UCバークレーとMeta AIの研究者らは、トラックレット上で3Dポーズとコンテキスト化された外観を融合することにより、ラグランジュアクション認識モデルを提案しています
Researchers from UC Berkeley and Meta AI propose a Lagrangian action recognition model by fusing 3D poses and contextually-appropriate appearance on a tracklet.


流体力学では、ラグランジュ流体場形式とオイラー流体場形式を区別することが慣習となっています。Wikipediaによると、「流体場のラグランジュ仕様は、観察者が離散的な流体粒子を空間および時間を通じて流れるように追跡する方法であり、粒子の経路線は時間の経過に伴ってその位置をグラフ化することで決定できます。これは、舟に座って川を漂っているようなものです。一方、流体場のオイラー仕様は、時間が経過するにつれて流体が流れる空間の場所に特に重点を置いて流体運動を分析する方法です。川岸に立って流れる水を観察すると、これを想像することができます。
これらの考え方は、人間の行動の記録をどのように調べるかを理解する上で重要です。オイラーの視点によると、彼らは(x、y)または(x、y、z)など、特定の場所の特徴ベクトルに注目し、その場所で空間で静止したまま時間の経過を考慮します。一方、ラグランジュの視点によると、人間などのエンティティを時空間を超えて追跡し、関連する特徴ベクトルを追跡します。たとえば、活動認識の以前の研究は、しばしばラグランジュの視点を採用しました。ただし、3D時空間畳み込みに基づくニューラルネットワークの発展により、SlowFast Networksのような最先端の方法では、オイラーの視点が一般的になりました。トランスフォーマー・システムへの切り替え後も、オイラー視点が維持されています。
これは、トランスフォーマーのトークナイズ化プロセス中に、「ビデオ分析における単語の相当物は何であるべきか」という問いを再検討する機会を提供してくれます。Dosovitskiyらは、画像パッチを良い選択肢として推奨し、その概念をビデオに拡張すると、時空立方体がビデオに適している可能性があります。しかし、彼らは自分たちの研究で、人間の行動を調べる際にはラグランジュの視点を採用しています。これにより、彼らはエンティティの時間的な経過を考えています。この場合、エンティティは高レベルなものであるか、人間のようなもの、あるいはピクセルやパッチのような低レベルなものであるかもしれません。彼らは、「人間としてのエンティティ」のレベルで機能することを選択しました。これは、人間の行動を理解することに興味があるためです。
- AIの汎化ギャップに対処:ロンドン大学の研究者たちは、Spawriousという画像分類ベンチマークスイートを提案しましたこのスイートには、クラスと背景の間に偽の相関が含まれます
- テキストから画像合成を革新する:UCバークレーの研究者たちは、強化された空間的および常識的推論のために、大規模言語モデルを2段階の生成プロセスで利用しています
- Meta AIとSamsungの研究者が、学習率適応のための2つの新しいAI手法、ProdigyとResettingを導入し、最先端のD-Adaptation手法の適応率を改善しました
