複数の画像やテキストの解釈 Multimodal
「LLaVAと一緒にあなたのビジョンチャットアシスタントを作りましょう」
大規模な言語モデルは、革命的な技術であることが証明されていますその能力を活用した数多くのアプリケーションがすでに開発...

マルチモーダルデータ統合:人工知能ががん治療を革命へ導く
最近、私はこの記事(リンク)を読みましたそれは癌のための人工知能(AI)との多模式データ統合についてのものでした扱われ...

「比喩的に言えば、ChatGPTは生きている」
ChatGPTの成長は年々劇的に進んできました最近、OpenAIはChatGPTが聞くこと、見ること、話すことができるようになったことを...

「GPT-4を超えて 新機能は何ですか?」
「GPT-4を超えて:生成AIの4つの主要なトレンド:LLMからマルチモーダル、ベクトルデータベースへの接続、エージェントからOS...
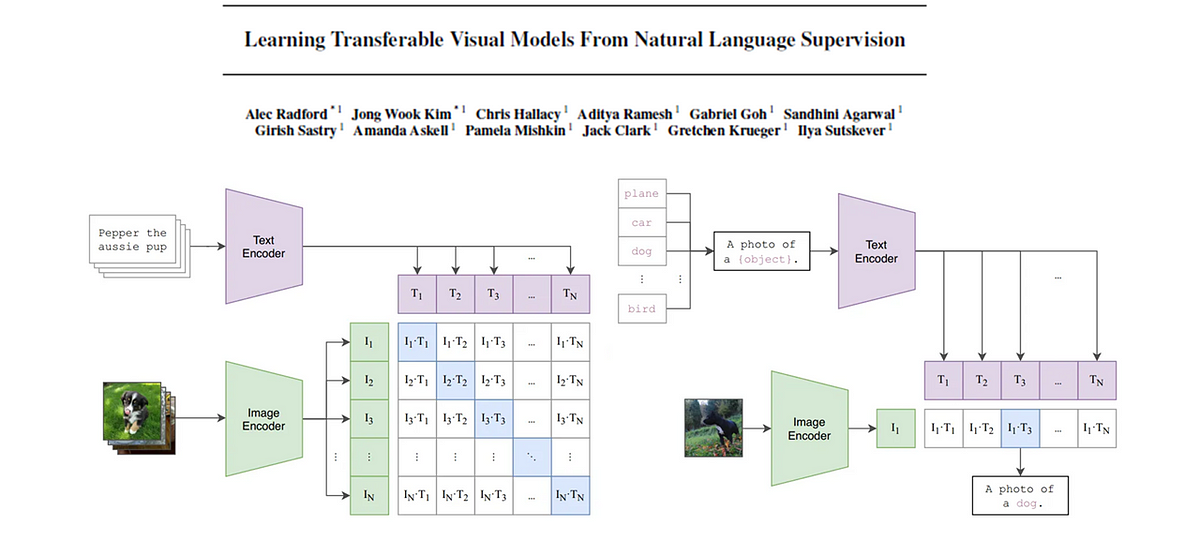
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく...

- You may be interested
- インストゥルメンタル変数の理解
- NVIDIAは、企業向けカスタム生成AIモデル...
- 「Jupyter APIを使用してノートブックをス...
- ジェミニと共に、バードはこれまで最大の...
- ソフトウェアエンジニアリングの未来 生成...
- 「TidyBotでの掃除」
- スタンフォード大学の研究者が、シェーデ...
- 「アノテーターのように考える:データセ...
- 「GeoPandasを使ったPythonにおける地理空...
- スタビリティAIは、Beluga 1およびStable ...
- 3つの難易度レベルでベクトルデータベース...
- 意思決定木の結果をより良くするための一...
- ChatGPTは自己を規制するための法律を作成...
- ChatGPTのようなChatBot Zhinaoは、何を言...
- 「機械学習におけるデータの重要性:AI革...
Find your business way
Globalization of Business, We can all achieve our own Success.