MLOpsを拡張するためのプレイブック
Playbook for expanding MLOps.
マイク・キャラベッタとブレンダン・ケリーによる
チームに向けたMLOpsのスケーリング
MLOpsチームは、AIをスケールするための能力を向上させるためにプレッシャーを感じています。2022年には、組織内外でAIとMLOpsに関する話題が急増しました。ChatGPTの成功と企業内でのモデルのトラクションにより、2023年はさらに大きな話題になると予想されています。
MLOpsチームは、ビジネスの緊急ニーズを満たしながら自己の能力を拡大することを目指しています。これらのチームは、AIを産業化する方法を改善するための取り組みと改善案をたくさん持っています。MLOpsのコンポーネント(デプロイメント、モニタリング、ガバナンス)をどのようにスケーリングするのか?チームのトップ優先事項は何か?
AlignAIは、Ford Motorsと協力して、スケールするために成功した方法に基づいてMLOpsチームをガイドするプレイブックを作成しました。
MLOpsとは何ですか?
まず、MLOpsの作業定義が必要です。MLOpsとは、いくつかのAIモデルを提供する組織から、アルゴリズムを信頼性を持ってスケールして提供することになるものです。この移行には繰り返し可能で予測可能なプロセスが必要です。MLOpsは、より多くのAIとそれに伴う投資利益を意味します。チームがMLOpsに勝利するのは、プロセス、チーム、およびツールをオーケストレーションすることに焦点を当てた場合です。
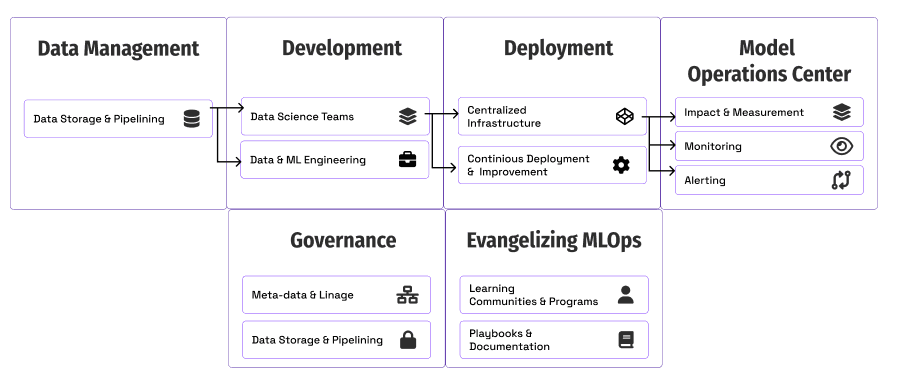
拡大するMLOpsの基礎的な構成要素
Ford Motorsの例とアイデアを使用して、各領域を説明しましょう。
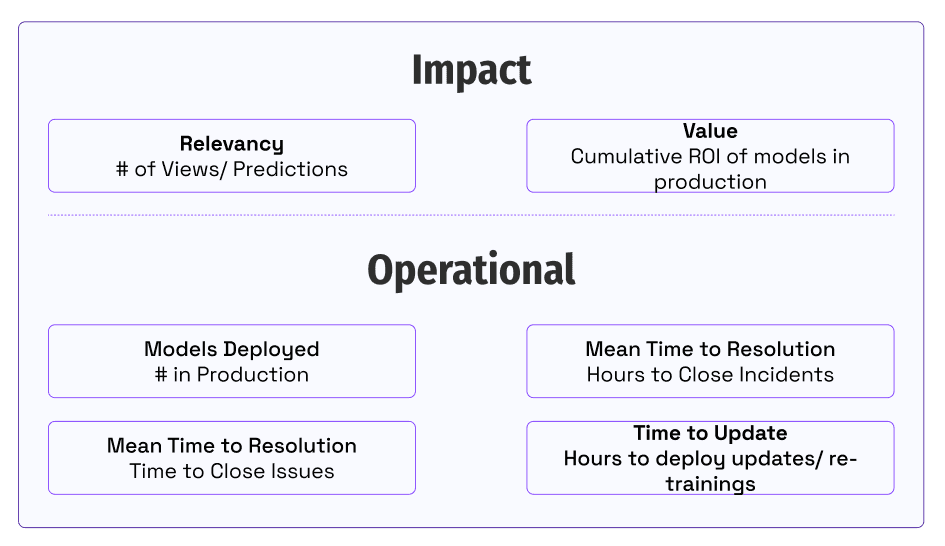
- 測定と影響:チームが進捗状況を追跡し、測定する方法。
- デプロイメント&インフラストラクチャ:チームがモデルのデプロイメントをスケールする方法。
- モニタリング:製品のモデルの品質とパフォーマンスを維持する方法。
- ガバナンス:モデルのコントロールと可視性を作成する方法。
- MLOpsの普及:ビジネスと他の技術チームにMLOpsの使用方法と理由を教育する方法。
測定と影響
ある日、ビジネスのエグゼクティブがFordのMLOpsコマンドセンターに入ってきました。モデルの使用メトリックを確認し、使用状況が低下した理由について生産的な会話をしました。モデルの影響と採用状況のこの可視性は、信頼を構築し、ビジネスのニーズに対応するために不可欠です。
AIを活用し、MLOpsの能力を投資するチームにとって、基本的な質問はどのように進歩しているかということです。
鍵は、チームが顧客とビジネスステークホルダーにどのように価値を提供するかを合わせることです。チームは、ビジネスへの影響とそれを可能にする操作メトリックに重点を置いて、パフォーマンスを定量化することに焦点を当てます。影響を測定することで、私たちがどのように生成するかの全体像を把握できます。
はじめるためのアイデア:
- 現在、開発中または製品内のモデルの価値をどのように測定していますか?ビジネスステークホルダーの使用状況とエンゲージメントをどのように追跡しますか?
- 製品内のモデルの操作メトリックまたはエンジニアリングメトリックは何ですか?これらのメトリックの改善を誰が所有していますか?これらのメトリックを見るために人々にどのようにアクセスしますか?
- ユーザーの行動やソリューションの使用に変更があった場合、どのように知らせますか?これらの問題に誰が対応しますか?
デプロイメント&インフラストラクチャ
MLOpsでチームが最初に直面する壁は、モデルを製品化することです。モデルの数が増えるにつれて、チームは増加したボリュームを処理するための標準化されたプロセスと共有プラットフォームを作成する必要があります。20個のモデルを20個の異なるパターンで展開することは、手間がかかることがあります。エンタープライズチームは、通常、Xモデルに関する中央集権的なインフラストラクチャリソースを作成します。正しいアーキテクチャとインフラストラクチャをモデルとチーム全体で選択することは、困難な問題です。しかし、一度確立されると、モニタリングとガバナンスの機能を構築するための強固な基盤を提供します。
Fordでは、Kubernetes、Google Cloud Platform、そしてそれらをサポートするチームを使用して、標準的なデプロイメント機能を作成しました。
ルーシッドリンク
あなたのチームのアイデア:
- モデルのデプロイメントを中央化する方法は何ですか?中央のチームとリソースを作成または指定して、デプロイメントを管理できますか?
- どのようなデプロイメントパターン(REST、バッチ、ストリーミングなど)がありますか?
- それらをどのように定義して他のチームと共有しますか?
- モデリングチームがモデルを製品化するために克服するのに最も時間がかかったり、困難な側面は何ですか?中央のデプロイメントシステムがこれらの問題を緩和するように設計できますか?
モニタリング
機械学習の独自かつ難しい側面の1つは、モデルがプロダクション中にドリフトし、変化する能力です。モデルを使用するステークホルダーと信頼関係を築くために、モニタリングは重要です。Googleの機械学習の規則は、「アクションを起こせるアラートを含めた良好なアラートハイジニーを実践する」と述べています。これには、モニタリングする領域を定義し、これらのアラートを生成する方法をチームで定義する必要があります。難しい部分は、これらのアラートをアクション可能にすることです。プロダクションで問題を調査して軽減するためのプロセスを確立する必要があります。

Fordでは、モデルオペレーションセンターは、モデルがほぼリアルタイムで期待通りの結果を得ているかを理解するための情報とデータがいっぱいの集中型の場所です。
ここには、使用頻度やレコード数が設定された閾値以下にならないように探しているダッシュボードの簡略化された例があります。
モニタリングメトリクス
あなたのモデルについて考慮すべきモニタリングメトリクスは以下のとおりです:
- レイテンシ:予測を返すまでの時間(たとえば、100のレコードのバッチ処理時間)。
- 統計的パフォーマンス:テストデータセットが与えられた場合、モデルが正しいまたは近い予測を行う能力(たとえば、平均二乗誤差、F2など)。
- データ品質:予測またはトレーニングデータの完全性、正確性、妥当性、およびタイムリネスの量化(たとえば、機能が欠落している予測レコードの%)。
- データドリフト:時間の経過に伴うデータの分布の変化(たとえば、コンピュータビジョンモデルのライティングの変化)。
- モデル使用:ビジネスまたはユーザーの問題を解決するためにモデル予測がどのくらい頻繁に使用されているか(たとえば、RESTエンドポイントとして展開されたモデルの予測数)。
あなたのチームのためのアイデア:
- すべてのモデルをどのようにモニタリングする必要がありますか?
- 各モデルに含める必要のあるメトリックは何ですか?
- メトリックを生成するための標準的なツールやフレームワークはありますか?
- モニタリングアラートと問題をどのように管理しますか?
ガバナンス
イノベーションは、特に企業環境ではリスクを生み出すものです。したがって、イノベーションを成功に導くには、システムにコントロールを設計してリスクを緩和する必要があります。先手必勝で時間と手間を節約することができます。MLOpsチームは、リスクを事前に予測し、ステークホルダーにそのリスクとその緩和方法を積極的に教育する必要があります。
ガバナンスに対する先進的なアプローチを開発することで、ビジネスのニーズに対応することを避けることができます。戦略の2つの主要な要素は、機密性の高いデータへのアクセスを制御することと、可視性と監査のためのラインナップとメタデータを収集することです。
チームは規模拡大に伴い自動化の機会を得ることができます。データの待ち時間は、データサイエンスプロジェクトの永続的な勢いの殺しです。Fordでは、モデルはデータセットに個人を特定できる情報が含まれているかどうかを自動的に判断し、97%の精度で判別します。また、機械学習モデルはアクセスリクエストをサポートし、90%のケースで処理時間を数週間から数分に短縮しました。
もう1つの要素は、モデルのライフサイクル全体でメタデータを追跡することです。機械学習のスケーリングには、モデル自体への信頼性のスケーリングが必要です。スケールでのMLOpsには、プロダクションでの問題や偏見を回避するために品質、セキュリティ、および制御を組み込む必要があります。
チームは、ガバナンスに関する理論や意見に捕らわれることがあります。最善の行動は、ユーザーアクセスに関する明確なアクセスとコントロールから始めることです。
そこから、メタデータのキャプチャと自動化が重要になります。以下の表は、メタデータを収集する領域を示しています。可能な限り、パイプラインやその他の自動化システムを活用して、手動処理や不整合を避けるためにこの情報を自動的にキャプチャします。
収集するメタデータ
以下は、各モデルに収集する項目です:
- バージョン/トレーニング済みモデルアーティファクト:トレーニング済みモデルアーティファクトのユニークな識別子。
- トレーニングデータ-トレーニング済みモデルアーティファクトの作成に使用されたデータ
- トレーニングコード-推論のためのソースコードへのGitハッシュまたはリンク。
- 依存関係-トレーニングで使用されるライブラリ。
- 予測コード-推論のためのソースコードへのGitハッシュまたはリンク。
- 過去の予測-監査目的で推論を保存します。
あなたのチームのためのアイデア:
- プロジェクト全体でどのような問題が発生しましたか?
- ビジネスステークホルダーが経験したり懸念している問題は何ですか?
- データへのアクセスリクエストはどのように管理しますか?
- 誰が承認しますか?
- 自動化の機会はありますか?
- モデルパイプラインまたは展開によって作成される脆弱性は何ですか?
- どのようなメタデータをキャプチャする必要がありますか?
- それはどのように保存され、利用可能になりますか?
MLOpsの布教
多くの技術チームは、「作れば来る」と思い込む罠に陥ります。問題を解決するにはそれ以上のことが必要です。組織の影響を増すために、ソリューションを共有し、提唱することも必要です。MLOpsチームは、組織のツール、データ、モデル、ステークホルダーの独自の問題を解決するためのベストプラクティスとその共有が必要です。
MLOpsチームの誰でも、ビジネスステークホルダーと協力して成功事例を紹介することで、布教者になることができます。組織内の例を紹介することで、利点や機会を明確に示すことができます。
AIを産業化するために教育、文書化、その他のサポートが必要な組織全体の人々がいます。ランチ&ラーン、オンボーディング、メンターシッププログラムは、良いスタート地点です。組織が拡大するにつれて、より形式化された学習とオンボーディングプログラムが、組織の変革を加速するためのサポート文書とともに必要になります。
あなたのチームのアイデア:
- MLOpsのためのコミュニティや継続的な学習とベストプラクティスをどのように作成できますか?
- 確立して共有するために、どのような新しい役割と能力が必要ですか?
- 共有できる解決済みの問題は何ですか?
- 他のチームとベストプラクティスや成功事例を共有するために、トレーニングや文書化をどのように提供していますか?
- データサイエンティスト、データエンジニア、ビジネスステークホルダーがAIモデルを扱う方法を学ぶための学習プログラムやチェックリストをどのように作成できますか?
はじめに
MLOpsチームとリーダーは、モデルを産業化する緊急のニーズと並行して、山のような機会に直面しています。各組織は、データ、モデル、テクノロジーに応じて異なる課題に直面しています。MLOpsが簡単だったら、私たちはおそらくその問題に取り組むことが好きではなかったでしょう。
課題は常に優先順位付けです。
このプレイブックがあなたのチームが探求するための新しいアイデアや領域を生み出すのに役立つことを願っています。最初のステップは、2023年のあなたのチームのための機会の大きなリストを作成することです。それから、顧客に最大の影響を与えるものを優先的に選択してください。チームは、進行中のプロジェクトでの成熟度の進歩を定義し、測定することもできます。このGoogleのガイドは、チームのためのフレームワークと成熟度のマイルストーンを提供します。
あなたのチームのアイデア:
- MLOpsの成熟度や洗練度をどのように進めるための最大の機会は何ですか?
- 成熟度を進めるプロジェクトの進捗をどのようにキャプチャし、トラッキングしますか?
- このガイドとあなたのチームのためのタスクのリストを作成し、実装時間と期待される恩恵に基づいて優先順位をつけ、ロードマップを作成してください。
参考文献
- https://www2.deloitte.com/content/dam/insights/articles/7022_TT-MLOps-industrialized-AI/DI_2021-TT-MLOps-industrialized-AI.pdf
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://developers.google.com/machine-learning/guides/rules-of-ml
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
マイク・キャラベッタは、データ分析を使って数億ドルのビジネス価値を提供してきました。現在、彼はフォードでMLOpsの拡大と複雑性の削減に取り組んでいます。 ブレンダン・ケリーは、AlignAIの共同創設者であり、銀行、金融サービス、製造、保険業界にわたる多くの組織のMLOpsを加速するのに役立っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