これを行うために、彼らは、人物の動きをビデオで分析し、それを利用して彼らの活動を識別する技術を使用しています。最近リリースされた3D追跡技術PHALPとHMR 2.0を使用してこれらの軌跡を取得することができます。図1は、PHALPが個人のトラックを3Dに昇格させることでビデオから人のトラックを回収する方法を示しています。彼らはこれらの人物の3Dポーズと位置を基本要素として各トークンを構築することができます。これにより、モデル(この場合、トランスフォーマー)は、身元、3D姿勢、3D位置にアクセスできる様々な個人に属するトークンを入力として受け取る柔軟なシステムを構築することができます。シナリオ内の人物の3D位置を使用することで、人間の相互作用について学ぶことができます。
トークナイズベースのモデルは、ポーズデータにアクセスできる旧来のベースラインを上回り、3Dトラッキングを使用することができます。人物の位置の進化は強力な信号ですが、一部の活動には周囲の環境や人物の見た目に関する追加の背景知識が必要です。そのため、立場と直接的に派生した人物とシーンの外観に関するデータを組み合わせることが重要です。これを行うために、彼らは、ラグランジュの枠組みで、人物と環境の文脈化された外観に基づく補足データを供給するために、最先端のアクション認識モデルを追加で使用しています。彼らは、各トラックのルートを激しく実行することで、各トラック周辺の文脈化された外観属性を記録します。
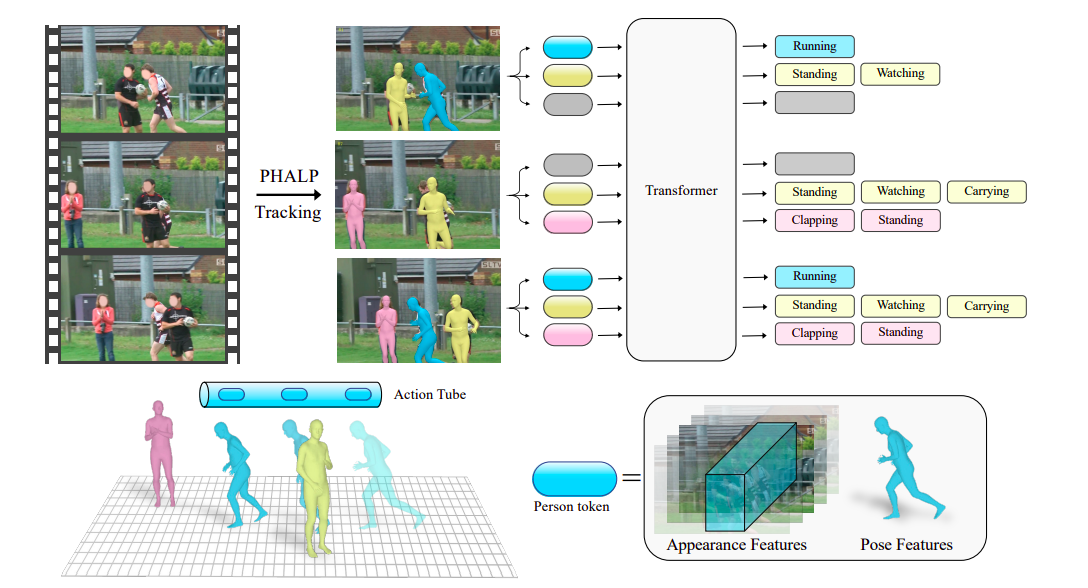
彼らのトークンは、アクション認識バックボーンによって処理され、個人の3Dスタンスに関する明示的な情報と、ピクセルからの高頻度の外観データを含んでいます。AVA v2.2の難しいデータセットでは、彼らのシステム全体が先行研究を2.8 mAPの大幅なマージンで超えています。全体的に、彼らの主要な貢献は、人間の動きを理解するためにトラッキングと3Dポーズの利点を強調する方法論の導入です。UCバークレーとMeta AIの研究者は、人々のトラックを使用して彼らの行動を予測するLagrangian Action Recognition with Tracking(LART)メソッドを提案しています。彼らのベースラインバージョンは、トラックレスの軌跡とビデオ内の人物の3Dポーズ表現を使用した以前のベースラインを上回っています。さらに、ビデオからの外観とコンテキストを単独で考慮する標準的なベースラインが、提案されたLagrangian視点のアクション検出と簡単に統合でき、主流のパラダイムを大幅に改善できることを示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- サリー大学の研究者たちは、機械学習における画像認識を革新するスケッチベースの物体検知ツールを開発しました
- LinkedInとUCバークレーの研究者らは、AIによって生成されたプロフィール写真を検出する新しい方法を提案しています
- 私の博士号入学への道 – 人工知能
- Google研究者がAudioPaLMを導入:音声技術における革新者 – 聞き、話し、そして前例のない精度で翻訳する新しい大規模言語モデル
- 計算機の進歩により、研究者はより高い信頼性で気候をモデル化することができるようになります
- ロボットの犬がMJスタイルでムーンウォークをする:このAI研究は、コードで表現された報酬を、LLMと最適化ベースのモーションコントローラーの間の柔軟なインターフェースとして使用することを提案しています
- メリーランド大学カレッジパーク校の新しいAI研究では、人間の目の反射から3Dシーンを再構成することができるAIシステムが開発されました






