複数の画像やテキストの解釈 Computer Vision - Section 28

『AnomalyGPTとは:産業異常を検出するための大規模ビジョン言語モデル(LVLM)に基づく新しいIADアプローチ』
自然言語処理(NLP)のさまざまなタスクにおいて、GPT-3.5やLLaMAなどの大規模言語モデル(LLM)は優れたパフォーマンスを示...

マイクロソフトの研究者は、2段階の介入フレームワークを使用したオープンボキャブラリー責任ある視覚合成(ORES)を提案しています
ビジュアル合成モデルは、大規模なモデルトレーニングの進歩により、ますます現実的なビジュアルを生成することができるよう...
「マルチタスクアーキテクチャ:包括的なガイド」
多くのタスクを実行するためにニューラルネットワークを訓練することは、マルチタスク学習として知られていますこの投稿では...

チューリッヒ大学の研究者たちは、スイフトという自律型ビジョンベースのドローンを開発しましたこのドローンは、いくつかの公平なヘッドトゥヘッドレースで人間の世界チャンピオンに勝つことができます
ファーストパーソンビュー(FPV)ドローンレーシングは、特殊なFPVゴーグルを使用してパイロットがファーストパーソン視点か...

「NTUシンガポールの研究者たちは、テキストから3D生成のための新しいプラグアンドプレイなリファインメントAIメソッドであるIT3Dを提案しています」
テキストから画像への領域で注目すべき進歩があり、研究コミュニティ内で3D生成への拡大に対する熱意の急増が起きています。...
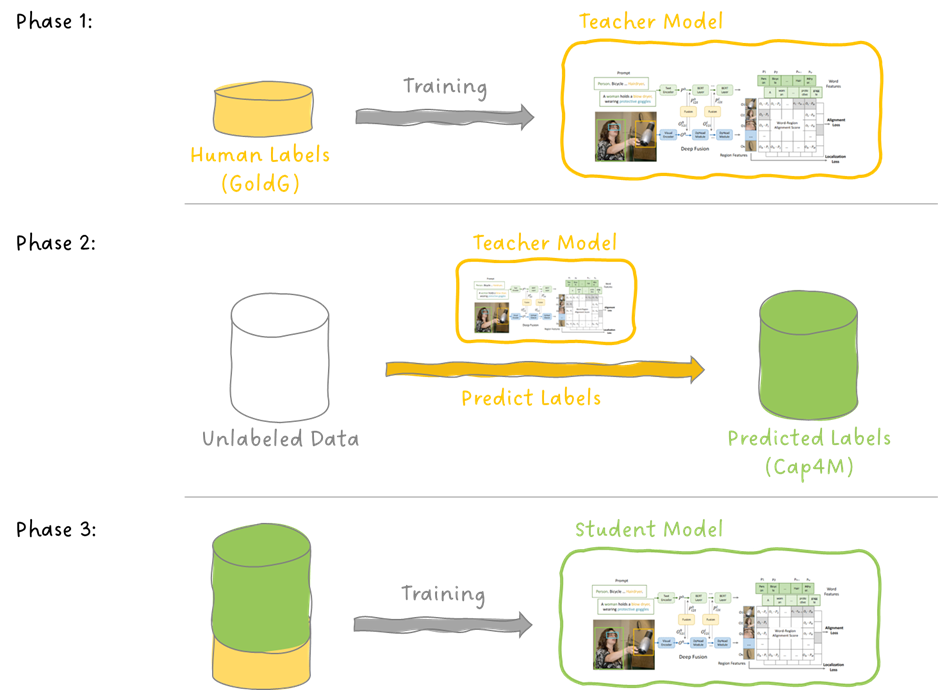
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げ...

「ニューヨーク大学の研究者が、人の見かけの年齢を画像内で変える新しい人工知能技術を開発しましたが、その人の独自の識別特徴を維持します」
AIシステムは、画像解析を使用して個人の年齢を正確に推定および変更するために、ますます使用されています。老化の変動に堅...

Googleとジョージア工科大学の研究者が、セグメンテーションマスクを作成するための直感的な後処理AIメソッドであるDiffSegを紹介しました
セマンティックセグメンテーションとして知られるコンピュータビジョンのタスクの目的は、画像内の各ピクセルにクラスまたは...

「S-LabとNTUの研究者が、シーニメファイ(Scenimefy)を提案しましたこれは、現実世界の画像から自動的に高品質なアニメシーンのレンダリングを行うための画像対画像翻訳フレームワークであり、セミスーパーバイズド(半教師付き)手法を採用しています」
アニメの風景は創造力と時間を大量に必要とするため、自動的なシーンのスタイル化のための学習ベースの手法の開発には明らか...

「岩石とAIの衝突:鉱物学とゼロショットコンピュータビジョンの交差点」
鉱物は、定義された化学組成と結晶構造を持つ天然の無機物です。彼らは岩の構成要素であり、さまざまな地質学的および産業プ...

- You may be interested
- 「LangChainとGPT-3を使用して、ドキュメ...
- 「AIに関するアレン研究所の研究者らが、...
- エッジAIアプリケーションでのパフォーマ...
- 「大規模な言語モデルが医療テキスト分析...
- 「マスタリングモンテカルロ:より良い機...
- 「ゼロトラストネットワークアクセス(ZTN...
- 「Amazon SageMaker Data WranglerでAWS L...
- 「FP8を用いたPyTorchトレーニング作業の...
- Hugging Faceにおける推論ソリューション...
- Googleと一緒にジェネレーティブAIを学ぶ
- 「人間の偏見がAIによるソリューションを...
- 人工知能を規制するための競争
- 新しい価格設定をご紹介します
- 「明日のニュースを、今日に!」ニュースG...
- パロアルトネットワークスは、Cortex XSIA...
Find your business way
Globalization of Business, We can all achieve our own Success.