うまでもなく、他の人が実験を複製し、結果を再現できる場合にのみ、機械学習モデルは有用です。典型的な「私のマシンでは動作します」の問題から機械学習モデルのトレーニング方法に微妙な変更がある場合まで、再現性にはいくつかの課題があります。
本記事では、機械学習における再現性の課題と重要性、およびデータ管理、バージョン管理、および実験追跡が機械学習の再現性の課題に対処するために果たす役割について、詳しく説明します。
機械学習の文脈における再現性とは何ですか?
機械学習の文脈で再現性を最も適切に定義する方法を見てみましょう。
特定のデータセットで特定の機械学習アルゴリズムを使用する既存のプロジェクトがあると仮定しましょう。データセットとアルゴリズムが与えられた場合、私たちはアルゴリズムを(好きな回数だけ)実行し、それぞれの実行で結果を再現(または複製)できるはずです。
しかし、機械学習における再現性には課題があります。既にいくつかの課題について議論していますが、次のセクションで詳しく説明します。
機械学習における再現性の課題
どのアプリケーションにおいても、信頼性や保守性などの課題があります。ただし、機械学習アプリケーションには追加の課題があります。
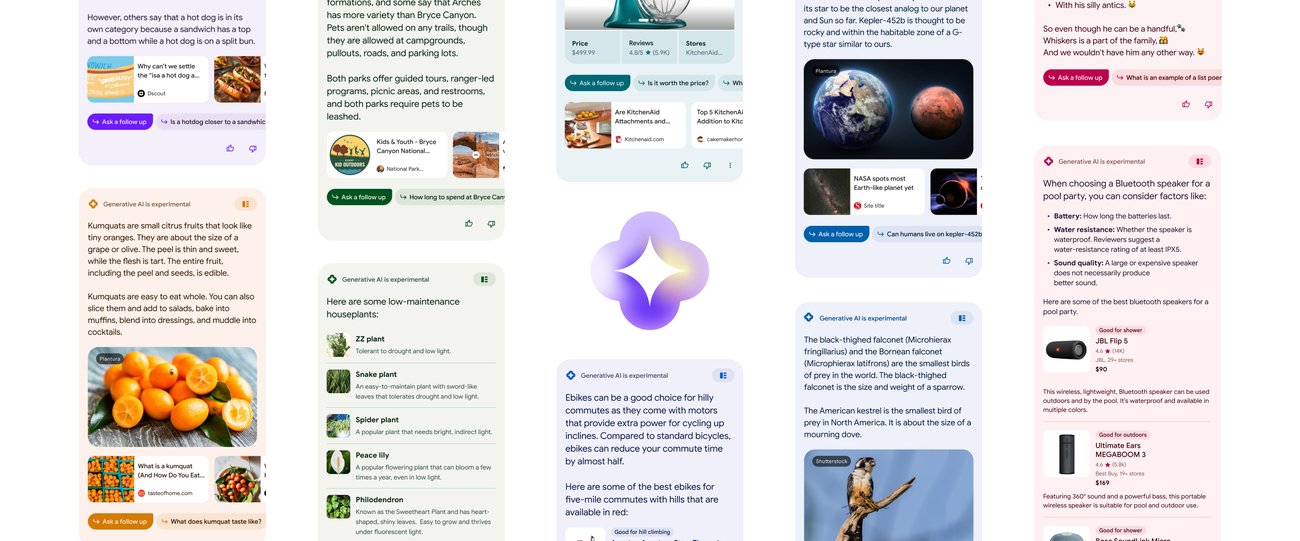
機械学習アプリケーションについて話すとき、通常、以下の手順を含むエンドツーエンドの機械学習パイプラインを参照します。
したがって、再現性の課題は、これらの手順の1つ以上の変更によって発生する可能性があります。ほとんどの変更は、次のいずれかでキャプチャできます。
- 環境変更
- コードの変更
- データ変更
これらの変更が再現性にどのように影響するかを見てみましょう。
環境変更
PythonとPythonベースの機械学習フレームワークを使用すると、MLアプリを開発することが簡単になります。ただし、Pythonでの依存関係の管理(特定のプロジェクトに必要なさまざまなライブラリとバージョンの管理)は、簡単ではありません。異なるバージョンのライブラリを使用することや、廃止された引数を使用した関数呼び出しの変更など、小さな変更でもコードが壊れる可能性があります。
これには、オペレーティングシステムの選択も含まれます。GPU浮動小数点精度の違いなど、ハードウェアに関連する課題があります。
コードの変更
入力データセットをシャッフルして、どのサンプルがトレーニングデータセットに入るかを決定することから、ニューラルネットワークのトレーニング時の重みのランダム初期化まで、ランダム性は機械学習において重要な役割を果たします。
異なるランダムシードを設定すると、まったく異なる結果が得られる場合があります。トレーニングするモデルごとに、一連のハイパーパラメータがあります。したがって、ハイパーパラメータの1つ以上を微調整すると、異なる結果が得られる場合があります。
データ変更

同じデータセットでも、ハイパーパラメータ値やランダム性の不一致が結果の複製を困難にすることがあります。したがって、データが変更されると、データ分布の変更、レコードのサブセットの変更、またはいくつかのサンプルの削除などが結果の再現を困難にします。
まとめると、機械学習モデルの結果を再現しようとすると、コード、使用されるデータセット、および機械学習モデルが実行される環境の最小の変更でも、元のモデルと同じ結果を得ることができない場合があります。
