複数の画像やテキストの解釈 Representation Learning

In this translation, Notes is translated to メモ (memo), CLIP remains as CLIP, Connecting is translated to 連結 (renketsu), Text is translated to テキスト (tekisuto), and Images is translated to 画像 (gazo).
上記論文の著者たちは、最小限またはほとんど監督を必要とせずに、さまざまなタスクに使用できる画像の良い表現(特徴)を生...

BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
『今日の論文分析では、BYOL(Bootstrap Your Own Latent)の背後にある論文に詳しく触れますこれは、対比的な自己教師あり学...
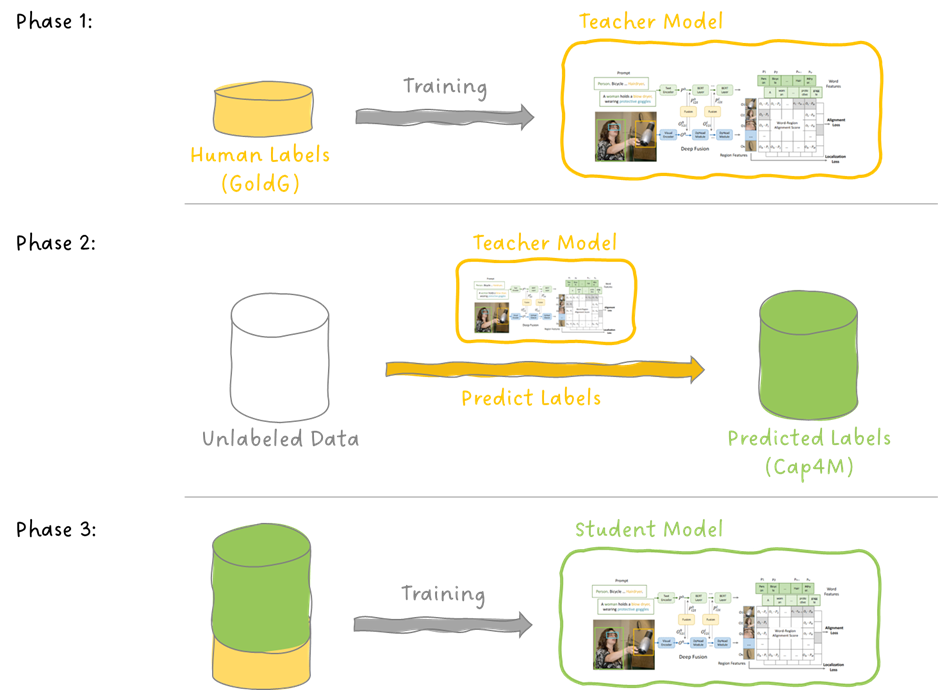
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げ...

- You may be interested
- ベルマン-フォードアルゴリズム:重み付き...
- イメージセグメンテーション:詳細ガイド
- AI時代の運転:AIへの恐怖が命を奪う代償...
- アーサーがベンチを発表:仕事に最適な言...
- AIの闇面──クリエイターはどのように助け...
- 「LLaSMと出会う:音声と言語の指示に従う...
- 「量子世界での秘密の保持」
- 創造的AIの進展により、責任あるAIに対処...
- 「たった1行のコードで、Optimum-NVIDIAが...
- 「オープンソースLLMの完全ガイド」
- 「ストリーミングLLMの紹介 無限長の入力...
- 「浙江大学の研究者がUrbanGIRAFFEを提案...
- 新時代の幕開け:「エイジ オブ エンパイ...
- ノイズ除去オートエンコーダの公開
- 「Hugging Faceを使用してAmazon SageMake...
Find your business way
Globalization of Business, We can all achieve our own Success.