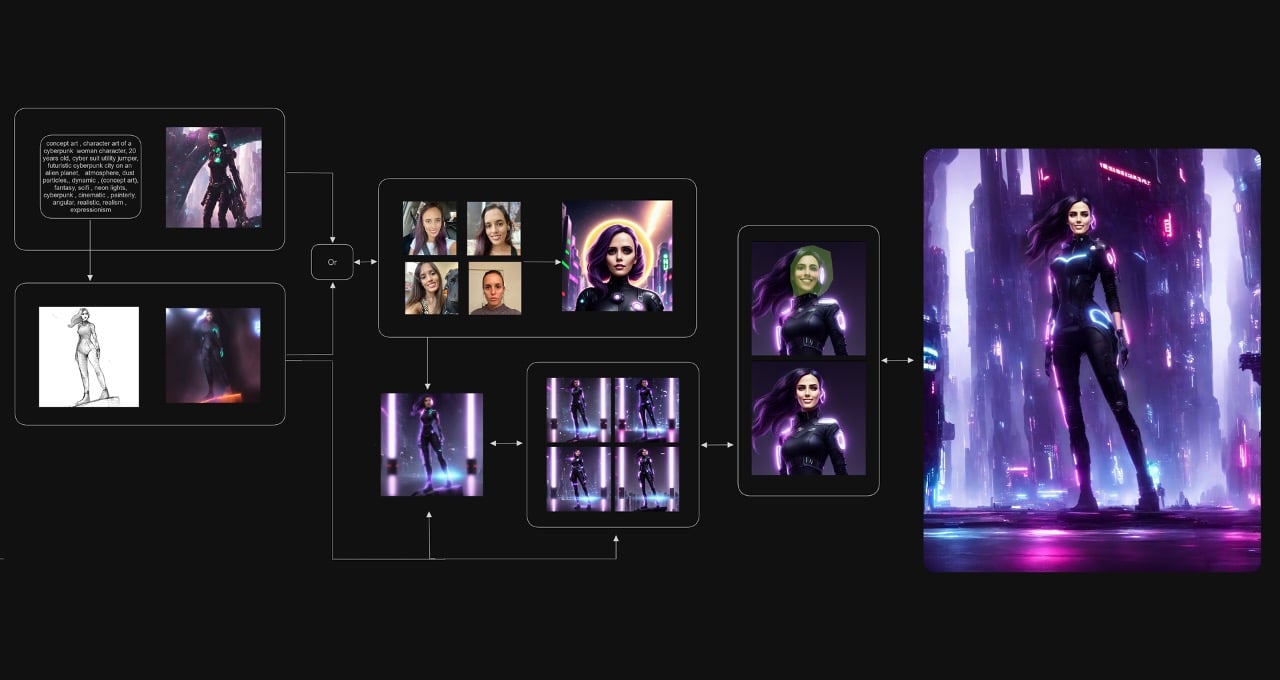
「フューショットラーニングの力を解き放つ」
Unleash the power of Fusion Learning.
はじめに
少数のラベル付きの例だけでタスクを征服し、データのオッズに挑む機械の領域へようこそ。このガイドでは、少数のラベル付き例で偉業を達成するための賢いアルゴリズムがどのように偉大さを実現するかについて探求します。人工知能の新たな可能性を開く少数のデータでのアプローチの概念や、従来の機械学習との違い、データが少ないシナリオでのこのアプローチの重要性について学びましょう。
学習目標
技術的な詳細に入る前に、このガイドの学習目標を概説しましょう:
- 概念を理解し、従来の機械学習との違い、データが少ないシナリオでのアプローチの重要性を理解する
- 少数のデータ学習に使用されるさまざまな手法やアルゴリズム、メトリックベースの手法、モデルベースのアプローチ、およびその基本原理を探索する
- さまざまなシナリオでの少数のデータ学習の技術の適用方法を理解する。効果的なトレーニングと評価のためのベストプラクティスを理解する
- 少数のデータ学習の現実世界の応用を発見する
- 少数のデータ学習の利点と制限を理解する
さあ、ガイドの各セクションについて探求して、これらの目標を達成する方法を理解しましょう。
この記事はデータサイエンスブログマラソンの一部として公開されました。
- 「Keras 3.0 すべてを知るために必要なこと」
- 「MC-JEPAに会おう:動きと内容の特徴の自己教師あり学習のための共同埋め込み予測アーキテクチャ」
- 「新しいHADARベースのイメージングツールにより、暗闇でもクリアに見ることができます」
Few Shot Learningとは何ですか?

