Amazon SageMaker Data WranglerのSnowflakeへの直接接続でビジネスインサイトまでの時間を短縮してください
Reduce time to business insights by directly connecting Amazon SageMaker Data Wrangler to Snowflake.
Amazon SageMaker Data Wranglerは、コードを書くことなく、データの選択とクリーニング、特徴エンジニアリングを行い、機械学習(ML)ワークフローでのデータ準備を自動化することができる単一のビジュアルインターフェースであり、データの準備に必要な時間を週から数分に短縮します。
SageMaker Data Wranglerは、MLを実行したいユーザーに人気のあるデータソースであるSnowflakeをサポートしています。SageMaker Data WranglerからSnowflakeの直接接続を起動し、顧客体験を向上させるために、この機能をリリースします。この機能がリリースされる前は、管理者は、MLのためのフィーチャーを作成するために、Snowflakeに接続するための初期ストレージ統合を設定する必要がありました。これには、Amazon S3バケットのプロビジョニング、AWS Identity and Access Management(IAM)アクセス権限、個々のユーザーのSnowflakeストレージ統合、およびAmazon S3のデータコピーを管理またはクリーンアップするための継続的なメカニズムが含まれます。このプロセスは、厳格なデータアクセス制御と多数のユーザーを持つ顧客にとってスケーラブルではありません。
この投稿では、SnowflakeのSageMaker Data Wrangler内の直接接続が、管理者の体験とデータサイエンティストのデータからビジネスインサイトへのMLの旅を簡素化する方法を示します。
ソリューションの概要
このソリューションでは、SageMaker Data Wranglerを使用して、MLのためのデータ準備を高速化し、Amazon SageMaker Autopilotを使用して、データに基づいてMLモデルを自動的に構築、トレーニング、微調整することができます。両方のサービスは、ML実践者の生産性を高め、MLの価値を迅速に実現するように設計されています。また、SageMaker Data WranglerからSnowflakeへの簡素化されたデータアクセスを、直接接続でクエリしてMLのためのフィーチャーを作成することにより、デモンストレーションします。
- バイオメディカル文献のアトラスは、捏造された研究を追跡するのに役立つかもしれません
- Pythonの依存関係管理:どのツールを選ぶべきですか?
- 注目すべきプラグイン:データ分析を自動化するChatGPTプラグイン
以下の図を参照して、Snowflake、SageMaker Data Wrangler、およびSageMaker Autopilotを使用したローコードMLプロセスの概要を確認してください。
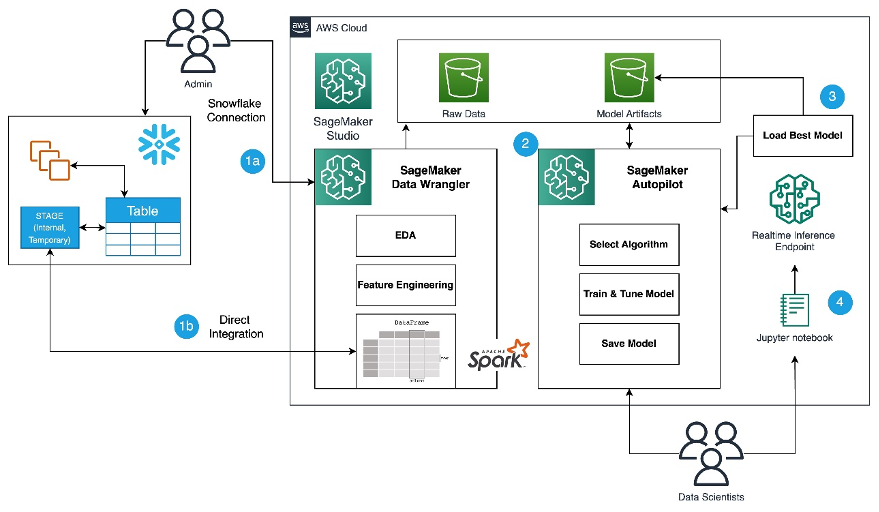
以下の手順が含まれます。
- データ準備と特徴エンジニアリングのタスクにSageMaker Data Wranglerに移動します。
- SageMaker Data WranglerでSnowflake接続を設定します。
- SageMaker Data WranglerでSnowflakeのテーブルを探索し、MLデータセットを作成し、特徴エンジニアリングを実行します。
