CLIP基礎モデル
CLIP Basic Model
論文要約— 自然言語監督からの転移可能な視覚モデルの学習
この記事では、CLIP(Contrastive Language-Image Pre-Training)の背後にある論文を説明します。キーコンセプトを抽出し、理解しやすく説明します。さらに、画像とデータグラフは疑問点を明確にするために注釈が付けられています。
論文: 自然言語監督からの転移可能な視覚モデルの学習
コード: https://github.com/OpenAI/CLIP
初版発行日: 2021年2月26日
著者: Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever
カテゴリ: マルチモーダル深層学習、コンピュータビジョン、自然言語処理、基盤モデル、表現学習
概要
- 文脈と背景
- 手法
- 実験
- さらなる参考資料
文脈と背景
CLIP(Contrastive Language-Image Pre-Training)は、自然言語と画像の対応関係を学習するマルチモーダルモデルです。インターネットから収集された4億のテキスト-画像ペアでトレーニングされています。この記事では後ほど詳しく説明しますが、CLIPは強力なゼロショット性能を持ち、ファインチューニングを行わずにトレーニングされたものとは異なるダウンストリームタスクで優れたパフォーマンスを発揮します。
CLIPの目標は次のとおりです:
- 自然言語処理(例:GPTファミリー、T5、BERTなど)から既知の大規模プレトレーニング技術の成功をコンピュータビジョンに適用する。
- 固定されたクラスラベルの代わりに自然言語を使用することにより、柔軟なゼロショット機能を可能にする。
なぜこれが重要かと思われるかもしれません。まず、多くのコンピュータビジョンモデルは、クラウドソースのラベル付きデータセットでトレーニングされます。これらのデータセットには通常、数十万のサンプルが含まれています。一部の例外は、数百万または数千万のサンプルの範囲です。時間とコストが非常にかかるプロセスです。一方、自然言語モデルのデータセットは通常、数桁以上大きく、インターネットからスクレイピングされます。また、オブジェクト検出モデルが特定のクラスでトレーニングされており、追加のクラスを追加する場合、新しいクラスをデータにラベル付けしてモデルを再トレーニングする必要があります。
CLIPの自然言語と画像の特徴を組み合わせた能力とゼロショット性能は、UnCLIP、EVA、SAM、Stable Diffusion、GLIDE、VQGAN-CLIPなど、多くの人気のある基盤モデルで広く採用されています。
手法
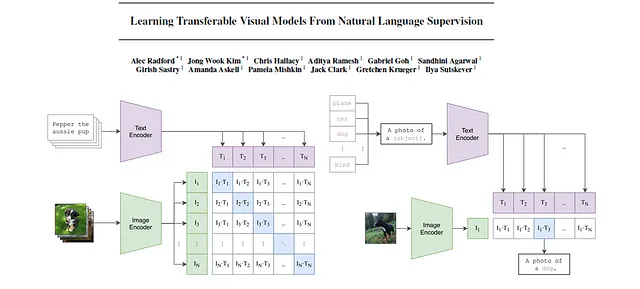
では、CLIPの手法について詳しく見ていきましょう。以下の図1に示されている図は、CLIPのアーキテクチャとトレーニングプロセスを示しています。
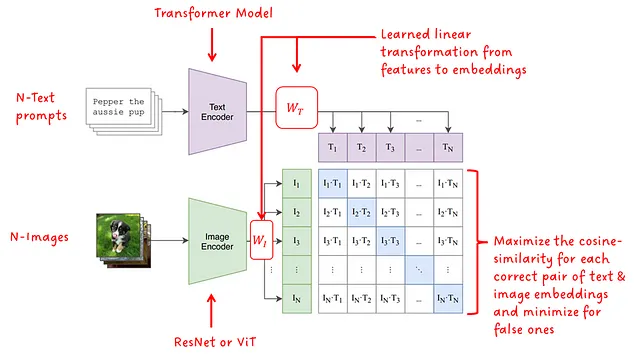
