Amazon Pollyを使用してテキストが話されている間にテキストをハイライト表示します
Use Amazon Polly to highlight text while it is being spoken.
Amazon Pollyは、テキストを生き生きとした音声に変換するサービスです。これにより、複数の言語でテキストを音声に変換するアプリケーションの開発が可能になります。
このサービスは、チャットボット、オーディオブック、その他のテキスト読み上げアプリケーションに、他のAWS AIまたは機械学習(ML)サービスと組み合わせて使用することができます。例えば、Amazon LexとAmazon Pollyを組み合わせて、ユーザーとの双方向の対話を行い、ユーザーのコマンドに基づいて特定のタスクを実行するチャットボットを作成することができます。音声をテキストに転写し、異なる言語に翻訳し、音声化するために、Amazon Transcribe、Amazon Translate、Amazon Pollyを組み合わせることもできます。
この記事では、Amazon Pollyを使用してテキストが音声化される際にテキストをハイライトする興味深いアプローチを紹介します。このソリューションは、次のことを行うために、多くのテキスト読み上げアプリケーションで使用することができます:
- 書籍、ウェブサイト、ブログの音声に視覚的な機能を追加する
- テキストが音声化される際に、テキストを迅速に理解しようとする顧客の理解を高める
このソリューションでは、クライアント(この例ではブラウザ)がAmazon Pollyによってどのテキスト(単語または文)がいつ発話されているかを知る能力を持たせます。これにより、クライアントはテキストが発話される際に動的にハイライト表示することができます。このような機能は、先に述べたユースケースにおいて音声に視覚的な支援を提供するために役立ちます。
- ツール・ド・フランスは、ChatGPTとデジタルツインテクノロジーを導入しました
- Googleはカナダに「リンク税」を支払わないと伝え、ニュースリンクを検索から削除すると発表しました
- メタは、プライバシー侵害のチェックに関して、独占禁止法監視機関を支持するEU最高裁判所に敗訴しました
このソリューションは、テキストのハイライト表示以外にもさまざまなタスクを実行するために拡張することができます。例えば、ブラウザはテキストが音声化される際にイメージを表示したり、音楽を再生したり、他のアニメーションを実行したりすることができます。この機能は、動的なオーディオブック、教育コンテンツ、豊かなテキスト読み上げアプリケーションの作成に役立ちます。
ソリューションの概要
このソリューションの核となるのは、Amazon Pollyを使用してテキストを音声に変換することです。テキストはブラウザから入力するか、ソリューションが公開するエンドポイントへのAPI呼び出しによって入力することができます。Amazon Pollyによって生成された音声は、Amazon Simple Storage Service(Amazon S3)バケットにオーディオファイル(MP3形式)として保存されます。
ただし、オーディオファイルだけでは、ブラウザはいつどの部分のテキストが発話されているかを把握することができません。なぜなら、各単語が発話されるタイミングについての詳細な情報を持っていないからです。
Amazon Pollyは、音声マークを使用してこれを取得する方法を提供しています。音声マークは、各単語または文が発話される時刻(オーディオの開始からのミリ秒単位)を示すテキストファイルに保存されます。
Amazon Pollyは、行区切りのJSONストリームで音声マークオブジェクトを返します。音声マークオブジェクトには、次のフィールドが含まれます:
- Time – オーディオストリームの開始からのミリ秒単位のタイムスタンプ
- Type – 音声マークのタイプ(文、単語、ビジーム、またはSSML)
- Start – 入力テキスト内のオブジェクトの開始位置のバイトオフセット(ビジームマークを含まない)
- End – 入力テキスト内のオブジェクトの終了位置のバイトオフセット(ビジームマークを含まない)
- Value – 音声マークのタイプによって異なります:
- SSML – <mark> SSMLタグ
- Viseme – ビジームの名前
- 単語または 文 – 開始および終了フィールドで区切られた入力テキストの部分文字列
例えば、文「メアリーは小さな子羊を持っていた」の場合、API呼び出しでSpeechMarkTypes = [“word”, “sentence”]を使用して音声マークを取得すると、次のような音声マークファイルが得られます:
{"time":0,"type":"sentence","start":0,"end":23,"value":"メアリーは小さな子羊を持っていた。"}
{"time":6,"type":"word","start":0,"end":4,"value":"メアリー"}
{"time":373,"type":"word","start":5,"end":8,"value":"は"}
{"time":604,"type":"word","start":9,"end":10,"value":"小さな"}
{"time":882,"type":"word","start":11,"end":17,"value":"子羊"}