- SageMaker Data WranglerとSageMaker Autopilotを使用してモデルをトレーニングおよびテストします。
- 最適なモデルをリアルタイム推論エンドポイントにロードして、予測を行います。
- Pythonノートブックを使用して、起動したリアルタイム推論エンドポイントを呼び出します。
前提条件
この投稿には、管理者には以下の前提条件が必要です。
- Snowflakeの仮想ウェアハウス、ユーザー、およびロールを作成し、このユーザーがデータベースを作成する権限を付与する管理者権限を持つSnowflakeユーザー。管理設定の詳細については、Import data from Snowflakeを参照してください。
- 管理者権限を持つAWSアカウント。
- お好みのAWSリージョンにあるSnowflake Enterpriseアカウントで、
ACCOUNTADMINアクセスがあること。 - SageMaker Data WranglerでSnowflake OAuthアクセスを使用する場合は、OAuthアイデンティティプロバイダを設定するために、Import data from Snowflakeを参照してください(オプション)。
- Snowflake、基本的なSQL、Snowsight UI、およびSnowflakeオブジェクトについての熟練度。
データサイエンティストは、次の前提条件を満たす必要があります。
- Amazon SageMaker、Amazon SageMaker Studioのインスタンス、およびSageMaker Studioのユーザーへのアクセス。前提条件については、Get Started with Data Wranglerを参照してください。
- AWSサービス、ネットワーキング、およびAWS Management Consoleについての熟練度。Python、Jupyterノートブック、およびMLの基本的な知識。
最後に、Snowflakeのためにデータを準備する必要があります
- 不正なクレジットカード取引を検出するためのMLモデルを構築するために、Kaggleからのクレジットカードトランザクションデータを使用し、顧客が購入しなかったアイテムに対して料金を請求されないようにします。データセットには、ヨーロッパのカード所有者による2013年9月のクレジットカードトランザクションが含まれています。
- SnowSQLクライアントを使用して、データセットをSnowflakeテーブルにアップロードするために、ローカルマシンにインストールする必要があります。
以下の手順は、データセットを準備してSnowflakeデータベースにロードする方法を示しています。これは一度のセットアップです。
Snowflakeテーブルとデータの準備
この一度のセットアップについては、以下の手順を完了してください:
-
まず、管理者としてSnowflake仮想ウェアハウス、ユーザー、およびロールを作成し、データサイエンティストなどの他のユーザーがMLユースケースのためのデータベースを作成し、データをステージングできるようにアクセスを許可します。
-- ロールとユーザーを作成するには、ROLE SECURITYADMIN を使用します USE ROLE SECURITYADMIN; -- 新しいロール 'ML Role' を作成する CREATE OR REPLACE ROLE ML_ROLE COMMENT='ML Role'; GRANT ROLE ML_ROLE TO ROLE SYSADMIN; -- 新しいユーザーとパスワードを作成し、ロールをユーザーに付与する CREATE OR REPLACE USER ML_USER PASSWORD='<REPLACE_PASSWORD>' DEFAULT_ROLE=ML_ROLE DEFAULT_WAREHOUSE=ML_WH DEFAULT_NAMESPACE=ML_WORKSHOP.PUBLIC COMMENT='ML User'; GRANT ROLE ML_ROLE TO USER ML_USER; -- ロールに権限を付与する USE ROLE ACCOUNTADMIN; GRANT CREATE DATABASE ON ACCOUNT TO ROLE ML_ROLE; -- AI / ML 作業用に Warehouse を作成する USE ROLE SYSADMIN; CREATE OR REPLACE WAREHOUSE ML_WH WITH WAREHOUSE_SIZE = 'XSMALL' AUTO_SUSPEND = 120 AUTO_RESUME = true INITIALLY_SUSPENDED = TRUE; GRANT ALL ON WAREHOUSE ML_WH TO ROLE ML_ROLE; -
データサイエンティストとして、SageMaker Data Wranglerからデータにアクセスするために、クレジットカードトランザクションをSnowflakeデータベースにインポートするデータベースを作成します。説明のために、Snowflakeデータベースを
SF_FIN_TRANSACTIONという名前で作成します。-- ロールと Warehouse を選択する USE ROLE ML_ROLE; USE WAREHOUSE ML_WH; -- 金融取引をインポートするためのDBを作成する CREATE DATABASE IF NOT EXISTS sf_fin_transaction; -- CSV ファイル形式を作成する create or replace file format my_csv_format type = csv field_delimiter = ',' skip_header = 1 null_if = ('NULL', 'null') empty_field_as_null = true compression = gzip; -
データセットCSVファイルをローカルマシンにダウンロードし、データをデータベーステーブルにロードするためのステージを作成します。インポートコマンドを実行する前に、ダウンロードされたデータセットの場所を指すファイルパスを更新してください。
-- トランザクションのCSVファイルを格納するSnowflakeの内部ステージを作成する CREATE OR REPLACE STAGE my_stage FILE_FORMAT = my_csv_format; -- ステージにファイルをインポートする -- このコマンドは、Web UIではなくSnowSQLクライアントから実行する必要があります PUT file:///Users/*******/Downloads/creditcard.csv @my_stage; -- インポートが成功したかどうかを確認する LIST @my_stage; -
