複数の画像やテキストの解釈 Multimodal Learning
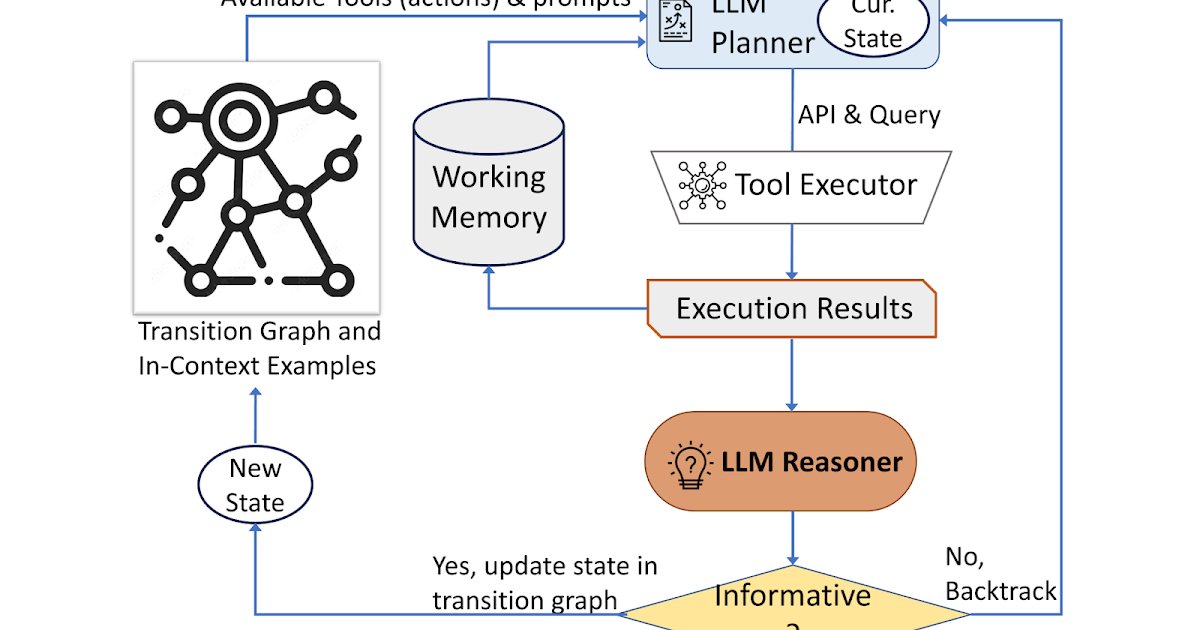
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規...

コード生成を通じたモジュラーなビジュアル質問応答
投稿者:UCバークレーの博士課程生であるSanjay SubramanianとGoogle Researchの研究科学者であるArsha Nagrani、Perception ...
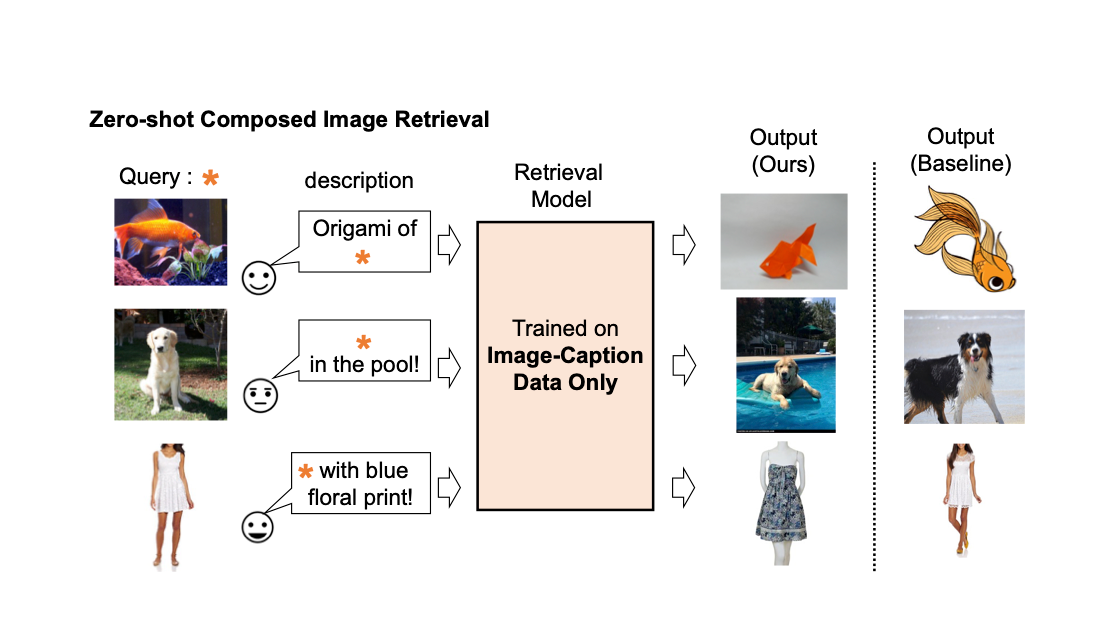
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検...
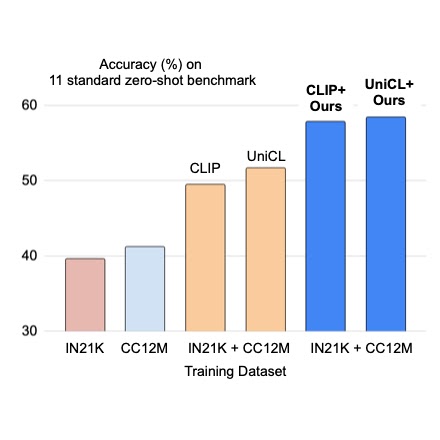
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像...

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、Pa...
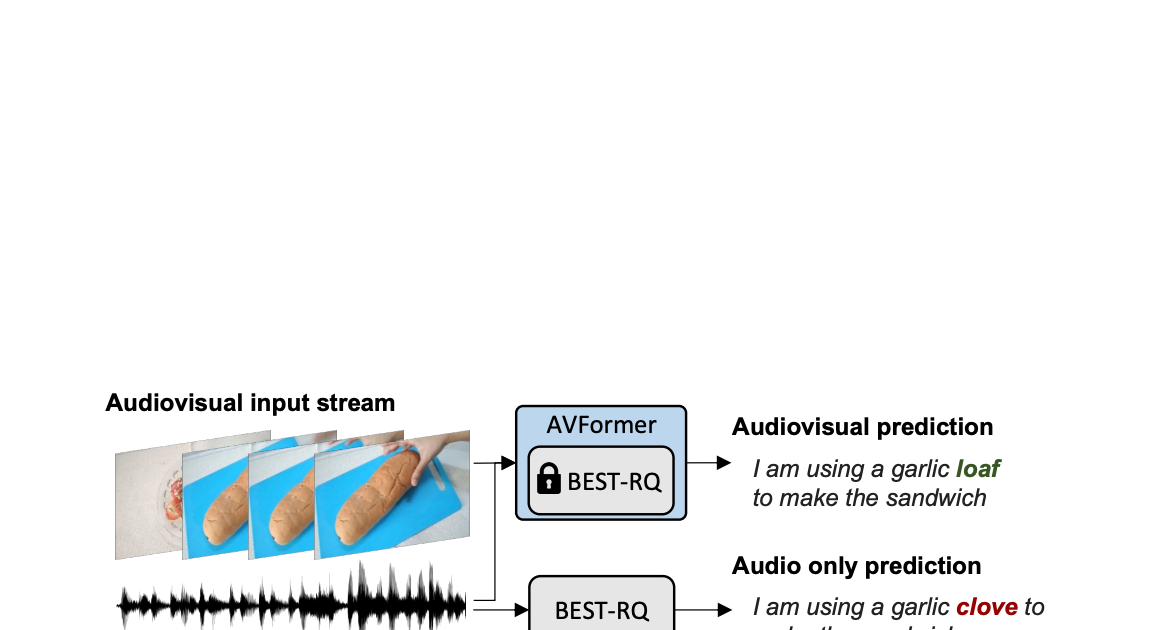
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビ...

- You may be interested
- なぜ私たちはHugging Face Inference Endp...
- 「MITのリキッドニューラルネットワークが...
- 「AWS reInvent 2023での生成的AIとMLのガ...
- Inflection AIは、テックの巨人や業界の巨...
- AI研究でα-CLIPが公開されました ターゲテ...
- 「PyTorchモデルのパフォーマンス分析と最...
- 「IBMとNASAが連携し、地球科学GPTを創造...
- 「最初のAIエージェントを開発する:Deep ...
- 「時代遅れのパスワードの慣行が広まって...
- ディープラーニングのマスタリング:分岐...
- 人工知能(AI)におけるトップの物体検出...
- 「脳活動計測と仮想現実の統合」
- 「GROOTに会おう:オブジェクト中心の3D先...
- スタンフォード大学とGoogleからのこのAI...
- 「機械学習のための現実世界のデータ収集...
Find your business way
Globalization of Business, We can all achieve our own Success.