モデルのアーキテクチャは、各モダリティに対して1つのエンコーダーモデルがあります。テキストエンコーダーにはTransformerが使用され、画像エンコーダーにはResNetまたはViT(Vision Transformer)のバージョンが使用されます。各モダリティの学習済み線形変換により、特徴は対応するサイズの埋め込みに変換されます。最後に、対立するモダリティの埋め込み間のコサイン類似度が計算され、学習済みの温度スカラーでスケーリングされます。トレーニング中、マッチングペア間のコサイン類似度は最大化され、不正なペアでは最小化されます。したがって、フレームワークの名前には「対照的」という用語が含まれています。
もちろん、大規模なデータセットに加えて、成功に重要な微妙な点もあります。まず、対照的な学習アプローチは、バッチサイズNに強く依存しています。正しいサンプルと一緒に提供されるネガティブサンプルが多いほど、学習信号は強くなります。CLIPはバッチサイズ32,768でトレーニングされましたが、これは非常に大きいです。第二に、CLIPは正確な言葉の一致を学習するのではなく、テキスト全体を学習するための簡単なプロキシタスク、つまりワードバッグ(BoW)を学習します。
おもしろい事実:ResNet50x64を画像エンコーダとして使用したCLIPのバージョンは、592台のV100 GPUで18日間トレーニングされました。一方、ViTモデルを使用したバージョンは、256台のV100 GPUで12日間トレーニングされました。つまり、それぞれ1つのGPUで29年以上と8年以上(異なるバッチサイズを無視)かかります。
モデルがトレーニングされると、画像のオブジェクト分類を実行するために使用することができます。問題は、画像の分類を行うためにトレーニングされていないモデル、またはテキストプロンプトの入力クラスラベルを持たないモデルを使用して分類を行う方法です。図2はその方法を示しています:
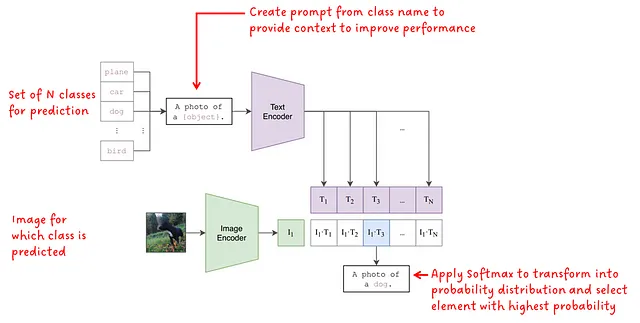
クラスラベルは、単語からなるテキストプロンプトとして表すことができます。分類タスクで使用可能なクラスをモデルに伝えるために、N個のクラスセットがモデルに入力されます。これは、固定されたラベルセットでトレーニングされた分類モデルと比べて非常に有利です。3つのクラスまたは100個のクラスを入力することができます。選択は私たち次第です。後で見るように、CLIPのパフォーマンスを向上させるために、クラスラベルはプロンプトに変換され、モデルにさらなるコンテキストを提供するために使用されます。各プロンプトはテキストエンコーダに供給され、埋め込みベクトルに変換されます。
入力画像は画像エンコーダに供給され、埋め込みベクトルを取得します。
次に、テキストと画像の埋め込みのペアごとにコサイン類似度が計算されます。取得した類似度値にSoftmaxが適用され、確率分布が形成されます。最後に、最も高い確率の値が最終的な予測として選択されます。
実験と削減
CLIPの論文では、多くの実験と削減が紹介されています。ここでは、CLIPの成功を理解するために重要だと考える5つの実験をカバーします。まず、CLIPの著者によってまとめられた主なポイントを紹介し、その後、詳細に掘り下げます:
- トレーニングの効率: CLIPは、イメージキャプションのベースラインよりもゼロショット転送で効率的です