Few Shot Learningは、クラスまたはタスクごとに限られた数のラベル付き例からモデルを訓練して認識と一般化を行う機械学習のサブフィールドです。Few Shot Learningは、データに飢えたモデルの従来の概念に挑戦します。大量のデータセットに頼る代わりに、Few Shot Learningはわずかなラベル付きサンプルから学習することを可能にします。限られたデータから一般化する能力は、広範なラベル付きデータセットを入手することが実践的または高価でないシナリオでの驚くべき可能性を開くものです。
新しい概念を素早く把握し、オブジェクトを認識し、複雑な言語を理解し、限られたトレーニング例でも正確な予測を行うモデルを想像してみてください。Few Shot Learningはまさにそれを可能にし、さまざまなドメインでのさまざまな課題へのアプローチ方法を変えています。Few Shot Learningの主な目的は、少ないデータから効果的に学習し、新しい、未見のインスタンスにうまく一般化するためのアルゴリズムと技術を開発することです。これはしばしば事前の知識を活用するか、関連するタスクから情報を利用して新しいタスクに効率的に一般化することを含みます。
従来の機械学習との主な違い
従来の機械学習モデルは通常、トレーニングに多くのラベル付きデータを必要とします。これらのモデルのパフォーマンスは、データの量が増えるにつれて向上します。従来の機械学習では、特に専門的なドメインやラベル付きデータの取得が費用と時間がかかる場合、データの不足は重要な課題となる場合があります。Few Shot Learningモデルは、クラスまたはタスクごとにわずかな例で効果的に学習します。これらのモデルは、クラスごとにわずかな数または1つのラベル付き例のみでトレーニングされても正確な予測を行うことができます。これにより、モデルは少ないラベル付きデータで効果的に学習することで、データの不足問題に対処します。わずかな更新または調整だけで新しいクラスやタスクに素早く適応します。
Few Shot Learningの用語
Few Shot Learningのフィールドでは、学習プロセスやアルゴリズムのさまざまな側面を説明するいくつかの用語と概念があります。Few Shot Learningでよく使われるいくつかの主要な用語:

- サポートセット:サポートセットは、Few Shot Learningタスクのデータセットのサブセットです。データセットの各クラスについて、限られた数のラベル付き例(画像、テキストサンプルなど)を含んでいます。サポートセットの目的は、メタトレーニングフェーズ中にモデルに関連する情報と例を提供し、クラスについて学習と一般化を行うことです。
- クエリセット:クエリセットは、Few Shot Learningタスクのデータセットの別のサブセットです。サポートセットに存在するクラスの一つに分類される必要があるラベルなしの例(画像、テキストサンプルなど)から構成されています。サポートセットでトレーニングした後、モデルのパフォーマンスはクエリセットの例をどれだけ正確に分類できるかによって評価されます。
- N-Way K-Shot:Few Shot Learningでは、「n-way k-shot」という表記法が、各Few Shot Learningエピソードまたはタスクにおけるクラスの数(n)とクラスごとのサポート例の数(k)を表すためによく使われます。たとえば、「5-way 1-shot」は、各エピソードに5つのクラスが含まれ、モデルには各クラスに対して1つのサポート例のみが提供されることを意味します。同様に、「5-way 5-shot」は各エピソードに5つのクラスが含まれ、モデルには各クラスに5つのサポート例が提供されることを意味します。
Few Shot Learning Techniques
メトリックベースのアプローチ
- Siamese Networks:シャミーズネットワークは、入力サンプルの埋め込み(表現)を計算し、その埋め込みを類似性に基づいた分類のための距離メトリックと比較することを学習します。2つの入力間の類似性を比較し、特に各クラスに例が存在する場合に特に有用です。Few-shot learningの文脈では、シャミーズネットワークを使用して、サポートセットの例とクエリセットの例の間の類似性メトリックを学習します。サポートセットにはラベル付きの例(例:クラスごとに1つまたは数個の例)が含まれており、クエリセットにはサポートセットに存在するクラスのいずれかに分類する必要のあるラベルのない例が含まれています。
- Prototypical Networks:Few-shot learningタスクで人気で効果的なアプローチです。プロトタイプネットワークは、各クラスの「プロトタイプ」と呼ばれるものを使用し、それはfew-shotの例の平均埋め込みです。推論中、クエリサンプルはプロトタイプを比較してクラスを決定します。キーのアイデアは、各クラスを、サポートセットの例の特徴の埋め込みの平均として計算されるプロトタイプベクトルによって表現することです。推論中、クエリの例は、異なるクラスのプロトタイプに対する近さに基づいて分類されます。これらは計算効率が高く、複雑なメタ学習戦略を必要とせず、コンピュータビジョンや自然言語処理などのさまざまなドメインでの実用的な実装の人気の選択肢となっています。
モデルベースのアプローチ
- Memory-Augmented Networks:Memory-Augmented Networks(MANNs)は、few-shotの例から情報を格納するための外部メモリを使用します。分類中に関連する情報を取得するために、アテンションメカニズムを使用します。MANNは、通常のニューラルネットワークの制約を克服することを目指しており、大きな文脈情報や長距離の依存関係を必要とするタスクに苦労することがよくあります。MANNの背後にあるキーのアイデアは、モデルに情報を読み書きできるメモリモジュールを装備することで、モデルにトレーニング中に関連する情報を格納し、推論中に使用することを可能にすることです。この外部メモリは、モデルがアクセスおよび更新できる追加のリソースであり、推論中の推論と意思決定を促進するために使用できます。
- Meta-Learning(学習するための学習):メタ学習は、様々なタスクを持つメタトレーニングフェーズに基づいてモデルを新しいタスクに素早く適応させることで、few-shot learningを改善することを目指しています。メタ学習の基本的なアイデアは、モデルが前の経験から知識を抽出し(メタトレーニング)、その知識を新しい、未知のタスクに素早く適応させる(メタテスト)ことです。メタ学習は、「メタ知識」または「先行知識」という概念を導入することで、モデルの学習プロセスをガイドすることで、これらの課題に対処します。
- Gradient-Based Meta-Learning(例:MAML):勾配ベースのメタ学習は、メタテスト中に新しいタスクに対してモデルパラメータを修正して、より速い適応を容易にします。MAMLの主な目標は、わずかな例だけで新しいタスクに素早く適応することを可能にすることです。few-shot learningやメタ学習のシナリオでは、このテーマは中心的な役割を果たしています。
Few Shot Learningの応用
Few-shot learningは、さまざまな領域で数多くの実用的な応用があります。以下はいくつかの注目すべきfew-shot learningの応用例です。
- 画像分類と物体認識:画像分類のタスクでは、モデルは限られたラベル付きの例でオブジェクトを素早く認識して分類することができます。特にトレーニングデータセットに存在しないまれなまたは新しいオブジェクトを認識するのに役立ちます。
- 自然言語処理:NLPでは、few-shot learningを使用して、感情分析、テキスト分類、および固有表現認識などのタスクを少ないラベル付きデータで実行することができます。ラベル付きのテキストデータが少ないか、入手が困難なシナリオで有益です。
- 医療診断とヘルスケア:few-shot learningは、医療画像解析と診断において有望です。限られた医療データを使用して、まれな病気の特定、異常の検出、および患者の結果の予測に役立つことができます。
- レコメンデーションシステム:少数のユーザーのインタラクションや好みに基づいて、ユーザーに個別にカスタマイズされたコンテンツや製品を提案します。
- 個別化されたマーケティングと広告:少ない顧客データに基づいて、特定の顧客セグメントをターゲットにした個別化されたマーケティングキャンペーンをビジネスに支援します。
Few Shot Learningの利点
- データ効率性:few-shot learningは、クラスごとにわずかな数のラベル付き例だけを必要とするため、データ効率性が非常に高いです。大規模なラベル付きデータセットの取得が高価または実用的でない場合に特に有利です。
- 新しいタスクへの一般化:few-shot learningモデルは、わずかなラベル付きの例で新しいタスクやクラスに素早く適応する能力に優れています。この柔軟性により、未知のデータを効率的に処理できるため、動的で進化する環境に適しています。
- 迅速なモデルトレーニング:処理する例が少ないため、従来の機械学習モデルと比較してモデルのトレーニングが迅速に行われます。
- データの希少性の処理:データの希少性の問題に直接対処し、特定のクラスやタスクのためにトレーニングデータが少ないか利用できない場合でも、モデルが良好なパフォーマンスを発揮します。
- 転移学習:few-shot learningモデルは、転移学習の能力を持っています。few-shotのクラスからの知識は、関連するタスクやドメインのパフォーマンスを向上させるために転移されます。
- 個別化とカスタマイズ:モデルは個々のユーザーの好みや特定の要件に素早く適応できるため、個別化およびカスタマイズされたソリューションを容易にします。
- 注釈作業の軽減:手動のデータ注釈の負担を軽減し、少ないラベル付きの例でトレーニングを行い、時間とリソースを節約します。
制約事項
- クラスの識別の限定: 設定には、微細なクラスの違いを捉えるための十分な例が提供されない場合があり、関連するクラスの識別能力が低下する可能性があります。
- 少数例への依存: モデルは、トレーニング中に提供される少数の例の品質と代表性に大きく依存しています。
- タスクの複雑さ: 少数例学習は、データの複雑なパターンをより深く理解することを要求する高度に複雑なタスクに苦労する場合があります。より多くのラベル付きの例や異なる学習パラダイムが必要になる場合があります。
- ノイズへの脆弱性: 学習にはより少ないデータポイントが必要なため、ノイズや誤ったラベル付け例に対してより敏感です。
- データ分布のシフト: モデルは、テストデータの分布が少数例のトレーニングデータの分布と大幅に異なる場合に苦労する可能性があります。
- モデル設計の複雑さ: 効果的な少数例学習モデルの設計には、より複雑なアーキテクチャとトレーニング手法がしばしば必要であり、これは困難で計算コストがかかることがあります。
- 外れ値の扱いの難しさ: モデルは、トレーニング中に見られる少数例の例とは大きく異なる外れ値や珍しいインスタンスに苦労する場合があります。
少数例学習の実用的な実装
少数例画像分類の例を見てみましょう。

異なるオブジェクトの画像をそれぞれのクラスに分類します。画像は「猫」、「犬」、「チューリップ」という3つのクラスに属しています。分類の目標は、クエリ画像がサポートセット内のクラスのプロトタイプとの類似性に基づいて、クエリ画像のクラスラベル(「猫」、「犬」、「チューリップ」)を予測することです。最初のステップはデータの準備です。少数例学習データセットを取得し、各タスクごとにサポート(ラベル付き)セットとクエリ(ラベルなし)セットに分割します。データセットがモデルがデプロイ時に遭遇する現実のシナリオを表していることを確認します。ここでは、動物や植物のさまざまな種を含む多様な画像データセットを収集し、それぞれのクラスでラベル付けします。各タスクに対して、サポートセットとしていくつかの例(例:1から5枚の画像)をランダムに選択します。
これらのサポート画像は、モデルに特定のクラスについて「教える」ために使用されます。同じクラスの画像はクエリセットを形成し、モデルの未知のインスタンスの分類能力を評価します。サポートセットの画像を増やすために、ランダムな回転、反転、または明るさの調整などのデータ拡張技術を適用します。データ拡張は、サポートセットの適切なサイズを増やし、モデルの頑健性を向上させるのに役立ちます。データをサポートセットと対応するクエリセットからなるペアまたはミニバッチに整理します。
例
例えば、少数例タスクは次のようになります:
1:
- サポートセット:[cat_1.jpg、cat_2.jpg、cat_3.jpg]
- クエリセット:[cat_4.jpg、cat_5.jpg、cat_6.jpg、cat_7.jpg]
2:
- サポートセット:[dog_1.jpg、dog_2.jpg]
- クエリセット:[dog_3.jpg、dog_4.jpg、dog_5.jpg、dog_6.jpg]
3:
- サポートセット:[tulip_1.jpg、tulip_2.jpg]
- クエリセット:[tulip_3.jpg、tulip_4.jpg、tulip_5.jpg、tulip_6.jpg]
など、これに続きます…
import numpy as np
import random
# 画像と対応するクラスラベルのサンプルデータセット
dataset = [
{"image": "cat_1.jpg", "label": "猫"},
{"image": "cat_2.jpg", "label": "猫"},
{"image": "cat_3.jpg", "label": "猫"},
{"image": "cat_4.jpg", "label": "猫"},
{"image": "dog_1.jpg", "label": "犬"},
{"image": "dog_2.jpg", "label": "犬"},
{"image": "dog_3.jpg", "label": "犬"},
{"image": "dog_4.jpg", "label": "犬"},
{"image": "tulip_1.jpg", "label": "チューリップ"},
{"image": "tulip_2.jpg", "label": "チューリップ"},
{"image": "tulip_3.jpg", "label": "チューリップ"},
{"image": "tulip_4.jpg", "label": "チューリップ"},
]
# データセットをシャッフル
random.shuffle(dataset)
# 少数例タスクのためにデータセットをサポートセットとクエリセットに分割
num_support_examples = 3
num_query_examples = 4
few_shot_task = dataset[:num_support_examples + num_query_examples]
# サポートセットとクエリセットの準備
support_set = few_shot_task[:num_support_examples]
query_set = few_shot_task[num_support_examples:]#import csv画像の読み込みをシミュレートするために、load_imageという単純な関数が定義されており、画像の特徴抽出(埋め込み)をシミュレートするためにget_embeddingという別の関数が定義されています。この実装では、load_image関数はPyTorchのtransformsを使用して画像を前処理し、テンソルに変換します。この関数は、PyTorchモデルハブから事前学習済みのResNet-18モデルを読み込み、画像に対して順方向のパスを実行し、中間の畳み込み層から特徴を抽出します。特徴をNumPy配列に変換して返し、few-shot学習の例で埋め込みと距離を計算します。
def load_image(image_path):
image = Image.open(image_path).convert("RGB")
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return transform(image)
# 事前学習済みのCNN(例:ResNet-18)を使用して画像の特徴埋め込みを生成する
def get_embedding(image):
model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=True)
model.eval()
with torch.no_grad():
image = image.unsqueeze(0) # 画像テンソルにバッチ次元を追加する
features = model(image) # 特徴を取得するためにモデルを順方向に実行する
# 特徴埋め込みを返す(テンソルをフラット化する)
return features.squeeze().numpy()Few-shot学習の手法
タスクの要件と利用可能なリソースに基づいて適切なFew-shot学習の手法を選択してください。
# サポートセット内の各クラスにプロトタイプを作成する
class_prototypes = {}
for example in support_set:
image = load_image(example["image"])
embedding = get_embedding(image)
if example["label"] not in class_prototypes:
class_prototypes[example["label"]] = []
class_prototypes[example["label"]].append(embedding)
for label, embeddings in class_prototypes.items():
class_prototypes[label] = np.mean(embeddings, axis=0)
for query_example in query_set:
image = load_image(query_example["image"])
embedding = get_embedding(image)
distances = {label: np.linalg.norm(embedding - prototype) for label,
prototype in class_prototypes.items()}
predicted_label = min(distances, key=distances.get)