{"time":882,"type":"word","start":18, "end":22,"value":"を持っていた"}行3の末尾にある単語「は」は、オーディオストリーム開始から373ミリ秒後に始まり、入力テキストのバイト5から始まり、バイト8で終了します。
アーキテクチャの概要
私たちのソリューションのアーキテクチャは、次の図に示されています。
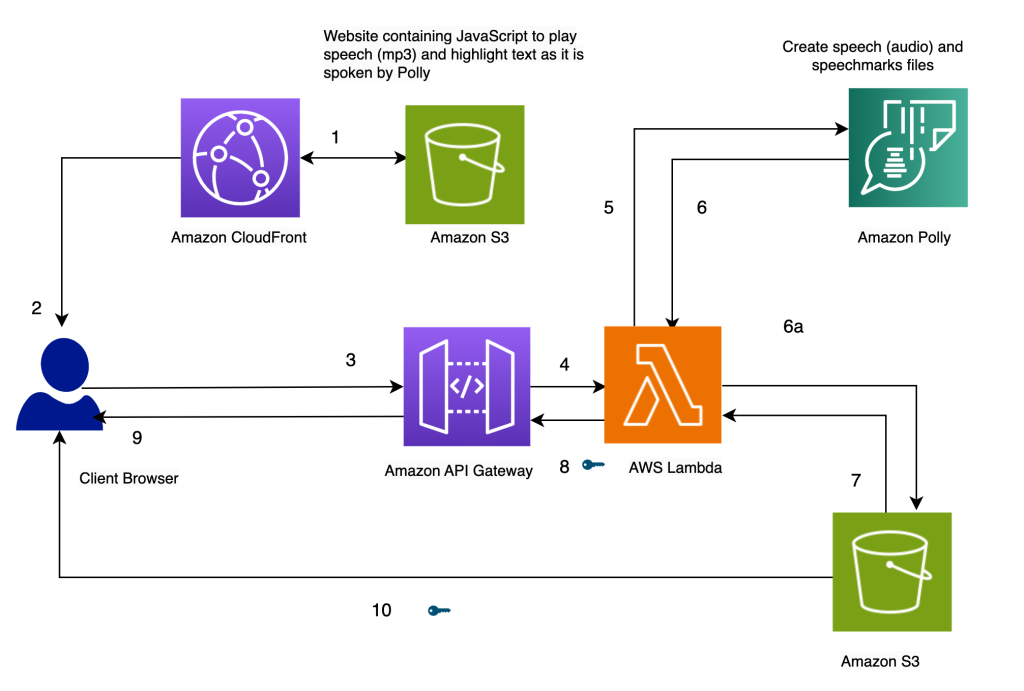
Amazon Pollyを使用して話されるテキストをハイライト表示する
ソリューションのウェブサイトは、Amazon S3に静的ファイル(JavaScript、HTML)として保存され、Amazon CloudFront(1)でホストされてエンドユーザーのブラウザ(2)に提供されます。
ユーザーがブラウザでシンプルなHTMLフォームを介してテキストを入力すると、ブラウザ内のJavaScriptによって処理されます。これにより、Amazon API Gatewayを通じてAPI(3)が呼び出され、AWS Lambda関数(4)が呼び出されます。Lambda関数はAmazon Polly(5)を呼び出して音声(オーディオ)と音声マーク(JSON)ファイルを生成します。音声と音声マークのファイルを取得するために、2つの呼び出しがAmazon Pollyに対して行われます。これらの呼び出しはJavaScriptの非同期関数を使用して行われます。これらの呼び出しの出力は、音声と音声マークのファイルであり、Amazon S3(6a)に保存されます。S3バケットで複数のユーザーがお互いのファイルを上書きすることを防ぐために、ファイルはタイムスタンプを持つフォルダに保存されます。これにより、Amazon S3での複数のユーザーによるファイルの上書きの可能性が最小限に抑えられます。本番リリースでは、ユーザーIDやタイムスタンプなどの一意の特性に基づいてユーザーのファイルを区別するために、より堅牢なアプローチを採用することができます。
Lambda関数は音声と音声マークのファイルに対して事前署名付きURLを作成し、それらをブラウザに配列の形式で返します(7、8、9)。
ブラウザがテキストファイルをAPIエンドポイント(3)に送信すると、同期呼び出しでオーディオファイルと音声マークファイルの2つの事前署名付きURLが返されます(9)。これは、矢印の横に表示されるキーシンボルで示されています。
ブラウザのJavaScript関数は、URLハンドルから音声マークファイルとオーディオを取得し、オーディオプレーヤーをセットアップしてオーディオを再生します(この目的にはHTMLのaudioタグが使用されます)。
ユーザーが再生ボタンをクリックすると、以前のステップで取得した音声マークを解析して、タイムアウトを使用してタイミングイベントのシリーズを作成します。これらのイベントは、話されるテキストをハイライト表示するために使用される別のJavaScript関数であるコールバック関数を呼び出します。同時に、JavaScript関数はURLハンドルからオーディオファイルをストリーミングします。
その結果、イベントは適切なタイミングで実行され、オーディオが再生される間にテキストがハイライト表示されます。JavaScriptのタイムアウトの使用により、オーディオとハイライト表示されるテキストの同期が可能となります。
前提条件
このソリューションを実行するには、Amazon CloudFront、Amazon API Gateway、Amazon Polly、Amazon S3、AWS Lambda、およびAWS Step Functionsを使用する許可を持つAWSアカウントとAWS Identity and Access Management(IAM)ユーザーが必要です。
Lambdaを使用して音声と音声マークを生成する
次のコードは、Amazon Pollyのsynthesize_speech関数を2回呼び出してオーディオと音声マークファイルを取得します。これらは非同期関数として実行され、プロミスを使用して同時に結果を返します。
const p1 = new Promise(doSynthesizeSpeech marks);
const p2 = new Promise(doSynthesizeSpeech);
var result;
await Promise.all([p1, p2])
.then((values) => {
// presigned URLの配列を返す
console.log('Values:', values);
result = { "output" : values };
})
.catch((err) => {
console.log("Error:" + err);
result = err;
});JavaScript側では、テキストのハイライト表示はhighlighter(start, finish, word)によって行われ、setTimers()によってタイミングイベントが設定されます:
function highlighter(start, finish, word) {
let textarea = document.getElementById("postText");
//console.log(start + "," + finish + "," + word);
textarea.focus();
textarea.setSelectionRange(start, finish);
}
function setTimers() {