再現性の課題への対処方法
ここでは、これらの課題にどのように対処できるかを見ていきます。
データ管理
再現性における最も明らかな課題の1つは、データに関するものです。データセットのバージョン管理などの特定のデータ管理アプローチがあります。これにより、データセットの変更を追跡し、データセットに役立つメタデータを保存できます。
バージョン管理
コードの変更は、Gitなどのバージョン管理システムを使用して追跡する必要があります。
現代のソフトウェア開発では、変更を追跡し、新しい変更をテストして本番環境にプッシュすることが、よりシンプルで効率的になるCI/CDパイプラインに触れたことがあるでしょう。
他のソフトウェアアプリケーションでは、コードの変更を追跡することが簡単です。しかし、機械学習では、コードの変更には使用されるアルゴリズムやハイパーパラメータ値の変更も含まれる場合があります。単純なモデルでも、試すことができる可能性の数は組み合わせ的に大きくなります。ここで、実験のトラッキングが関連してきます。
実験のトラッキング
機械学習アプリケーションの構築は、広範な実験と同義です。アルゴリズムからハイパーパラメータまで、私たちはさまざまなアルゴリズムやハイパーパラメータ値を試します。したがって、これらの実験を追跡することが重要です。
機械学習の実験のトラッキングには、次のものが含まれます。
- ハイパーパラメータのスイープの記録
- モデルのパフォーマンスメトリック、モデルチェックポイントのログ
- データセットとモデルに関する有用なメタデータの保存
機械学習の実験トラッキング、データ管理などのツール
データセットのバージョン管理、コードの変更の追跡、機械学習の実験のトラッキングは、機械学習アプリケーションを再現するものです。以下は、再現可能な機械学習パイプラインを構築するのに役立つツールのいくつかです。
- Weights and Biases
- MLflow
- Neptune.ai
- Comet ML
- DVC
まとめ
まとめると、機械学習における再現性の重要性と課題について見てきました。データとモデルのバージョン管理、実験のトラッキングなどのアプローチについて説明しました。さらに、実験のトラッキングやより良いデータ管理のために使用できるツールをいくつかリストアップしました。
DataTalks.ClubによるMLOps Zoomcampは、これらのツールのいくつかを使って経験を積むための優れたリソースです。エンドツーエンドの機械学習パイプラインを構築して維持することが好きな場合は、MLOpsエンジニアの役割を理解することに興味があるかもしれません。Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は、数学、プログラミング、データサイエンス、コンテンツ作成の交差点で働くことが好きです。彼女の関心と専門分野には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、コーヒーを楽しんでいます!現在、彼女はチュートリアル、ハウツーガイド、意見記事などの執筆を通じて、開発者コミュニティと彼女の知識を共有することに取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles