TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
TaatikNet(ターティクネット) Sequence-to-Sequence learning for transliteration of Hebrew.
ヘブライ文字とラテン文字の転写間の変換という複雑なタスクに適用された文字レベルのseq2seq学習のシンプルなデモンストレーション

この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明します。コードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してください。対話型デモについては、HF SpacesのTaatikNetをご覧ください。
はじめに
NLPの興味深いタスクでは、さまざまなスタイル、言語、形式のテキスト間の変換が必要です:
- 機械翻訳(例:英語からドイツ語へ)
- テキスト要約および言い換え(例:長文から短文へ)
- スペル修正
- 抽象的な質問応答(入力:文脈と質問、出力:回答のテキスト)
これらのタスクは、シーケンス対シーケンス(Seq2seq)学習として一般的に知られています。これらのタスクでは、入力と目標出力は文字列であり、長さが異なる場合や一対一の対応関係がない場合があります。
例えば、文とその翻訳のリスト、つづりが間違って修正されたテキストの多くの例などのペアのデータセットがあるとします。十分な量のデータがあれば、モデルは新しい入力にも一般化できるように学習することができるため、これらにニューラルネットワークを容易にトレーニングすることができます。最小限の努力でseq2seqモデルをトレーニングする方法を見てみましょう。PyTorchとHugging Faceのtransformersライブラリを使用します。
- Meet ChatGLM2-6B:オープンソースのバイリンガル(中国語-英語)チャットモデルChatGLM-6Bの第2世代バージョンです
- 専門AIトレーニングの変革- LMFlowの紹介:優れたパフォーマンスのために大規模な基盤モデルを効率的に微調整し、個別化するための有望なツールキット
- プロンプトエンジニアリングへの紹介
特に興味深いユースケースに焦点を当てます:ヘブライ文字とラテン文字の変換を学習します。このタスクの概要を以下で説明しますが、ここで紹介されるアイデアとコードはこの特定のケースに限らずに有用です。このチュートリアルは、例のデータセットからのseq2seq学習を行いたい人にとって有用です。
私たちのタスク:ヘブライ文字の転写
興味深くかつ比較的新しいユースケースを使用してseq2seq学習をデモンストレーションするために、転写を適用します。一般的に、転写は異なる文字体系間の変換を指します。英語はラテン文字で書かれていますが(「ABC…」)、世界の言語はさまざまな書記体系を使用しています。以下に示すように:
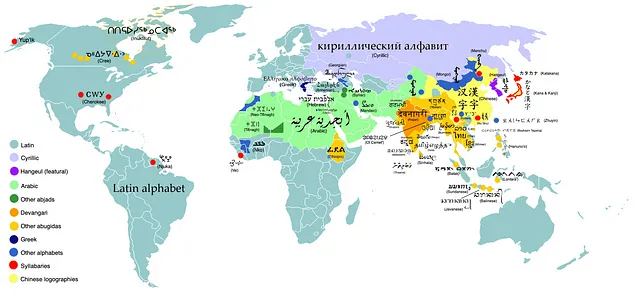
異なる文字体系で書かれた言語の単語をラテン文字で書き出したい場合はどうすればよいでしょうか?この課題は、ハヌカーというユダヤ教の祭りの名前を書くためのさまざまな方法によって示されています。Wikipediaの記事の現在の紹介は次のようになっています:
ハヌカー( /ˈhɑːnəkə/ ; ヘブライ語 : חֲנֻכָּה, 現代ヘブライ語 : Ḥanukka, ティベリア語 : Ḥănukkā)は、2世紀BCEにセレウコス朝に対するマカバイ戦争の開始時にエルサレムの回復と第二神殿の再奉献を記念するユダヤ教の祭りです。
ヘブライ語の単語「חֲנֻכָּה」は、ハヌカー、ハヌッカ、ハヌッカー、Ḥanukkaなど、さまざまなバリアントのラテン文字転写として表されることがあります。ヘブライ語や他の多くの文字体系では、文字間の変換が複雑であり、単純な一対一のマッピングではありません。
ヘブライ語の場合、複雑なルールセットを使用して、ニクド(母音記号)をラテン文字に転写することは大部分可能ですが、これにはいくつかの例外があり、これが見かけによらず複雑になります。さらに、母音記号なしでテキストを転写しようとしたり、逆のマッピングを行おうとしたりする(例:Chanukah → חֲנֻכָּה)のは、多くの可能な正しい出力があるため、はるかに困難です。
幸いなことに、既存のデータに深層学習を適用することで、わずかなコードだけでこの問題を解決することができます。それでは、どのようにして seq2seqモデルであるTaatikNetをトレーニングして、ヘブライ語テキストとラテン文字転写の変換方法を独自に学習するか を見てみましょう。これは 文字レベルのタスク であることに注意してください。ヘブライ語テキストと転写の異なる文字間の相関関係についての推論を含むためです。これについては、後述で詳しく説明します。
ちなみに、UNIKUDという、母音記号のないヘブライ語テキストに母音記号を追加するためのモデルをご存知かもしれません。これらのタスクにはいくつかの類似点がありますが、主な違いは、UNIKUDが文字レベルの分類を行い、各文字ごとにその隣接に1つ以上の母音記号を挿入するかどうかを学習している点です。対照的に、私たちの場合、転写の複雑な性質により、入力と出力のテキストが厳密に対応しない場合があるため、ここではseq2seq学習を使用しています(単に文字ごとの分類ではない)。
データ収集
機械学習のタスクのほとんどでは、入力とモデルの望ましい出力の多くの例を収集することができれば幸運です。これにより、教師あり学習を使用してモデルをトレーニングすることができます。
単語やフレーズに関する多くのタスクにおいて、Wiktionaryおよびその多言語の対応物(ウィキペディアと辞書の組み合わせと考える)は素晴らしいリソースです。特に、ヘブライ語のWiktionary(ויקימילון)には、次のような構造化された文法情報を含むエントリがあります:
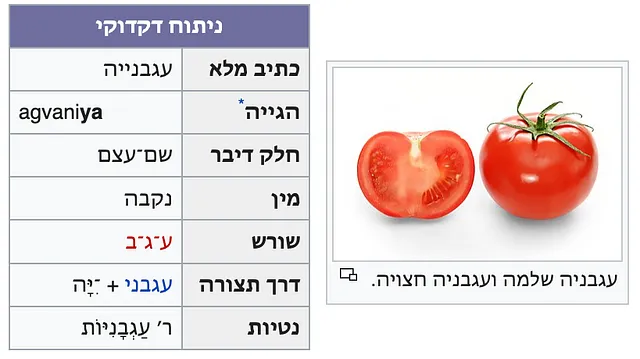
特に、これにはラテン文字転写( agvani ya、太字はアクセントを示しています)が含まれます。また、ニクド(母音文字)を含むセクションタイトルもあります。これにより、私たちがトレーニングに必要な(自由に使用できる)データを得ることができます。
データセットを作成するために、Wikimedia REST APIを使用してこれらのアイテムをスクレイピングします(例はこちら)。ウィクショナリエントリの元のテキストは、派生作品のための許容ライセンス(CCおよびGNUライセンス、詳細はこちら)を持っており、共有同一条件のライセンスが必要です。一般的に、データスクレイピングを行う場合は、許容されるライセンスのデータを使用し、適切にスクレイピングし、派生作品の正しいライセンスを使用していることを確認してください。
このデータには、次のようなさまざまな前処理ステップがあります:
- ウィキマークアップとメタデータの削除
- 強調表示をアクセント記号(例:agvani ya → agvaniyá)で表すように変更
- Unicode NFC正規化により、ヘブライ文字ベート(U+05D1)+ ヘブライ文字ダゲッシュまたはマピク(U+05BC)とヘブライ文字ベート(U+FB31)+ ダゲッシュを持つヘブライ文字ベートなど、外観が同じである文字を統一します。これらを比較するには、Unicode文字を表示するツールにコピーして貼り付けることができます。また、ヘブライ語のゲレシュ(׳)とアポストロフィ(’)など、外観が似た句読点も統一します。
- 複数の単語からなる表現を個々の単語に分割する
データスクレイピングと前処理の後、約15,000の単語-転写ペアが残ります(csvファイルはこちらで入手可能)。いくつかの例を以下に示します:

転写は一貫性やエラーのないものではありません。例えば、強勢は一貫されず、しばしば正しくマークされていません。また、さまざまな綴りの規則が使用されています(例: ח は h、kh、または ch に対応する場合があります)。これらを修正しようとせず、単にモデルに直接与えてそれ自体で意味を理解させます。
トレーニング
データセットができたので、プロジェクトの「肉付け」に取り掛かりましょう。データに対して seq2seq モデルをトレーニングします。最終モデルはヘブライ語の「転写」という意味の תעתיק taatik にちなんで TaatikNet と呼びます。TaatikNet のトレーニングについてはここで高レベルで説明しますが、アノテーション付きのトレーニングノートブックも参照することを強くお勧めします。トレーニングコード自体は非常に短く、具体的です。
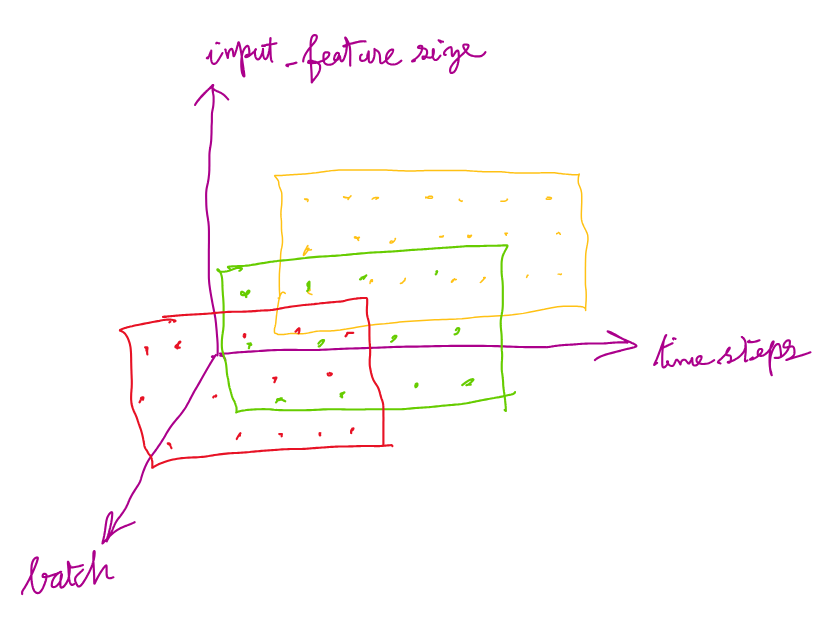
NLP タスクで最先端の結果を得るための一般的なパラダイムは、事前にトレーニングされたトランスフォーマーニューラルネットワークを取り、タスク固有のデータセットで微調整を続けるというものです。seq2seq タスクでは、基本モデルとしてエンコーダーデコーダーモデルが最も自然な選択です。T5 や BART などの一般的なエンコーダーデコーダーモデルは、テキストをトークン化します(サブワードトークン、おおよそ単語または単語のチャンクに分割します)。これは、個々の文字レベルでの推論が必要な私たちのタスクには適していません。そのため、トークナイザーフリーの ByT5 エンコーダーデコーダーモデル(論文、HF モデルページ)を使用します。このモデルは、バイト(おおよそ文字ですが、Unicode グリフがバイトにマッピングされる方法については、Joel Spolsky のエクセレントな記事「Unicode と文字セット」を参照してください)単位で計算を行います。
まず、PyTorch の Dataset オブジェクトを作成してトレーニングデータをカプセル化します。データセットの csv ファイルからデータを単純にラップすることもできますが、モデルのトレーニング手順を興味深くするためにいくつかのランダムな変換を追加します:
def __getitem__(self, idx): row = self.df.iloc[idx] out = {} if np.random.random() < 0.5: out['input'] = row.word if np.random.random() < 0.2 else row.nikkud out['target'] = row.transliteration else: out['input'] = randomly_remove_accent(row.transliteration, 0.5) out['target'] = row.nikkud return outこの変換により、TaatikNet はヘブライ文字またはラテン文字の入力を受け入れ、対応する出力を計算できるようになります。また、母音記号やアクセントをランダムに省略することで、モデルがそれらの欠如に対して堅牢であるようにトレーニングします。一般的に、ランダムな変換は、データセットのすべての可能な入力と出力を事前に計算せずに、ネットワークがさまざまなタイプの入力を処理する方法を学習させたい場合に便利なトリックです。
Hugging Face パイプライン API を使用してベースモデルをロードします。単一のコード行です:
pipe = pipeline("text2text-generation", model='google/byt5-small', device_map='auto')データの整理とハイパーパラメータの設定(エポック数、バッチサイズ、学習率)の後、データセット上でモデルをトレーニングし、各エポック後に選択した結果を出力します。トレーニングループは、evaluate(…) 関数を除いて、標準的な PyTorch です。evaluate(…) 関数は他の場所で定義し、モデルの現在の予測結果をさまざまな入力で出力します:
for i in trange(epochs): pipe.model.train() for B in tqdm(dl): optimizer.zero_grad() loss = pipe.model(**B).loss losses.append(loss.item()) loss.backward() optimizer.step() evaluate(i + 1)トレーニングの初期エポックと終了時のいくつかの結果を比較します:
Epoch 0 before training: kokoro => okoroo-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oroa-oEpoch 0 before training: יִשְׂרָאֵל => אלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאלאEpoch 0 before training: ajiliti => ajabiliti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti siti sitEpoch 1: kokoro => מְשִׁיתEpoch 1: יִשְׂרָאֵל => maráEpoch 1: ajiliti => מְשִׁיתEpoch 2: kokoro => כּוֹקוֹרְבּוֹרוֹרEpoch 2: יִשְׂרָאֵל => yishishálEpoch 2: ajiliti => אַדִּיטִיEpoch 5: kokoro => קוֹקוֹרוֹEpoch 5: יִשְׂרָאֵל => yisraélEpoch 5: ajiliti => אֲגִילִיטִיEpoch 10 after training: kokoro => קוֹקוֹרוֹEpoch 10 after training: יִשְׂרָאֵל => yisraélEpoch 10 after training: ajiliti => אָגִ'ילִיטִיモデルの学習前は、予想通りであるが、意味のない出力が生成されます。学習中は、モデルが最初に正しく見えるヘブライ語とラテン文字転写の構築方法を学ぶことを確認できますが、それらの間の関連性を学ぶのには時間がかかります。また、ギメルとゲレッシュ(ジ)に対応するג’(ギメル+ゲレッシュ)などの稀なアイテムの学習にも時間がかかります。
注意事項:トレーニング手法の最適化は試みていません。ハイパーパラメータはかなり任意に選ばれ、厳密な評価のための検証セットやテストセットは設定していません。これは単にseq2seqトレーニングの簡単な例と転写学習の概念実証を提供するためのものであり、ハイパーパラメータの調整と厳密な評価は、この下の制約セクションで言及されたポイントと共に将来の研究の有望な方向性となるでしょう。
結果
以下にいくつかの例を示し、ヘブライ語テキスト(母音ありまたはなし)とラテン文字転写の相互変換を両方の方向で示します。HF SpacesのインタラクティブデモでTaatikNetを試すこともできます。デコーディングにはビームサーチ(5ビーム)が使用され、推論は各単語ごとに実行されます。
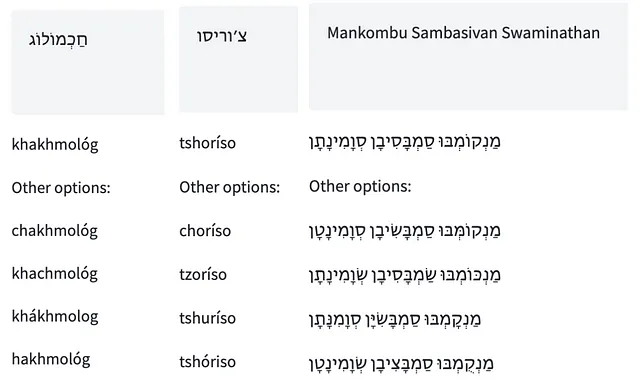
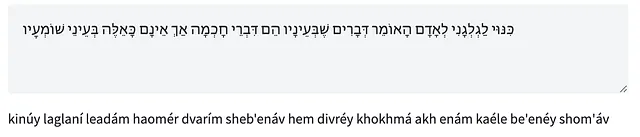
制約とさらなる展望
簡単さのために、TaatikNetは詳細な調整を行わずに最小限のseq2seqモデルとして実装しました。ただし、ヘブライ語テキストと転写の変換結果を改善することに興味がある場合、将来の研究のために多くの有望な方向性があります:
- TaatikNetは、文字または音の対応関係に基づいて適切なスペル(ヘブライ語またはラテン文字転写)を推測するだけです。ただし、文脈に基づいて転写から正しいヘブライ語テキストに変換したい場合(例:zot dugma → זאת דוגמא、*זות דוגמעのような誤ったスペルではなく)、辞書へのアクセスを組み合わせた生成またはヘブライ語の文とそれらのラテン文字転写のペアのトレーニングを行うことで文脈の手がかりを学習するなど、可能な方法が考えられます。
- 異常な形式の入力は、TaatikNetのデコーディングをループさせる可能性があります。例:drapapap → דְּרַפָּפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּאפָּアフィックス。これは、トレーニング中の拡張、多様なトレーニングデータ、またはトレーニングまたはデコーディング中のサイクルの一貫性の使用によって処理できるかもしれません。
- TaatikNetは、トレーニングデータにかなり珍しい慣習を処理できない場合があります。例えば、ז’(ザイン+ゲレッシュ)を正しく処理できないことがよくあります。これは適合不足を示している可能性があり、困難な例を強調するためにトレーニング中にサンプルウェイトを使用することが役立つかもしれません。
- seq2seqトレーニングの利便性は、解釈可能性と堅牢性のコストとして現れます。TaatikNetがどのように判断を下しているのかを正確に知り、それが一貫して適用されることを確認することが望ましいかもしれません。興味深い可能な拡張機能は、一連のルールベースの条件(例:文字Xが文脈Yで見られた場合、Zを書く)にその知識を蒸留することです。おそらく、最近のコード事前学習済みLLMは、これに役立つかもしれません。
- 「完全なスペル」と「不完全なスペル」(כתיב מלא / חסר)を処理していません。ヘブライ語の単語は、母音記号を使用して書かれているかどうかによってわずかに異なるスペルがされることがあります。ヘブライ語テキストでトレーニングされたモデルでは、「完全な」スペル(母音なし)と「不完全な」スペル(母音あり)でトレーニングすることが理想的です。ヘブライ語テキストでトレーニングされたモデルにこれらのスペルを処理するためのアプローチとして、UNIKUDを参照してください。
もしこれらのアイデアや他のアイデアを試して改善が見られた場合は、ぜひお知らせいただければ非常に興味を持ちます。こちらでクレジットさせていただきますので、この記事の下にある私の連絡先までお気軽にお問い合わせください。
結論
教師あり学習を用いてseq2seqモデルを訓練することは非常に簡単であることがわかりました。大量のペア例から一般化することを教えるだけです。私たちの場合、文字レベルのモデル(ベースのByT5モデルから微調整したTaatikNet)を使用しましたが、ほぼ同じ手順とコードを機械翻訳などのより一般的なseq2seqタスクにも使用することができます。
このチュートリアルから私が学んだように、あなたもたくさん学んでいただければ幸いです!ご質問、コメント、提案があればお気軽にお問い合わせください。私の連絡先情報は以下のウェブサイトでご確認いただけます。
Morris Alper, MScは、テルアビブ大学の博士課程学生で、マルチモーダル学習(NLP、コンピュータビジョン、その他のモダリティ)の研究を行っています。詳細な情報や連絡先情報については、彼のウェブページをご覧ください:https://morrisalp.github.io/
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles