複数の画像やテキストの解釈 Fine Tuning Transformer

テキストをベクトルに変換する:TSDAEによる強化埋め込みの非教示アプローチ
TSDAEの事前学習を対象ドメインで行い、汎用コーパスでの教師付き微調整と組み合わせることで、特化ドメインの埋め込みの品質...
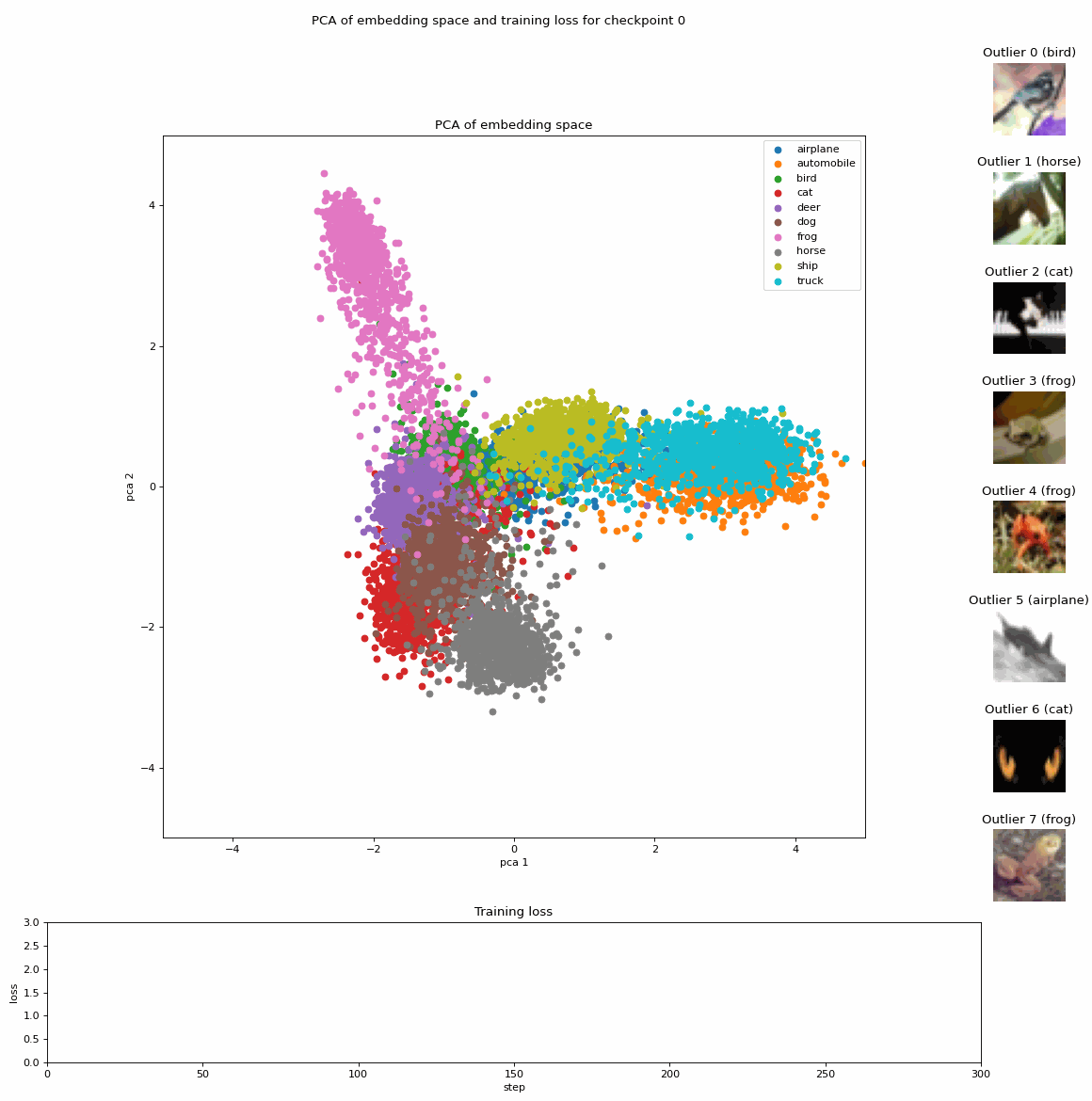
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラル...

- You may be interested
- 「AIライティング革命のナビゲーション:C...
- ODSCのAI週間まとめ:12月8日の週
- ミストラルAIは、パワフルなスパースな専...
- AIコーディングツールが登場しました:製...
- アルゴリズムが加齢による眼の病気の早期...
- 「ジョンズホプキンスのこの論文は、時間...
- スタンフォードの研究者たちはPLATOを発表...
- データの可視化 複雑な情報を効果的に提示...
- NVIDIA CEO:クリエイターは生成的AIによ...
- MITとETH Zurichの研究者たちが、動的なセ...
- OpenAIのLLMの支配を覆すことを目指す挑戦...
- 「SASが実践者のキャリアを加速するのにど...
- AIが想像を絶する抗体を作成します:LabGe...
- 安全な対話エージェントの構築
- 「最高のAIプレゼンテーション生成ツール1...
Find your business way
Globalization of Business, We can all achieve our own Success.