let speech marksStr = sessionStorage.getItem("speech marks");
// speech marksファイルを読み込み、各単語にタイマーを設定します
console.log(speech marksStr);
let speech marks = speech marksStr.split("\n");
for (let i = 0; i < speech marks.length; i++) {
//console.log(i + ":" + speech marks[i]);
if (speech marks[i].length == 0) {
continue;
}
smjson = JSON.parse(speech marks[i]);
t = smjson["time"];
s = smjson["start"];
f = smjson["end"];
word = smjson["value"];
setTimeout(highlighter, t, s, f, word);
}
}代替手法
前の手法の代わりに、いくつかの代替手法を考慮することができます:
- Step Functionsのステートマシン内でスピーチマークとオーディオファイルの両方を作成します。ステートマシンは並列分岐条件を呼び出して2つの異なるLambda関数を呼び出すことができます。1つはスピーチを生成し、もう1つはスピーチマークを生成します。このコードは、Githubリポジトリのusing-step-functionsサブフォルダにあります。
- Amazon Pollyを非同期で呼び出してオーディオとスピーチマークを生成します。このアプローチは、テキストのコンテンツが大きい場合やユーザーがリアルタイムの応答を必要としない場合に使用することができます。長いオーディオファイルを作成する詳細については、長いオーディオファイルの作成 を参照してください。
- Amazon Pollyに直接署名済みURLを生成させるために、Boto3のAmazon Pollyクライアント上でgenerate_presigned_url呼び出しを使用します。このアプローチを選択すると、Amazon Pollyは毎回オーディオとスピーチマークを新しく生成します。現在のアプローチでは、これらのファイルをAmazon S3に保存しています。このバージョンのコードではブラウザからこれらの保存されたファイルにアクセスすることはできませんが、Amazon S3から再生成する代わりに以前に生成されたオーディオファイルを再生するためにコードを修正することができます。PythonでAmazon Pollyにアクセスするためのより多くのコード例は、AWS Code Libraryにあります。
ソリューションの作成
完全なソリューションは、Githubリポジトリから入手できます。アカウントでこのソリューションを作成するには、README.mdファイルの手順に従ってください。ソリューションには、リソースをプロビジョニングするためのAWS CloudFormationテンプレートが含まれています。
クリーンアップ
このデモで作成されたリソースをクリーンアップするには、次の手順を実行します:
- CloudFormationテンプレートを保存するために作成されたS3バケット(Bucket A)、ソースコードを保存するために作成されたS3バケット(Bucket B)、およびウェブサイト(
pth-cf-text-highlighter-website-[Suffix])を削除します。 - CloudFormationスタック
pth-cfを削除します。 - Amazon Pollyによって生成されたオーディオとスピーチマークファイルを保存するために、CloudFormationテンプレートによって作成されたS3バケット(
pth-speech-[Suffix])を削除します。
サマリー
この記事では、Amazon Pollyを使用してテキストを読み上げる際にテキストをハイライトするソリューションの例を紹介しました。これはAmazon Pollyのスピーチマーク機能を使用して開発されたもので、オーディオファイル内の各単語や文の開始位置にマーカーを提供します。
このソリューションはCloudFormationテンプレートとして利用可能です。これはテキストから音声への変換を行う任意のWebアプリケーションにそのまま展開することができます。これは本のオーディオにビジュアル機能を追加するため、リップシンク機能を持つアバター(ビセメスピーチマークを使用)に役立ちます。また、聴覚障害を持つ人々の支援にも役立ちます。
テキストのハイライト以外にも追加のタスクを実行するために拡張することができます。例えば、テキストが読み上げられる間にブラウザで画像を表示したり、音楽を再生したり、他のアニメーションを実行したりすることができます。この機能は、動的なオーディオブック、教育コンテンツ、より豊かなテキスト読み上げアプリケーションの作成に役立ちます。
以下のリンクから、このソリューションを試してみて、関連するAWSサービスについて詳しく学び、特定のニーズに合わせて機能を拡張してみてください。
- Amazon API Gateway
- Amazon CloudFront
- AWS Lambda
- Amazon Polly
- Amazon S3
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