print(f"クエリ画像:{query_example['image']}、予測されたラベル:{predicted_label}")これは、Prototypical Networksを使用した画像分類のFew-shot学習の基本的なセットアップです。コードはサポートセット内の各クラスのプロトタイプを作成します。プロトタイプは、同じクラスのサポート例の埋め込みの平均として計算されます。プロトタイプは、各クラスの特徴空間の中心点を表します。クエリセット内の各クエリ例に対して、コードはクエリ例の埋め込みとサポートセット内の各クラスのプロトタイプとの距離を計算します。計算された距離に基づいて、クエリ例は最も近いプロトタイプを持つクラスに割り当てられます。最後に、コードはFew-shot学習プロセスに基づいて、クエリ画像のファイル名と予測されたクラスラベルを出力します。
# 損失関数(ユークリッド距離)
def euclidean_distance(a, b):
return np.linalg.norm(a - b)
# 予測されたクラスに対する損失(負の対数尤度)を計算する
query_label = query_example["label"]
loss = -np.log(np.exp(-euclidean_distance(query_set_prototype,
class_prototypes[query_label])) / np.sum(np.exp(-euclidean_distance(query_set_prototype,
prototype)) for prototype in class_prototypes.values()))
print(f"クエリ例の損失:{loss}")クエリセットのプロトタイプと各クラスのプロトタイプの間の距離を計算した後、予測されたクラスの損失を負の対数尤度(クロスエントロピー損失)を使用して計算します。損失は、クエリセットのプロトタイプと正しいクラスのプロトタイプとの間の距離が大きい場合、モデルにペナルティを課し、この距離を最小化し、クエリ例を正しく分類するように促します。
これは基本的な実装でした。以下は、トレーニングプロセスを含むPrototypical Networksを使用したFew-shot学習の完全な実装です。
import numpy as np
import random
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.optim import Adam
from PIL import Image
# 画像と対応するクラスラベルのサンプルデータセット
# ... (前の例と同じ)
# データセットをシャッフルする
random.shuffle(dataset)
# フューショットタスク用にサポートセットとクエリセットにデータセットを分割する
num_support_examples = 3
num_query_examples = 4
few_shot_task = dataset[:num_support_examples + num_query_examples]
# サポートセットとクエリセットを準備する
support_set = few_shot_task[:num_support_examples]
query_set = few_shot_task[num_support_examples:]
# 画像の読み込みとテンソルへの変換を行うヘルパー関数
def load_image(image_path):
image = Image.open(image_path).convert("RGB")
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
return transform(image)
# 事前学習済みのCNN(例:ResNet-18)を使用して画像の特徴埋め込みを生成する
def get_embedding(image):
model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=True)
model.eval()
# モデルの畳み込み層から画像の特徴を抽出する
with torch.no_grad():
image = image.unsqueeze(0) # 画像テンソルにバッチ次元を追加する
features = model(image) # 特徴を取得するためにモデルを順方向に実行する
# 特徴埋め込みを返す(テンソルをフラット化する)
return features.squeeze()
# Prototypical Networksモデル
class PrototypicalNet(nn.Module):
def __init__(self, input_size, output_size):
super(PrototypicalNet, self).__init__()
self.input_size = input_size
self.output_size = output_size
self.fc = nn.Linear(input_size, output_size)
def forward(self, x):
return self.fc(x)
# トレーニング
num_classes = len(set([example['label'] for example in support_set]))
input_size = 512 # 特徴埋め込みのサイズ(CNNの出力)
output_size = num_classes
# Prototypical Networksモデルの作成
model = PrototypicalNet(input_size, output_size)
# 損失関数(クロスエントロピー)
criterion = nn.CrossEntropyLoss()
# オプティマイザ(Adam)
optimizer = Adam(model.parameters(), lr=0.001)
# トレーニングループ
num_epochs = 10
for epoch in range(num_epochs):
model.train() # モデルをトレーニングモードに設定する
for example in support_set:
image = load_image(example["image
この完全な実装では、シンプルなプロトタイプネットワークモデルを定義し、クロスエントロピー損失とAdamオプティマイザを使用してトレーニングを行います。トレーニング後、トレーニングされたモデルを使用してプロトタイプネットワークアプローチに基づいてクエリの例を分類します。
今後の方向性と潜在的な応用
この分野は驚異的な進展を示していますが、まだ進化中であり、多くの有望な今後の方向性と潜在的な応用があります。以下に、今後のキーエリアをいくつか示します:
- メタラーニングの継続的な進展:さらなる発展が予想されます。最適化アルゴリズム、アーキテクチャ設計、メタラーニング戦略の改善により、より効率的で効果的なフューショットラーニングモデルが実現する可能性があります。カタストロフィックフォーゲッティングの課題やメタラーニング手法の拡張性に対する研究は進行中です。
- ドメイン知識の組み込み:フューショットラーニングアルゴリズムにドメイン知識を組み込むことで、異なるタスクとドメイン間での知識の一般化と転送能力が向上する可能性があります。フューショットラーニングを記号的推論や構造化知識表現と組み合わせることも有望です。
- 階層的フューショットラーニングの探索:タスクとクラスが階層的に組織化される階層的な設定の拡張は、モデルがクラスとタスク間の階層的な関係を利用し、より良い一般化を実現することができます。
- フューショット強化学習:フューショットラーニングを強化学習と統合することで、エージェントが限られた経験で新しいタスクを学習することが可能になります。この領域は特にロボット制御や自律システムに関連しています。
- 実世界の応用への適応:医療診断、薬剤探索、個別化推薦システム、適応型チュータリングなど、アプリケーションと実世界のシナリオは非常に有望です。将来の研究は、特定のドメインに特化した専門のフューショットラーニング技術の開発に焦点を当てる可能性があります。
結論
これはAIと機械学習の魅力的なサブフィールドであり、最小限のデータでモデルをトレーニングするという課題に取り組んでいます。このブログでは、その定義、従来の機械学習との違い、プロトタイプネットワーク、医療診断や個別化推薦などの実世界の応用について探求しました。メタラーニング、グラフニューラルネットワーク、アテンションメカニズムなどのエキサイティングな研究方向は、AIを迅速に適応させて正確な予測を実現します。
AIを民主化し、限られたデータでの適応性を可能にすることで、より広範なAIの採用が可能になります。未利用のポテンシャルを引き出すためのこの旅路は、機械と人間が調和して共存し、より知的で有益なAIの景観を形作る未来につながるでしょう。
キーアウト
- フューショットラーニングは、限られたラベル付きの例でモデルをトレーニングするという課題に取り組む、魅力的な人工知能と機械学習のサブフィールドです。
- プロトタイプネットワークは、限られたラベル付きデータで適応し効率的に予測するための強力な技術です。
- 医療診断や個別化推薦などの実世界の応用において、フューショットラーニングはその柔軟性と実用性を示しています。大量のラベル付きデータへの依存を減らすことで、AIの民主化が可能になる可能性があります。
よくある質問
この記事で表示されているメディアはAnalytics Vidhyaの所有ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles