GPT4Allは、あなたのドキュメント用のローカルChatGPTであり、無料です!
GPT4All is a local ChatGPT for your documents and it's free!
この記事では、CPUのみを使用するコンピュータ上でGPT4Allモデルを展開して使用する方法(私はGPUのないMacbook Proを使用しています!)を学びます。

この記事では、ローカルコンピュータにGPT4All(強力なLLM)をインストールし、Pythonを使用してドキュメントとのやり取り方法を発見します。 PDFまたはオンライン記事のコレクションは、質問/回答の知識ベースになります。
GPT4Allとは何ですか?
公式ウェブサイトGPT4Allによると、これは無料で使用できる、ローカルで実行され、プライバシーに配慮したチャットボットです。 GPUやインターネットは必要ありません。
GTP4Allは、消費者向けのCPUでローカルに実行される強力でカスタマイズ可能な大規模言語モデルをトレーニングおよび展開するためのエコシステムです。
私たちのGPT4Allモデルは4GBのファイルであり、GPT4Allオープンソースエコシステムソフトウェアにダウンロードしてプラグインすることができます。 Nomic AIは、高品質で安全なソフトウェアエコシステムを促進し、個人および組織が簡単に自分自身の大規模言語モデルをローカルでトレーニングおよび実装できるようにする取り組みを推進しています。
どのように動作しますか?
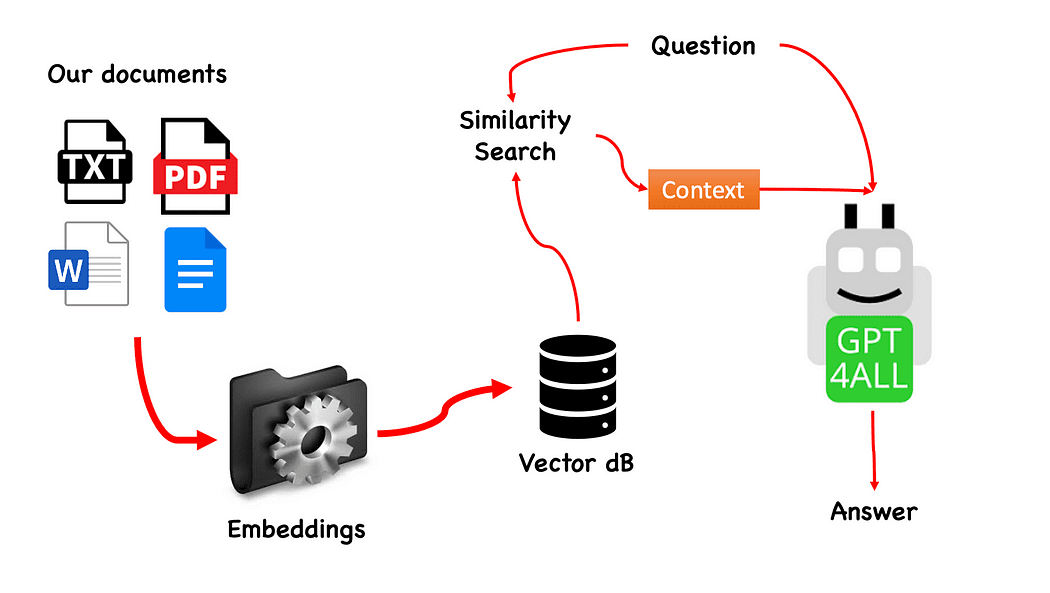
プロセスは非常にシンプルです(知っている場合)。ステップは次のとおりです:
- GPT4Allモデルをロードする
- Langchainを使用してドキュメントを取得し、ロードする
- 埋め込みによって消化可能な小さなチャンクにドキュメントを分割する
- Embeddingsを使用してベクトルデータベースを作成する
- 私たちがGPT4Allに渡したい質問に基づいて、私たちのベクトルデータベースで類似性検索(意味検索)を実行する:これは私たちの質問の文脈として使用されます
- Langchainを使用して質問と文脈をGPT4Allにフィードし、回答を待ちます。
必要なのはEmbeddingsです。埋め込みは、テキスト、ドキュメント、画像、音声などの情報の数値表現であり、表現は埋め込まれたものの意味的な意味を捉えています。このプロジェクトでは重いGPUモデルに頼ることはできないため、Alpacaネイティブモデルをダウンロードし、LangchainからLlamaCppEmbeddingsを使用します。心配しないでください!ステップバイステップで説明しています。
コーディングを始めましょう
仮想環境を作成する
新しいPythonプロジェクト用に新しいフォルダを作成し、例えばGPT4ALL_Fabio(あなたの名前を入力してください…)とします:
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabio次に、新しいPython仮想環境を作成します。複数のPythonバージョンがインストールされている場合は、希望するバージョンを指定します。この場合、私はPython 3.10に関連付けられたメインインストールを使用します。
python3 -m venv .venvpython3 -m venv .venvコマンドは、.venvという名前の新しい仮想環境を作成します(ドットはvenvという名前の非表示ディレクトリを作成します)。
仮想環境は、システム全体のPythonインストールや他のプロジェクトに影響を与えずに、特定のプロジェクトだけにパッケージや依存関係をインストールできるようにする、分離されたPythonインストールを提供します。この分離により、一貫性が保たれ、異なるプロジェクトの要件間で潜在的な競合が防止されます。
仮想環境が作成されたら、次のコマンドを使用してアクティブ化できます:
source .venv/bin/activate
インストールするライブラリー
構築しているプロジェクトには、あまり多くのパッケージは必要ありません。必要なのは次の2つだけです:
- GPT4AllのPythonバインディング
- ドキュメントとのやり取りにLangchainを使用する
LangChainは、言語モデルによって動力を与えられるアプリケーションを開発するためのフレームワークです。APIを介して言語モデルを呼び出すだけでなく、言語モデルを他のデータソースに接続し、言語モデルが環境と対話することもできます。
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChainの場合、バージョンも指定しています。このライブラリは最近多くのアップデートを受けていますので、明日も正常に動作するバージョンを指定することが望ましいです。Unstructuredは、pdf loader、pytesseract、pdf2imageに必要な依存関係です。
注意:GitHubリポジトリには、このプロジェクトに関連するすべてのバージョンが記載されたrequirements.txtファイルがあります(jl adcrによって提案されました)。次のコマンドを使用して、メインプロジェクトファイルディレクトリにダウンロードした後、一度にインストールできます。
pip install -r requirements.txt記事の最後に、トラブルシューティングのセクションを作成しました。GitHubリポジトリには、これらすべての情報が含まれた更新されたREADMEもあります。
注意:いくつかのライブラリには、使用しているPythonバージョンに応じて利用可能なバージョンがあります。
PCにモデルをダウンロードする
これは非常に重要なステップです。
プロジェクトにはGPT4Allが必要です。Nomic AIで説明されているプロセスは非常に複雑で、私のように持っていないハードウェアが必要です。したがって、すでに変換されて使用する準備ができているモデルへのリンクをここに示します。ダウンロードをクリックしてください。
紹介文で簡単に説明したように、埋め込み用のモデルも必要です。私たちのCPUでクラッシュすることなく実行できるモデルです。アルパカネイティブ7B-ggmlを4ビットに変換してすでに使用できるようにダウンロードするためのリンクをここにクリックしてください。
なぜ埋め込みが必要なのでしょうか?フローダイアグラムから覚えているかもしれませんが、ナレッジベースのドキュメントを収集した後、最初に必要なステップは埋め込みです。このアルパカモデルのLLamaCPP埋め込みは完璧に適合し、このモデルもかなり小さいです(4 GB)。ところで、アルパカモデルをQnAにも使用できます!
2023.05.25のアップデート:多くのWindowsユーザーがllamaCPP埋め込みを使用する際に問題に直面しています。これは、llama-cpp-pythonというpythonパッケージのインストール中に発生することが主な原因です。
pip install llama-cpp-pythonpipパッケージがライブラリをソースからコンパイルするようになっているため、Windowsには通常、マシンにデフォルトでCMakeまたはCコンパイラがインストールされていません。しかし、解決策があります
LangChainに必要なllama-cpp-pythonのインストールを、llamaEmbeddingsで実行する場合、Windowsの場合、CMake Cコンパイラがデフォルトでインストールされていないため、ソースからビルドできません。
Xtoolsを持つMacユーザーやLinuxでは、通常、CコンパイラがOSにすでに用意されています。
問題を回避するためには、事前にコンパイルされたwheelを使用する必要があります。
ここにアクセスしてhttps://github.com/abetlen/llama-cpp-python/releases
アーキテクチャとPythonバージョンに適したコンパイルされたwheelを検索してください。 バージョン0.1.49のWeelsバージョンを取る必要があります。なぜなら、より高いバージョンは互換性がないからです。
私の場合、Windows 10、64ビット、Python 3.10を使用しています。
だから、私のファイルはllama_cpp_python-0.1.49-cp310-cp310-win_amd64.whlです。
この問題はGitHubリポジトリで追跡されています
ダウンロード後、以下に示すように2つのモデルをmodelsディレクトリに配置する必要があります。

GPT4Allとの基本的なインタラクション
GPTモデルを制御するために、pythonファイルを作成して(pygpt4all_test.pyと呼びましょう)、依存関係をインポートし、モデルに命令を与える必要があります。非常に簡単です。
from pygpt4all.models.gpt4all import GPT4Allこれは、モデルのPythonバインディングです。これで呼び出して、質問を開始することができます。創造的なものを試してみましょう。
モデルからコールバックを読み取る関数を作成し、GPT4Allに文を補完するように依頼します。
def new_text_callback(text):
print(text, end="")
model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)最初の文は、プログラムがモデルを見つける場所を指定しています(前のセクションで行ったことを覚えていますか?)
2番目の文は、モデルに応答を生成し、私たちのプロンプト「Once upon a time,」を補完するように依頼しています。
実行するには、仮想環境がまだアクティブであることを確認し、次のように実行します:
python3 pygpt4all_test.pyモデルの読み込み中のテキストと文の補完が表示されるはずです。ハードウェアリソースによっては、少し時間がかかる場合があります。
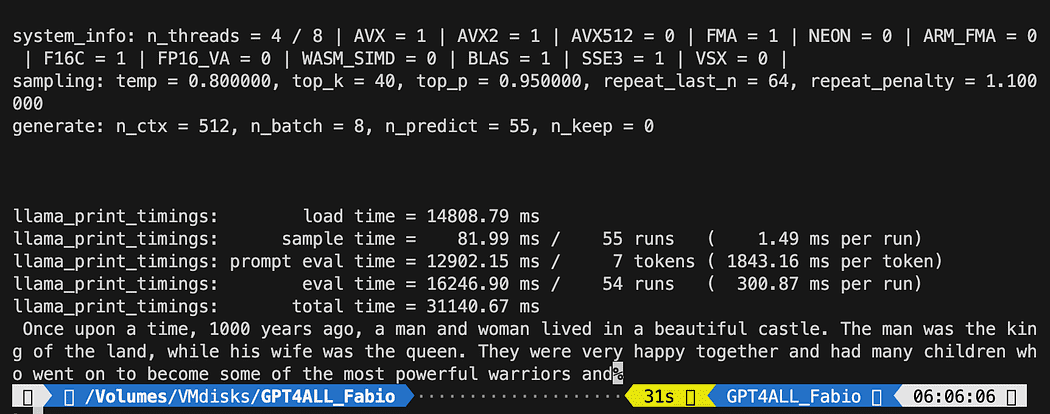
結果はあなたと異なる場合がありますが、重要なのは動作していることで、LangChainでいくつかの高度なものを作成できることです。
注(2023.05.23更新):pygpt4allに関連するエラーが発生した場合は、Rajneesh AggarwalまたはOscar Jeongによって提供された解決策が記載されているトラブルシューティングセクションを確認してください。
GPT4AllのLangChainテンプレート
LangChainフレームワークは本当に素晴らしいライブラリです。言語モデルを簡単に使用できるようにするコンポーネントを提供し、チェーンも提供しています。チェーンは、特定のユースケースを最も効果的に実行するためにこれらのコンポーネントを特定の方法で組み合わせることができるものと考えることができます。これらは、特定のユースケースで簡単に開始できるようにするためのより高位のインターフェイスであり、カスタマイズ可能に設計されています。
次のPythonテストでは、プロンプトテンプレートを使用します。言語モデルは、テキストを入力として受け取ります。通常、これは単なるハードコードされた文字列ではなく、テンプレート、いくつかの例、およびユーザー入力の組み合わせです。LangChainは、プロンプトの構築と操作を簡単にするためのいくつかのクラスと関数を提供します。どのようにしてそれを行うか見てみましょう。
新しいPythonファイルを作成し、my_langchain.pyと呼びます
# langchainプロンプトテンプレートおよびチェーンのインポート
from langchain import PromptTemplate, LLMChain
# GPT4Allとlangchainから直接インタラクションするためにllmをインポート
from langchain.llms import GPT4All
# 応答処理のためにコールバックマネージャが必要です
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
local_path = './models/gpt4all-converted.bin'
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])LangChainからプロンプトのテンプレートとチェーン、GPT4All llmクラスをインポートして、直接GPTモデルとインタラクトできるようにしました。
その後、llmパスを設定した後、コールバックマネージャをインスタンス化し、クエリの応答をキャッチできるようにします。
テンプレートを作成するには、ドキュメントのチュートリアルに従って、次のようにできます…
template = """Question: {question}
Answer: Let's think step by step on it.
"""
prompt = PromptTemplate(template=template, input_variables=["question"])テンプレート変数は、モデルとのインタラクション構造を含む複数行の文字列です。波括弧内に外部変数を挿入し、私たちのシナリオではquestionです。
変数であるため、ハードコードされた質問かユーザー入力の質問かを決定できます。以下に2つの例を示します。
# ハードコードされた質問
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?"
# ユーザー入力の質問...
question = input("Enter your question: ")テストランでは、ユーザー入力の質問はコメントアウトします。これで、テンプレート、質問、および言語モデルをリンクさせる必要があります。
template = """Question: {question}
Answer: Let's think step by step on it.
"""
prompt = PromptTemplate(template=template, input_variables=["question"])
# GPT4Allインスタンスを初期化します
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True)
# 言語モデルをプロンプトテンプレートにリンクします
llm_chain = LLMChain(prompt=prompt, llm=llm)
# ハードコードされた質問
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?"
# ユーザー入力の質問...
# question = input("Enter your question: ")
# クエリを実行して結果を取得します
llm_chain.run(question)仮想環境がまだアクティブであることを確認して、以下のコマンドを実行してください。
python3 my_langchain.py私と異なる結果が得られる場合があります。素晴らしいことは、GPT4Allが答えを得るためにたどった推論全体を見ることができることです。質問を調整することで、より良い結果を得ることができます。
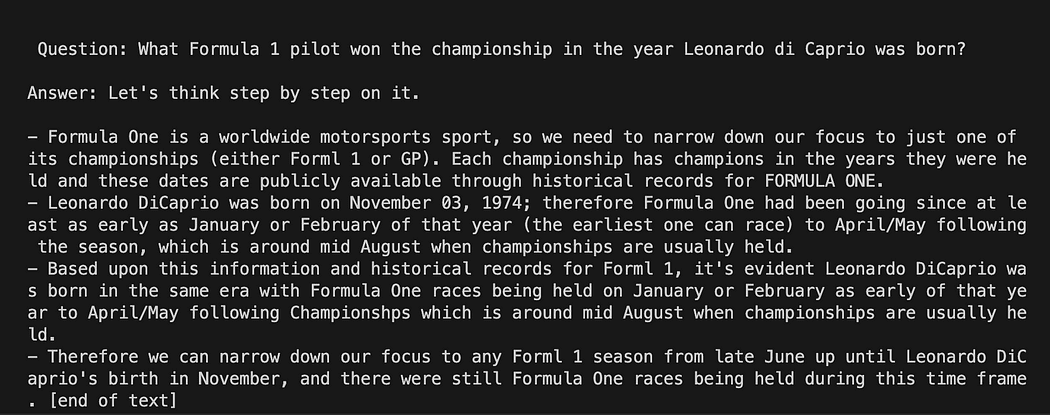
GPT4Allを使用したPrompt TemplateでのLangchain
LangChainとGPT4Allを使用してドキュメントに関する質問に答える
ここからが驚くべき部分です。GPT4Allを使用して、質問に答えるチャットボットとして、ドキュメントに話しかけることができます。
GPT4Allを使用したQnAのワークフローに関する手順のシーケンスは、PDFファイルを読み込んで、チャンクに分割することです。その後、埋め込みのためのベクトルストアが必要になります。情報検索のために、チャンク化されたドキュメントをベクトルストアにフィードする必要があります。そして、このデータベースをコンテキストとしてLLMクエリに埋め込み、このデータベース内で類似性検索を行います。
このために、Langchainライブラリから直接FAISSを使用します。FAISSは、高次元データの大きなコレクションで類似したアイテムを素早く見つけることを目的としたFacebook AI Researchのオープンソースライブラリです。データセット内で最も類似したアイテムをより簡単かつ迅速に見つけるために、インデックス付けと検索方法を提供します。これは、情報検索を簡素化し、作成されたデータベースをローカルに保存できるため、非常に高速に読み込まれることを意味します。これは、最初の作成後、以降の使用に非常に便利です。
ベクトルインデックスDBの作成
新しいファイルを作成し、my_knowledge_qna.pyと名付けます。
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime最初のライブラリは、以前使用したものと同じです。さらに、Langchainを使用して、ベクトルストアインデックスの作成、LlamaCppEmbeddingsを使用してAlpacaモデルとのやり取り、およびPDFローダーを使用します。
また、埋め込みとテキスト生成のためのパスごとにLLMsも読み込みます。
# 2つのモデルGPT4AllとAlpacaの埋め込みのためのパスを割り当てる
gpt4all_path = './models/gpt4all-converted.bin'
llama_path = './models/ggml-model-q4_0.bin'
# モデルの呼び出しを処理するためのCallback Manager
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# 埋め込みオブジェクトを作成する
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# GPT4All llmオブジェクトを作成する
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)テストのために、すべてのpdfファイルを読み取ることができたかを確認してみましょう。最初に、抽出されたテキストをチャンクに分割するための3つの関数を宣言する必要があります。2つ目は、メタデータ(ページ番号など)を使用してベクトルインデックスを作成するためのもので、最後のものは類似性検索のテストに使用されます(後で詳しく説明します)。
# テキストの分割
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(query, index):
# kはクエリに一致する類似性検索の数です
# デフォルトは4
matched_docs = index.similarity_search(query, k=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sourcesこれで、docsディレクトリ内のドキュメントのインデックス生成をテストできるようになりました。そこにすべてのpdfを置く必要があります。Langchainには、ファイルタイプに関係なく、フォルダ全体を読み込むためのメソッドもあります。後処理が複雑なため、LaMiniモデルに関する次の記事でカバーします。

私のdocsディレクトリには4つのpdfファイルが含まれています。
最初のドキュメントに関数を適用します。
# docsディレクトリからのpdfファイルのリストを取得してリスト形式にする
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# PDFのローダーをパスから作成する
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# Langchainでドキュメントをロードする
docs = loader.load()
# チャンクに分割
chunks = split_chunks(docs)
# ベクトルインデックスを作成する
db0 = create_index(chunks)最初の行では、osライブラリを使用して、docsディレクトリ内のpdfファイルのリストを取得します。次に、Langchainを使用してdocsフォルダから最初のドキュメント(doc_list[0])をロードし、チャンクに分割し、LLama埋め込みを使用してベクトルデータベースを作成します。
ご覧のように、pyPDFメソッドを使用しています。これは、1つずつファイルを読み込む必要があるため、使用するのにやや長くなりますが、pypdfを使用してドキュメントの配列にPDFをロードすると、各ドキュメントにはページのコンテンツとメタデータが含まれます。page番号。これは、クエリに与えるコンテキストのソースを知りたい場合に本当に便利です。次は、readthedocsからの例です。
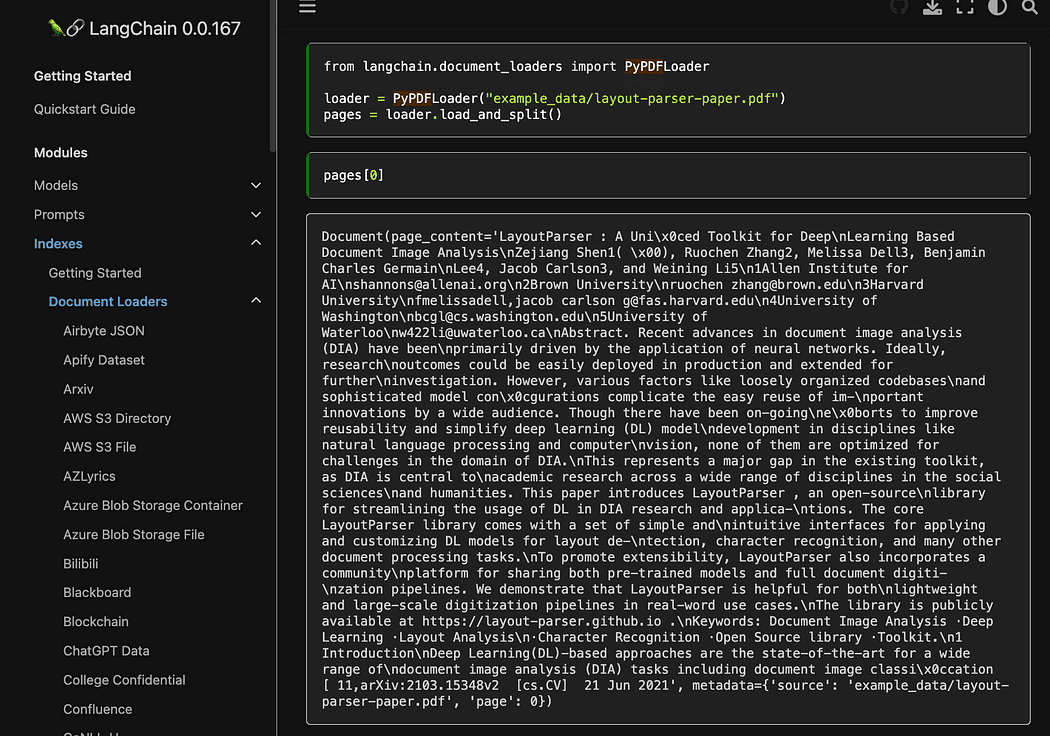 Langchainのドキュメントからのスクリーンショット
Langchainのドキュメントからのスクリーンショット
ターミナルから次のコマンドでPythonファイルを実行できます。
python3 my_knowledge_qna.py埋め込みモデルのロード後、インデックス作成にはトークンが使用されるため、時間がかかることがあります。特に、私のようにCPUで実行する場合は、8分かかりました。
 最初のベクトルdbの完成
最初のベクトルdbの完成
pyPDFメソッドは遅いですが、類似検索のための追加データを提供します。すべてのファイルに反復処理するには、FAISSから便利なメソッドを使って、異なるデータベースをマージすることができます。今やることは、上記のコードを使用して最初のdb(db0と呼ぶ)を生成し、forループでリスト内の次のファイルのインデックスを作成し、すぐにdb0とマージすることです。
コードはこちらです。datetime.datetime.now()を使用して進行状況のステータスを表示し、終了時刻と開始時刻の差を印刷して、操作にかかった時間を計算するためにログを追加しました(気に入らない場合は削除できます)。
マージの手順は次のようになります
# dbiを既存のdb0にマージします
db0.merge_from(dbi)最後の命令の1つは、データベースをローカルに保存することです:全体の生成には数時間かかる場合があるため(文書の数によって異なります)、1度だけ行う必要があるため、本当に良いです!
# データベースをローカルに保存
db0.save_local("my_faiss_index")ここにすべてのコードがあります。GPT4Allが直接フォルダからインデックスをロードするときに、私たちはその多くの部分にコメントを付けます。
# ドキュメントディレクトリからPDFファイルのリストを取得してリスト形式で取得
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
#パスからPDFをロードするためのローダーを作成する
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs):
print(doc_list[i])
print(f"loop position {i}")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i]))
start = datetime.datetime.now() #not used now but useful
docs = loader.load()
chunks = split_chunks(docs)
dbi = create_index(chunks)
print("start merging with db0...")
db0.merge_from(dbi)
end = datetime.datetime.now() #not used now but useful
elapsed = end - start #not used now but useful
#total time
print(f"completed in {elapsed}")
print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# データベースをローカルに保存
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")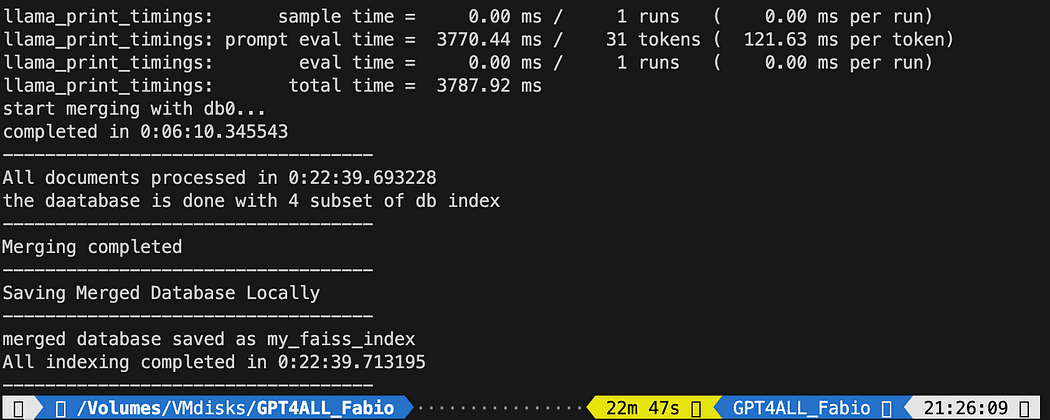 実行には22分かかりました。
実行には22分かかりました。
GPT4Allに質問してドキュメントを問い合わせる
ここにいます。インデックスがあり、それをロードして、プロンプトテンプレートを使用して、GPT4Allに質問をすることができます。ハードコーディングされた質問から始め、入力された質問をループします。
以下のコードをpythonファイルdb_loading.pyに入力して、ターミナルからpython3 db_loading.pyコマンドを実行します。
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime
# TEST FOR SIMILARITY SEARCH
# assign the path for the 2 models GPT4All and Alpaca for the embeddings
gpt4all_path = './models/gpt4all-converted.bin'
llama_path = './models/ggml-model-q4_0.bin'
# Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)
# Split text
def split_chunks(sources):
chunks = []
splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32)
for chunk in splitter.split_documents(sources):
chunks.append(chunk)
return chunks
def create_index(chunks):
texts = [doc.page_content for doc in chunks]
metadatas = [doc.metadata for doc in chunks]
search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas)
return search_index
def similarity_search(query, index):
# k is the number of similarity searched that matches the query
# default is 4
matched_docs = index.similarity_search(query, k=3)
sources = []
for doc in matched_docs:
sources.append(
{
"page_content": doc.page_content,
"metadata": doc.metadata,
}
)
return matched_docs, sources
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
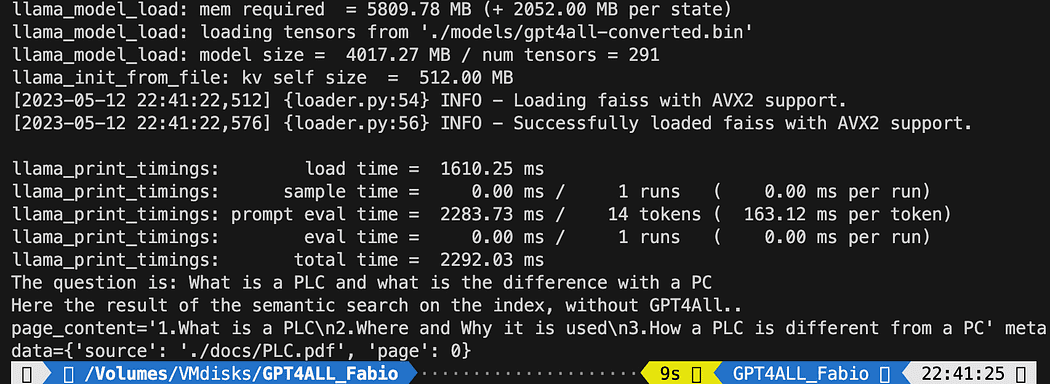
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])印刷されたテキストは、クエリに最もマッチする3つのソースのリストであり、またドキュメント名とページ番号も示しています。
今、プロンプトテンプレートを使用してクエリのコンテキストとして類似性検索を使用できます。 3つの関数の後、すべてのコードを次のコードに置き換えます。
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step."""
# Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "\n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))実行後、次のような結果が表示されます(ただし、異なる場合があります)。 素晴らしいですね!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC),
also called Industrial Control System or ICS, refers to an industrial computer
that controls various automated processes such as manufacturing
machines/assembly lines etcetera through sensors and actuators connected
with it via inputs & outputs. It is a form of digital computers which has
the ability for multiple instruction execution (MIE), built-in memory
registers used by software routines, Input Output interface cards(IOC)
to communicate with other devices electronically/digitally over networks
or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial
automation as it has the ability for more than one instruction execution.
It can perform tasks automatically and programmed instructions, which allows
it to carry out complex operations that are beyond a
Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory
registers used by software routines or firmware codes etcetera but
PC doesn't contain them so they need external interfaces such as
hard disks drives(HDD), USB ports, serial and parallel
communication protocols to store data for further analysis or
report generation.ユーザー入力の質問を使用して、次の行を次のように置き換える場合:
question = "What is a PLC and what is the difference with a PC"次のようにします。
question = input("Your question: ")結論
あなたも実験してみる時です。 ドキュメントに関連するすべてのトピックに関する異なる質問をして、結果を見てください。 プロンプトとテンプレートには、改善の余地がたくさんあります。ここでいくつかのインスピレーションを見ることができます。 Langchainのドキュメントは本当に素晴らしいです(私はそれに従うことができました!)。
この記事からコードをフォローするか、私のgithubリポジトリで確認してください。
Fabio Matricardi教育者、教師、エンジニア、学習熱心者。彼は15年間若い学生に教え、現在はKey Solution Srlの新しい従業員を訓練しています。 彼は2010年に産業オートメーションエンジニアとしてキャリアをスタートさせました。 彼は10代の頃からプログラミングに情熱を持っており、ソフトウェアやヒューマンマシンインタフェースを構築して何かを生み出す美しさを発見しました。 教育とコーチングは、私の日常的なルーチンの一部であり、最新のマネジメントスキルを備えた情熱的なリーダーになる方法を学んでいます。 マシンラーニングと人工知能を使用して、エンジニアリングライフサイクル全体でより良いデザイン、予測システム統合を目指す旅の中で私と一緒に参加してください。
オリジナル。許可を得て再投稿されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