credit_card_transactionsという名前のテーブルを作成します。-- テーブルを作成し、CSVトランザクションファイルにマップされる列を定義する create or replace table credit_card_transaction ( Time integer, V1 float, V2 float, V3 float, V4 float, V5 float, V6 float, V7 float, V8 float, V9 float, V10 float,V11 float,V12 float, V13 float,V14 float,V15 float, V16 float,V17 float,V18 float, V19 float,V20 float,V21 float, V22 float,V23 float,V24 float, V25 float,V26 float,V27 float, V28 float,Amount float, Class varchar(5) ); -
ステージから作成したテーブルにデータをインポートします。
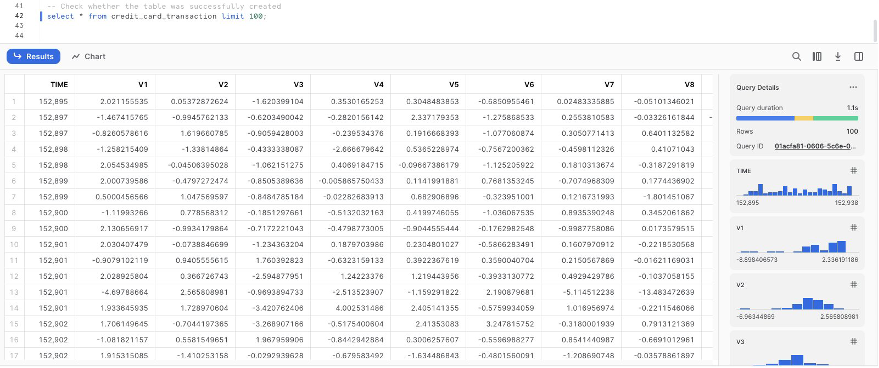
-- 'credit_card_transaction'という名前の新しいテーブルにトランザクションをインポートする copy into credit_card_transaction from @my_stage ON_ERROR = CONTINUE; -- テーブルが正常に作成されたかどうかを確認する select * from credit_card_transaction limit 100;
SageMaker Data WranglerとSnowflake接続の設定
SageMaker Data Wranglerで使用するデータセットを準備した後、SageMaker Data Wranglerで新しいSnowflake接続を作成し、Snowflakeのsf_fin_transactionデータベースに接続して、credit_card_transactionテーブルをクエリします。
- SageMaker Data Wranglerの接続ページでSnowflakeを選択します。
- 接続を識別するための名前を指定します。
- Snowflakeデータベースに接続するための認証方法を選択します:
- 基本認証を使用する場合は、Snowflake管理者から共有されたユーザー名とパスワードを提供します。この投稿では、前の手順で作成したユーザー資格情報を使用してSnowflakeに接続するために基本認証を使用します。
- OAuthを使用する場合は、アイデンティティプロバイダーの資格情報を提供します。
SageMaker Data Wranglerは、S3バケットにデータのコピーを作成することなく、デフォルトで直接Snowflakeからデータをクエリします。 SageMaker Data Wranglerの新しい使いやすさの向上により、Apache Sparkを使用してSnowflakeと統合し、MLの旅のためのデータセットを準備してシームレスに作成します。
これまでに、Snowflakeでデータベースを作成し、CSVファイルをSnowflakeテーブルにインポートし、Snowflake資格情報を作成し、SageMaker Data WranglerでSnowflakeに接続するためのコネクタを作成しました。構成されたSnowflake接続を検証するには、作成されたSnowflakeテーブルで次のクエリを実行してください。
select * from credit_card_transaction;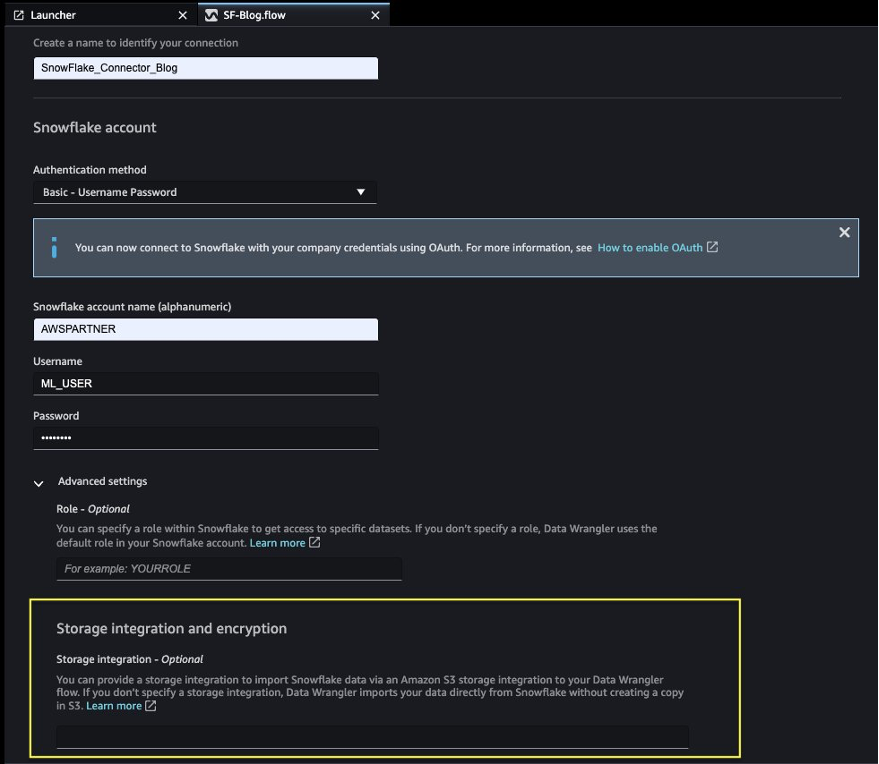
ストレージインテグレーションオプションは、高度な設定でオプションになりました。
Snowflakeデータを探索する
クエリ結果を検証した後、Importを選択してデータセットとしてクエリ結果を保存します。この抽出されたデータセットを探索的データ分析および特徴エンジニアリングに使用します。
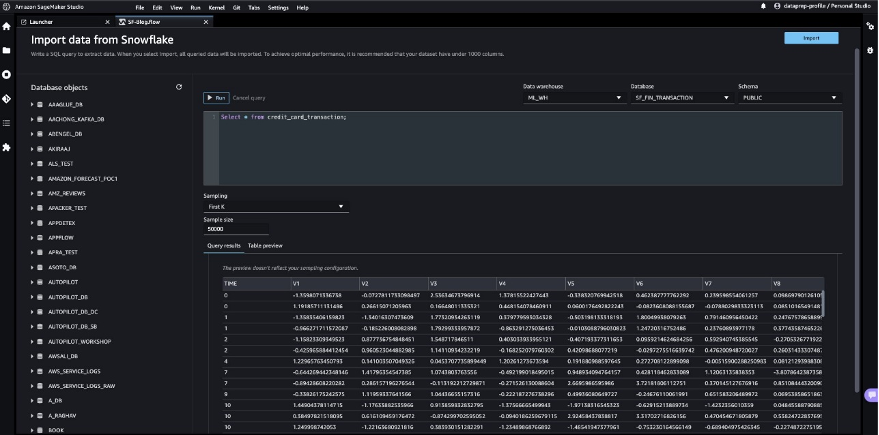
SageMaker Data Wrangler UIでSnowflakeからデータをサンプリングするか、SageMaker Data Wrangler処理ジョブを使用してMLモデルトレーニング用途に完全なデータをダウンロードすることができます。
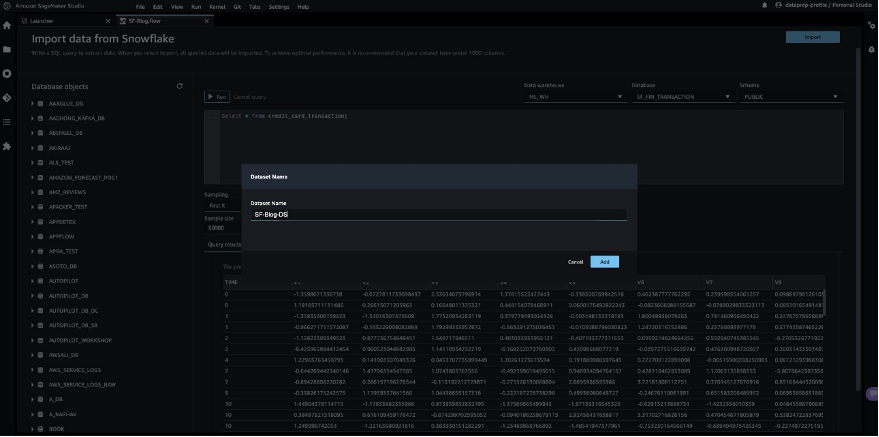
SageMaker Data Wranglerで探索的データ分析を実行する
トレーニングするデータをエンジニアリングする必要があります。 このセクションでは、SageMaker Data Wranglerの組み込み機能を使用して、Snowflakeからのデータに対して特徴エンジニアリングを行う方法を示します。
まず、SageMaker Data Wrangler内のData Quality and Insights Report機能を使用して、Snowflakeからのデータの品質を自動的に検証し、データの異常を検出します。
レポートを使用してデータをクリーンアップおよび処理することができます。欠損値の数や外れ値の数などの情報を提供します。ターゲットリークや不均衡などの問題がある場合は、Insightsレポートがそれらの問題に注意を引くことができます。レポートの詳細については、「Amazon SageMaker Data Wranglerでデータ品質とインサイトを活用してデータ準備を加速する」を参照してください。
SageMaker Data Wranglerに適用されたデータ型マッチングを確認した後、次の手順を実行してください。
- Data typesのプラス記号を選択し、Add analysisを選択します。
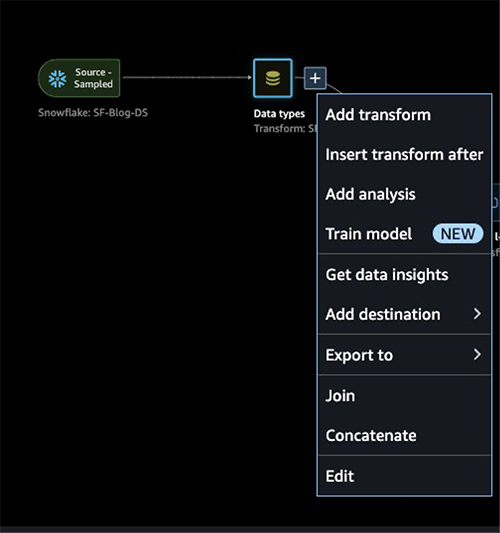
- Analysis typeでData Quality and Insights Reportを選択します。
- Createを選択します。
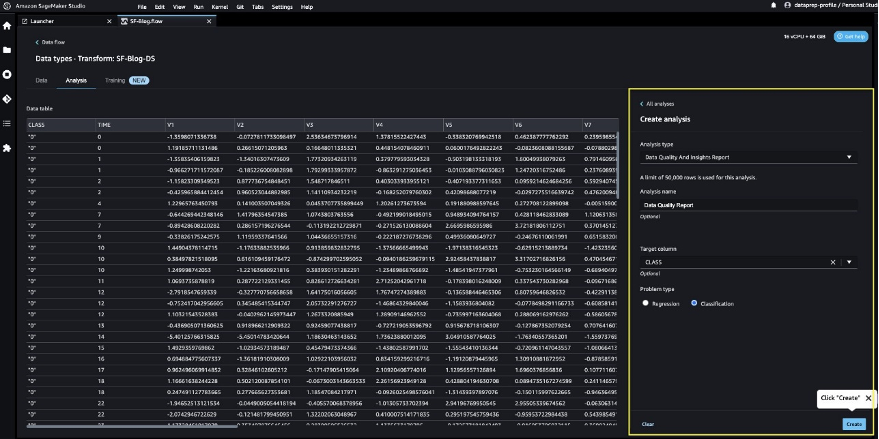
- 高優先度の警告をチェックするには、Data Quality and Insights Reportの詳細を参照してください。
MLの旅を進める前に報告された警告を解決することができます。
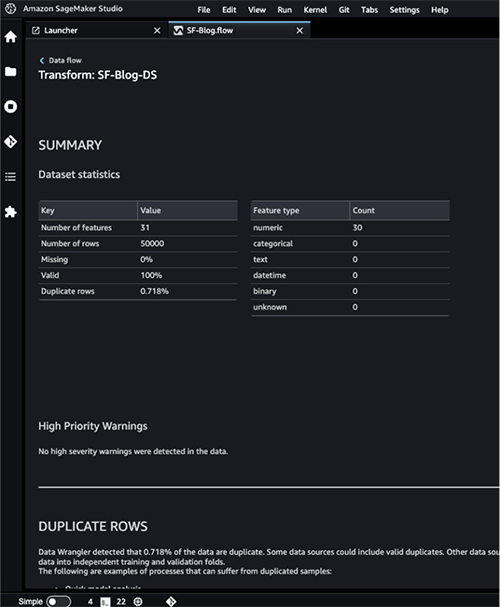
予測されるターゲット列Classは文字列として分類されます。まず、ステールな空の文字を削除するために変換を適用しましょう。
- ステップの追加を選択し、文字列のフォーマットを選択します。
- 変換のリストから左側と右側をストリップを選択します。
- 削除する文字を入力し、追加を選択します。
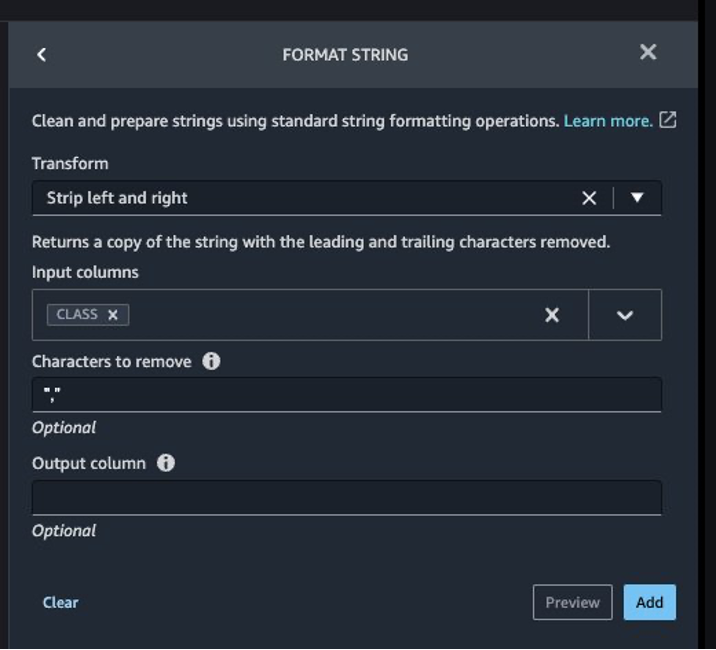
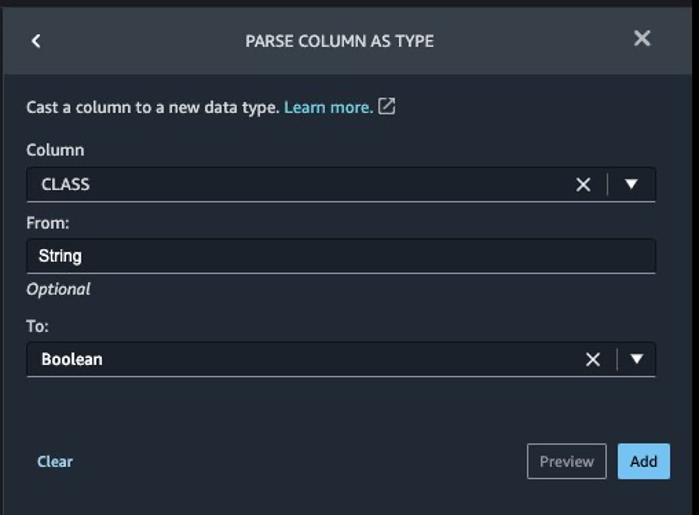
次に、トランザクションが合法か不正かのどちらかであるため、ターゲット列Classを文字列データ型からブール型に変換します。
- ステップの追加を選択します。
- 列を型として解析を選択します。
- 列として、
Classを選択します。 - FromとしてStringを選択します。
- ToとしてBooleanを選択します。
- 追加を選択します。
ターゲット列の変換後は、元のデータセットには30以上の特徴があるため、特徴列の数を減らします。PCA(主成分分析)を使用して、特徴の重要度に基づいて次元を削減します。PCAと次元削減について詳しく知りたい場合は、主成分分析(PCA)アルゴリズムを参照してください。
- ステップの追加を選択します。
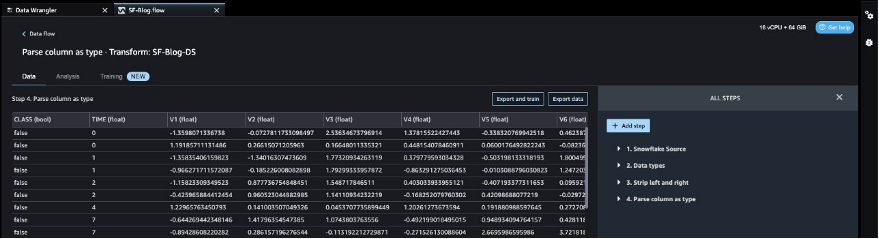
- 次元削減を選択します。
- 変換として主成分分析を選択します。
- 入力列として、ターゲット列
Classを除くすべての列を選択します。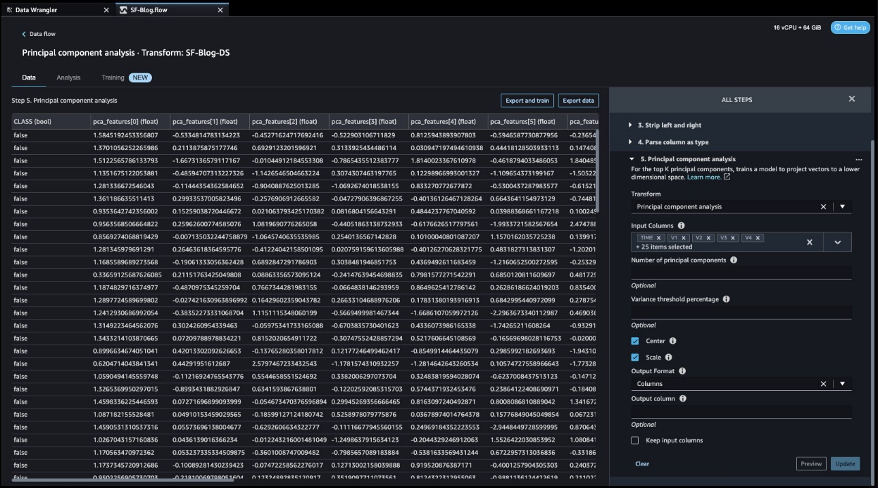
- データ フローの横にあるプラス記号を選択し、分析を追加を選択します。
- 分析タイプとしてクイック モデルを選択します。
- 分析名として名前を入力します。
- ラベルとして
Classを選択します。
- 実行を選択します。
PCAの結果に基づいて、モデルの構築に使用する特徴を決定できます。以下のスクリーンショットでは、グラフがトランザクションが不正または有効であるかを示すターゲットクラスを予測するために、最も重要なものから最も低いものに順序付けられた特徴(または次元)を示しています。
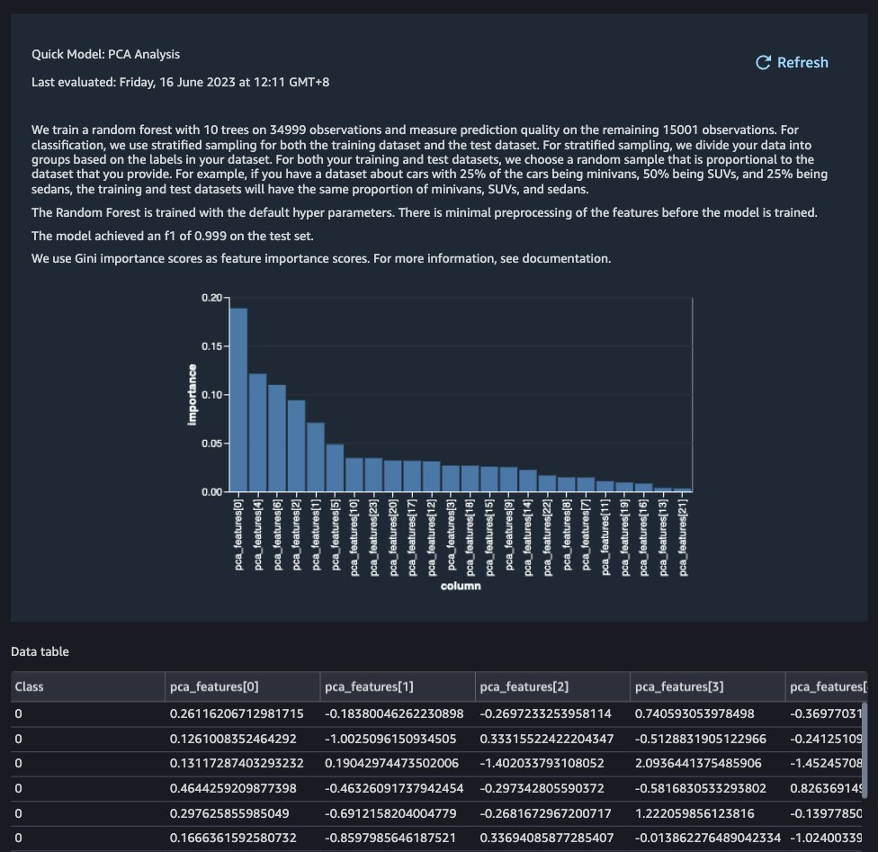
この分析に基づいて特徴の数を減らすことができますが、この投稿ではデフォルトのままにしておきます。
これで特徴量エンジニアリングプロセスは完了ですが、さらなる最適化を行う前に、クイックモデルを実行してデータ品質と洞察レポートを作成して、データを理解することができます。
データのエクスポートとモデルのトレーニング
次のステップでは、SageMaker Autopilotを使用して、データに基づいて最適なMLモデルを自動的に構築、トレーニング、チューニングします。 SageMaker Autopilotを使用すると、データとモデルの完全な制御と可視性を維持できます。
探索と特徴エンジニアリングが完了したので、データセット上でモデルをトレーニングして、SageMaker Autopilotを使用してMLモデルをトレーニングするためにデータをエクスポートしましょう。
- トレーニングタブで、エクスポートしてトレーニングを選択します。
完了するまで待機しながらエクスポートの進捗状況を監視できます。
目的の予測対象と問題の種類を指定して、SageMaker Autopilotを構成して自動トレーニングジョブを実行しましょう。 この場合、データセットをトレーニングしてトランザクションが不正か有効かを予測する場合は、バイナリ分類を使用します。
- 実験名を入力し、S3ロケーションデータを提供し、次:ターゲットとフィーチャーを選択します。
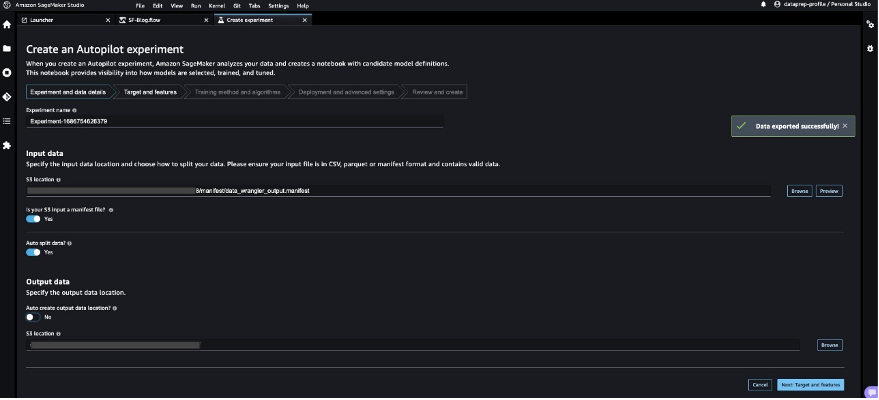
- ターゲットとして、予測する列として
Classを選択します。 - 次:トレーニング方法を選択します。
データセットに基づいてトレーニング方法をSageMaker Autopilotに決定させましょう。
- トレーニング方法とアルゴリズムで自動を選択します。
SageMaker Autopilotでサポートされるトレーニングモードについて詳しくは、「トレーニングモードとアルゴリズムのサポート」を参照してください。
- 次:デプロイメントと高度な設定を選択します。
- デプロイメントオプションで、Data Wranglerからトランスフォームを使用して最適なモデルを自動デプロイを選択します。これにより、実験が完了した後に推論用の最適なモデルがロードされます。
- エンドポイント名を入力します。
- 機械学習問題の種類を選択で、バイナリ分類を選択します。
- 目的関数で、F1を選択します。
- 次:レビューと作成を選択します。
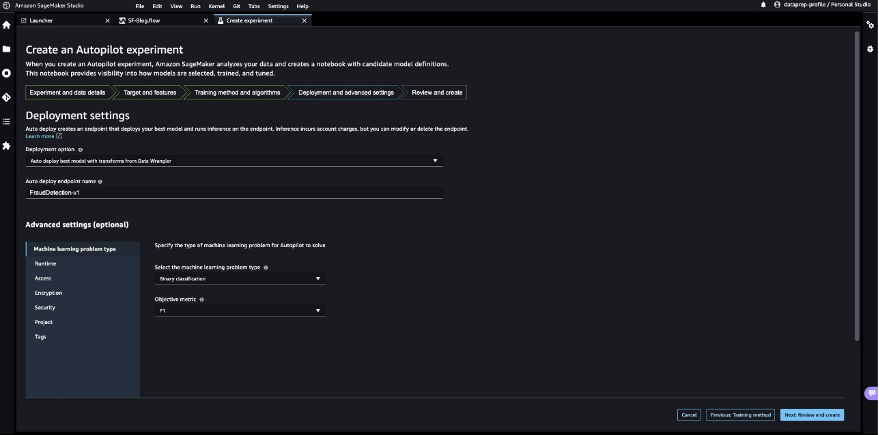
- 実験を作成を選択します。
これは、ハイパーパラメータの組み合わせを使用して、目標指標を最適化する一連のトレーニングジョブを作成するSageMaker Autopilotジョブを開始します。
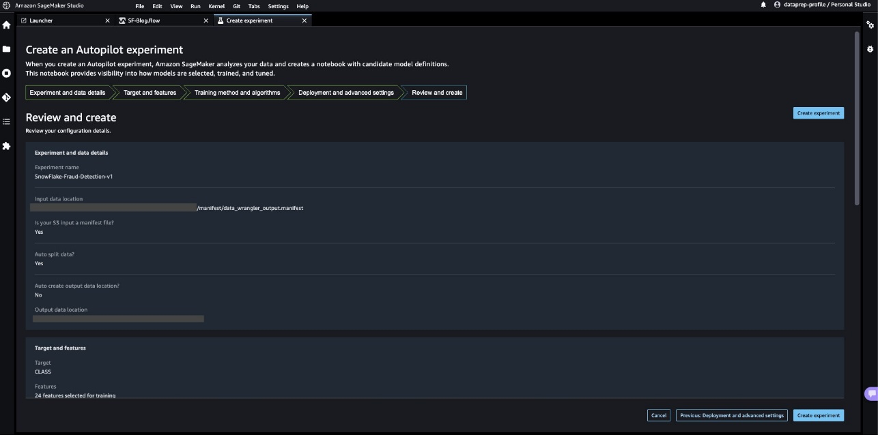
SageMaker Autopilotがモデルの構築と最良のMLモデルの評価を完了するのを待ちます。
最良のモデルをテストするリアルタイム推論エンドポイントを起動
SageMaker Autopilotは、クレジットカード取引を合法的または不正なものと分類できる最良のモデルを決定するための実験を実行します。
SageMaker Autopilotが実験を完了すると、SageMaker Autopilotジョブの説明ページから評価メトリックを含むトレーニング結果を表示できます。
- 最良のモデルを選択し、 Deploy model を選択します。
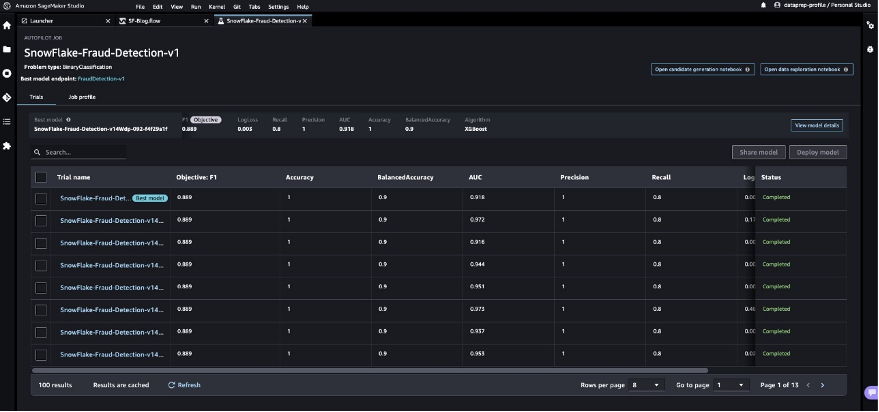
リアルタイム推論エンドポイントを使用して、SageMaker Autopilotで作成された最良のモデルをテストします。
- リアルタイム予測を作成を選択します。
エンドポイントが利用可能になったら、ペイロードを渡して推論結果を取得できます。
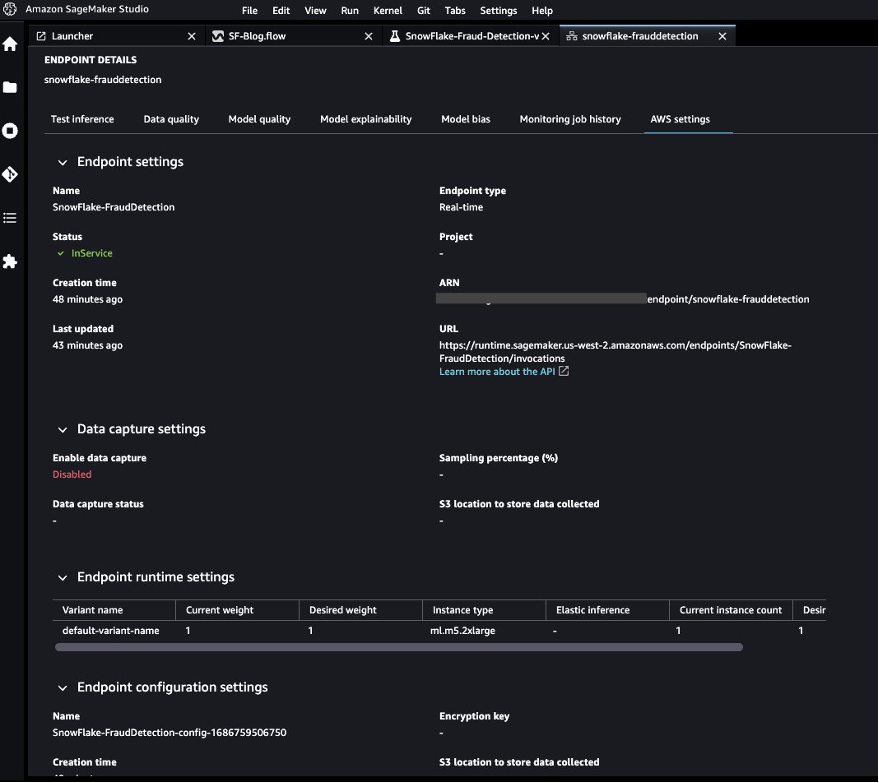
Pythonノートブックを起動して、推論エンドポイントを使用します。
-
SageMaker Studioコンソールで、ナビゲーションペインのフォルダアイコンを選択し、ノートブックを作成を選択します。
-
次のPythonコードを使用して、デプロイされたリアルタイム推論エンドポイントを呼び出します。
# ライブラリのインポート import os import io import boto3 import json import csv #: エンドポイント名を定義します。 ENDPOINT_NAME = 'SnowFlake-FraudDetection' #必要に応じてエンドポイント名を置き換えます runtime = boto3.client('runtime.sagemaker') #: エンドポイントに送信するテストペイロードを定義します。 payload = { "body": { "TIME": 152895, "V1": 2.021155535, "V2": 0.05372872624, "V3": -1.620399104, "V4": 0.3530165253, "V5": 0.3048483853, "V6": -0.6850955461, "V7": 0.02483335885, "V8": -0.05101346021, "V9": 0.3550896835, "V10": -0.1830053153, "V11": 1.148091498, "V12": 0.4283365505, "V13": -0.9347237892, "V14": -0.4615291327, "V15": -0.4124343184, "V16": 0.4993445934, "V17": 0.3411548305, "V18": 0.2343833846, "V19": 0.278223588, "V20": -0.2104513475, "V21": -0.3116427235, "V22": -0.8690778214, "V23": 0.3624146958, "V24": 0.6455923598, "V25": -0.3424913329, "V26": 0.1456884618, "V27": -0.07174890419, "V28": -0.040882382, "AMOUNT": 0.27 } } #: APIリクエストを送信し、レスポンスオブジェクトをキャプチャします。 response = runtime.invoke_endpoint( EndpointName=ENDPOINT_NAME, ContentType='text/csv', Body=str(payload) ) #: モデルエンドポイントの出力を表示します。 print(response['Body'].read().decode())
出力はfalseを示しており、サンプルの特徴データが不正ではないことを示しています。

クリーンアップ
このチュートリアルが完了した後に料金が発生しないようにするには、SageMaker Data Wranglerアプリケーションをシャットダウンし、推論を実行するために使用されたノートブックインスタンスをシャットダウンします。また、SageMaker Autopilotを使用して作成した推論エンドポイントを削除して、追加の料金が発生しないようにする必要があります。
結論
この記事では、中間コピーを作成せずにデータを直接Snowflakeから取り込む方法を示しました。SnowflakeからSageMaker Data Wranglerに直接、サンプルまたは完全なデータセットをロードできます。その後、SageMaker Data Wranglerのビジュアルインターフェースを使用して、データを探索し、クリーンアップし、特徴エンジニアリングを実行できます。
また、SageMaker Data WranglerとSageMaker Autopilotの統合を利用して、コードを書かずに特徴エンジニアリングを完了した後にモデルを簡単にトレーニングおよびチューニングし、SageMaker Autopilotのベストモデルを参照してリアルタイムエンドポイントを使用して推論を実行する方法も紹介しました。
今すぐSnowflakeの直接統合をSageMaker Data Wranglerで試して、あなたのデータを使用してSageMakerでMLモデルを簡単に構築してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- LLMsによる非構造化データから構造化データへの変換
- データサイエンスプロジェクトでのハードコーディングをやめましょう – 代わりに設定ファイルを使用しましょう
- このAI論文は、自律走行車のデータセットを対象とし、コンピュータビジョンモデルのトレーニングの匿名化の影響を研究しています
- Btech卒業後に何をすべきですか?
- MetaのAIが参照メロディに基づいて音楽を生成する方法
- Voxel51 は、コンピュータビジョンデータセット分析のための Python コードを生成するために GPT-3.5 の能力を活用する AI アシスタントである VoxelGPT をオープンソース化しました
- Netflix株の時系列分析(Pandasによる)