- テキスト入力形式: プロンプトのエンジニアリングとアンサンブルにより、ゼロショットパフォーマンスが向上します
- ゼロショットパフォーマンス: ゼロショットのCLIPは完全に教師付きのベースラインと競合します
- フューショットパフォーマンス: ゼロショットのCLIPはフューショットの線形プローブよりも優れています
- 分布シフト: ゼロショットのCLIPは、標準的なImageNetモデルよりも分布シフトに対してはるかに頑健です
トレーニングの効率
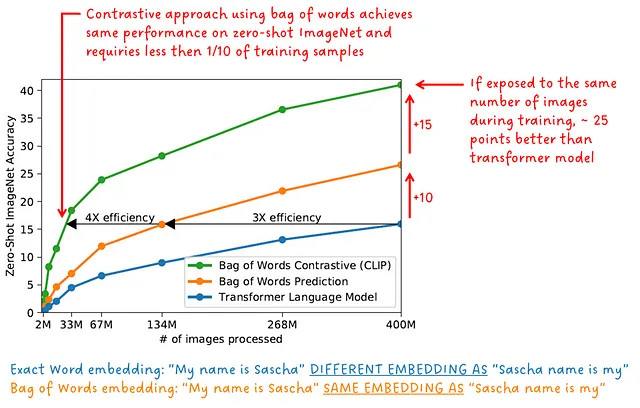
トレーニング中、画像エンコーダとテキストエンコーダは同時に単一のトレーニング目標で共同してトレーニングされます。CLIPは対照的な学習スキームを実行するだけでなく、テキストプロンプトは単語の順序に関係なく、与えられた画像に対してまとめて比較されます。つまり、それは単なる「ワードバッグ」です。「私の名前はサシャ」というフレーズは、「サシャの名前は私」と同じ埋め込みを生成します。
正確な単語とフレーズ内の位置を予測する代わりに、単語のバッグ全体を予測することははるかに簡単なプロキシ目標です。図3では、正確な単語を予測するためにトレーニングされた初期のトランスフォーマーモデル、ワードバッグを予測するためにトレーニングされた初期のトランスフォーマーモデル、およびワードバッグを使用して対照的な学習を行うCLIPモデルによるImageNet上のゼロショット精度が示されています。
「CLIPは、イメージキャプションのベースラインよりもゼロショット転送で効率的です」-CLIPの著者
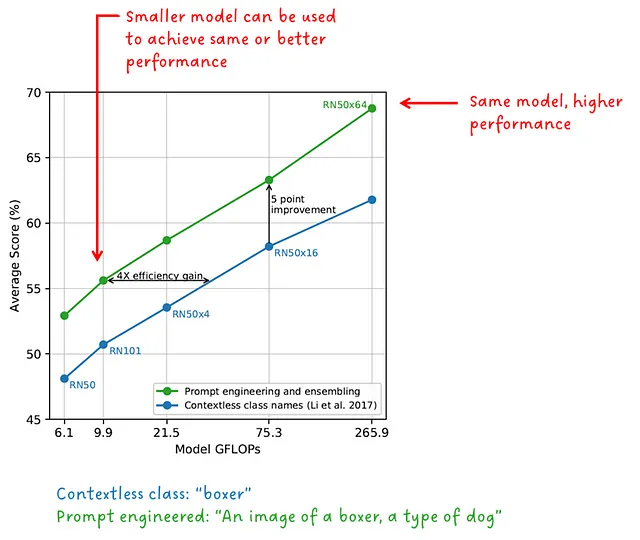
テキスト入力フォーマット
図2で見たように、オブジェクトの分類を行うために、クラスラベルはテキストプロンプトに変換されています。もちろん、これは偶然ではありません。なぜなら、CLIPは単語1つでも問題ありません。これは、言語の記述力を活用し、可能な曖昧さを解消するための文脈を提供するために行われました。例えば、単語「ボクサー」を取り上げましょう。それは犬の一種であるか、アスリートの一種であるかもしれません。CLIPの著者は、テキストプロンプトの形式が重要であり、パフォーマンスを向上させるだけでなく、効率も向上させることを示しています。
「プロンプトエンジニアリングとアンサンブルにより、ゼロショットのパフォーマンスが向上する」 – CLIPの著者
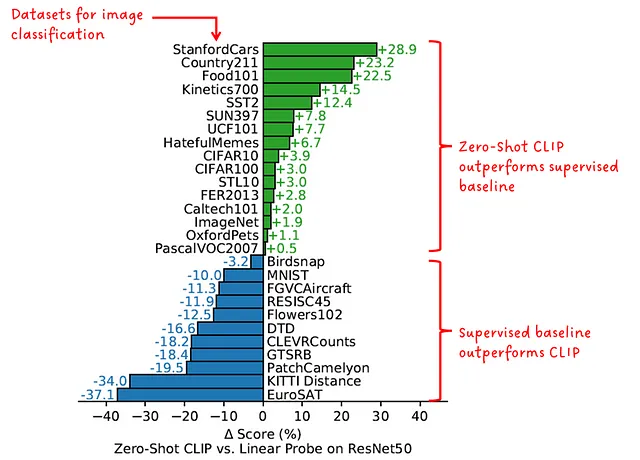
ゼロショットのパフォーマンス
別の実験では、CLIPのゼロショット画像分類のパフォーマンスを、比較対象のデータセットで特にトレーニングされたモデルと比較しました。
「ゼロショットのCLIPは完全な教師ありベースラインと競争力がある」 – CLIPの著者
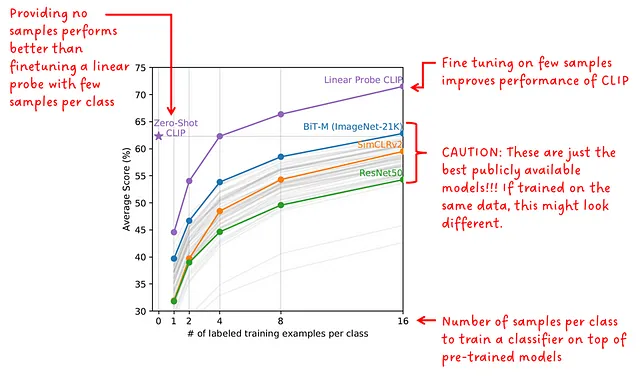
フューショットのパフォーマンス
ゼロショットの予測モデルはダウンストリームタスクで微調整されていませんが、フューショットの検出器は微調整されています。著者は、複数の公開されている事前学習済みモデルを使用し、20の異なるデータセットでのフューショットのパフォーマンスをゼロショットとフューショットのCLIPと比較しました。フューショットモデルは、クラスごとに1、2、4、8、16の例に対して微調整されています。
興味深いことに、ゼロショットのCLIPは4ショットのCLIPとほぼ同じくらいのパフォーマンスを発揮します。
CLIPを他のモデルと比較する場合、公開されている比較対象のモデル(BiT、SimCLR、ResNetなど)は、CLIPモデルとは異なる小さなデータセットで事前学習されていることを考慮する必要があります。
「ゼロショットのCLIPはフューショットの線形プローブよりも優れている」 – CLIPの著者
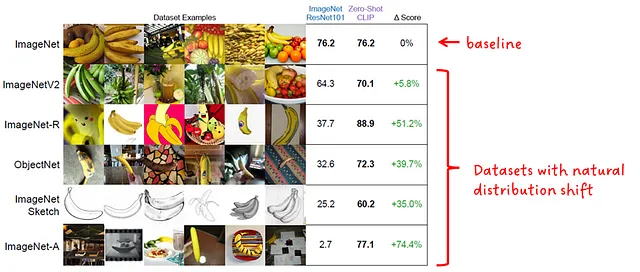
分布のシフト
一般的に、モデルの分布シフトに対する頑健性は、トレーニングされたデータのデータ分布とは異なるデータ分布上でも同様に優れたパフォーマンスを発揮する能力を指します。理想的には、同様に優れたパフォーマンスを発揮しますが、現実ではパフォーマンスが低下します。
ゼロショットのCLIPの頑健性は、ResNet101 ImageNetモデルと比較されています。両モデルは、図7に示すようなImageNetの自然な分布シフトで評価されています。
「ゼロショットのCLIPは、標準のImageNetモデルよりも分布シフトに対してはるかに頑健である」 – CLIPの著者
さらなる読み物とリソース
この記事の冒頭で述べたように、CLIPは多くのプロジェクトで広く採用されています。
CLIPを使用している論文のリストは次のとおりです:
- [UnCLIP] CLIP潜在変数を用いた階層的なテキスト条件付き画像生成
- [EVA] スケールでのマスクされた視覚表現学習の限界を探索する
- [SAM] 任意のセグメント化
- [Stable Diffusion] 潜在的拡散モデルを用いた高解像度画像合成
- [GLIDE] テキストガイド拡散モデルを用いた写真のような画像生成と編集に向けて
- [VQGAN-CLIP] 自然言語ガイダンスによるオープンドメインの画像生成と編集
また、実装に潜り込んで自分で試してみたい場合は、以下のリポジトリのリストもあります:
- OpenAIによる公式リポジトリ
- CLIPで遊ぶためのPythonノートブック
- OpenCLIP:CLIPのオープンソース実装
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- メタAIは、SeamlessM4Tを発表しましたこれは、音声とテキストの両方でシームレスに翻訳と転写を行うための基盤となる多言語・マルチタスクモデルです
- 「TADAをご紹介します 口述された説明を表現豊かな3Dアバターに変換するための強力なAI手法」
- このAI論文は、「MATLABER:マテリアルを意識したテキストから3D生成のための新しい潜在的BRDFオートエンコーダ」を提案しています
- モンテカルロ近似法:どれを選び、いつ選ぶべきか?
- 「ジェネラティブAIおよびMLモデルを使用したメールおよびモバイル件名の最適化」
- 「AIの問題を定義する方法」
- 「より良い機械学習システムの構築 – 第3章:モデリング楽しみが始まります」