SEER:セルフスーパーバイズドコンピュータビジョンモデルの突破口?
SEER A breakthrough in self-supervised computer vision models?
過去10年間、人工知能(AI)と機械学習(ML)は著しい進歩を遂げてきました。今日では、これまで以上に正確で効率的で能力を持ったものとなっています。現代のAIとMLモデルは、画像やビデオファイルでオブジェクトをシームレスかつ正確に認識することができます。また、人間の知能に匹敵するテキストや音声を生成することも可能です。
現在のAI&MLモデルは、テキストのブロックを解釈したり、画像やビデオフレームでオブジェクトを識別したりする方法を学ぶために、ラベル付きのデータセットのトレーニングに強く依存しています。また、その他のタスクにも対応しています。
しかし、AI&MLモデルは完璧ではなく、科学者たちは与えられた情報から学習することができるモデルを構築するために取り組んでいます。これは「自己教師あり学習」として知られており、現在のAIモデルの能力を超える問題を解決するために「常識」や背景知識を持つMLおよびAIモデルを構築するための最も効率的な方法の一つです。
自己教師あり学習は、自然言語処理の分野で既に成果を上げており、開発者が大量のデータを処理できる大規模なモデルをトレーニングすることを可能にし、自然言語推論、機械翻訳、質問応答の分野でいくつかの突破口を生み出しています。
Facebook AIのSEERモデルは、自己教師あり学習の能力を最大限に活用することを目指してコンピュータビジョンの分野で開発されました。SEER(SElf SupERvised)は、インターネット上で適切な注釈やラベルがないランダムな画像グループでもパターンを見つけたり学習したりすることができる、数十億のパラメータを持つ自己教師ありコンピュータビジョン学習モデルです。
コンピュータビジョンにおける自己教師あり学習の必要性
データの注釈やラベリングは、機械学習や人工知能モデルの開発における前処理の段階です。データの注釈プロセスは、画像やビデオフレームなどの生データを識別し、モデルのためにデータの文脈を指定するためのラベルを追加します。これらのラベルにより、モデルはデータに対して正確な予測を行うことができます。
コンピュータビジョンモデルを開発する際に開発者が直面する最大の障壁の一つは、高品質の注釈付きデータを見つけることです。現在のコンピュータビジョンモデルは、画像内のオブジェクトを認識するためにこれらのラベル付きまたは注釈付きデータセットに依存しています。
データの注釈とコンピュータビジョンモデルの使用は、以下のような課題を抱えています:
一貫したデータセットの品質の管理
開発者が直面する最大の障壁の一つは、高品質のデータセットに一貫してアクセスすることです。高品質なデータセットは、適切なラベルと明確な画像を持つため、学習やモデルの正確性につながります。しかし、一貫して高品質なデータセットにアクセスすることには、独自の課題があります。
労働力の管理
データのラベリングは、品質を確保しながら非構造化でラベルのない大量のデータを処理・ラベリングするため、労働力の管理の問題を伴います。したがって、データのラベリングにおいて品質と量のバランスを取ることが開発者にとって重要です。
財政上の制約
最大の障壁は、データのラベリングプロセスに伴う財政上の制約です。データのラベリングコストは、プロジェクト全体のコストの大部分を占めることが多いです。
ご覧の通り、データの注釈は、特に大量のトレーニングデータを処理する複雑なモデルを開発する際に、高いハードルとなります。そのため、コンピュータビジョン業界では、現在のモデルの範囲を超えるタスクに対処できる複雑で高度なコンピュータビジョンモデルを開発するために、自己教師あり学習が必要とされています。
以上を踏まえると、制御された環境で既に優れた成績を収めている自己教師あり学習モデルはたくさんありますが、これらのモデルはコンピュータビジョンにおける自己教師あり学習の主要な条件を満たしていません。すなわち、「限定されたデータセットや特定の画像に学ぶのではなく、非制約のデータセットやランダムな画像から学ぶ」ということです。理想的に実装された場合、自己教師あり学習は、より正確で能力の高いコンピュータビジョンモデルの開発に役立ち、費用効果の高い実現可能なモデルを構築することができます。
SEERまたは自己教師ありモデル:紹介
AI&ML業界の最新動向によると、半教師あり学習、弱教師あり学習、自己教師あり学習などのモデルの事前トレーニング手法は、ほとんどのディープラーニングモデルのパフォーマンスを大幅に向上させることが示されています。
これらのディープラーニングモデルのパフォーマンス向上には、2つの主要な要素が大きく貢献しています。
巨大データセットでの事前トレーニング
巨大データセットでの事前トレーニングは、一般的にはより高い精度とパフォーマンスをもたらします。なぜなら、モデルにさまざまなデータに触れさせるためです。大規模なデータセットは、モデルがデータのパターンをより良く理解することを可能にし、結果としてモデルが実際のシナリオでより良いパフォーマンスを発揮するようになります。
GPT-3モデルやWav2vec 2.0モデルなどの最高のパフォーマンスを発揮するモデルのいくつかは、巨大なデータセットでトレーニングされています。GPT-3言語モデルは、3000億語以上の事前トレーニングデータセットを使用しており、一方、音声認識のためのWav2vec 2.0モデルは、53000時間以上のオーディオデータを使用しています。
巨大な容量を持つモデル
パラメータの数が多いモデルは、しばしば正確な結果を生み出します。なぜなら、より多くのパラメータを持つことで、モデルがデータ内の必要なオブジェクトにだけ焦点を当てることができるからです。過去においては、非ラベルまたは非整理データを使用して自己教師あり学習モデルをトレーニングする試みがありましたが、わずか数百万枚の画像しか含まれていない小規模なデータセットを使用していました。しかし、大量のラベルのない、非整理のデータを使用して自己教師あり学習モデルをトレーニングすると、高い精度が得られるのでしょうか?それがSEERモデルが答えを出すことを目指している正確にその質問です。
SEERモデルは、キュレーションやラベル付けされたデータセットに依存せずにインターネット上で利用可能な画像を登録することを目指すディープラーニングフレームワークです。SEERフレームワークでは、開発者が大規模で複雑なMLモデルを追加の手動入力なしでランダムなデータにトレーニングすることができます。つまり、モデルはデータを分析し、パターンや情報を自己学習するのです。
SEERモデルの最終目標は、キュレーションされていないデータを使用して事前トレーニングプロセスの戦略を開発し、転移学習で最先端のパフォーマンスを提供することです。さらに、SEERモデルは、自己教師ありの方法で絶え間ないデータのストリームから継続的に学習するシステムの創造も目指しています。
SEERフレームワークは、インターネットから抽出された数十億ものランダムで制約のない画像に対して高容量モデルをトレーニングします。これらの画像でトレーニングされたモデルは、画像のメタデータや注釈に依存せず、モデルをトレーニングしたり、データをフィルタリングしたりする必要がありません。近年、自己教師あり学習は、キュレーションされていないデータに対してモデルをトレーニングすることで、転移学習のための教師あり事前学習モデルと比較して、より良い結果が得られる可能性が高いことが示されています。
SEERフレームワークとRegNet:何がつながっているのか?
SEERモデルを分析するために、SEERの目標であるキュレーションされていないデータでの自己教師あり学習に合致するRegNetアーキテクチャに焦点を当てます。RegNetは、以下の2つの主要な理由から、パフォーマンスと効率のバランスを提供します。
- パフォーマンスと効率の完璧なバランスを提供します。
- 非常に柔軟で、パラメータの数をスケーリングするために使用できます。
SEERフレームワーク:異なる領域からの事前研究
SEERフレームワークは、自己教師あり学習を使用してキュレーションされていないまたはラベルのないデータセットで大規模なモデルアーキテクチャのトレーニングの限界を探求することを目指しており、このモデルはフィールド内の以前の研究からインスピレーションを受けています。
視覚特徴の教師なし事前トレーニング
自己教師あり学習は、自己符号化器、インスタンスレベルの識別、またはクラスタリングなどの方法を使用して、コンピュータビジョンで実装されてきました。最近の研究では、コントラスティブラーニングを使用した方法は、教師あり学習アプローチよりも下流のタスクのための事前トレーニングモデルが優れたパフォーマンスを発揮することを示しています。
視覚特徴の教師なし学習からの主なポイントは、フィルタリングされたデータでトレーニングしている限り、教師付きのラベルは必要ありません。SEERモデルは、大規模なモデルアーキテクチャが未編集、未ラベル化、およびランダムな画像の大量のデータでトレーニングされた場合に正確な表現を学習できるかどうかを探求することを目指しています。
スケールでの視覚特徴の学習
従来のモデルでは、大量のフィルタリングされた画像での弱教師あり学習、教師あり学習、および半教師あり学習による大規模なラベル付きデータセットでモデルを事前トレーニングすることで利益を得てきました。さらに、モデルの分析では、数十億の画像でモデルをゼロからトレーニングする場合に比べて、数十億の画像でモデルを事前トレーニングするとより高い精度が得られることが示されています。
さらに、大規模なスケールでモデルをトレーニングする場合、通常は画像をターゲットの概念と一致させるためのデータフィルタリング手法に依存します。これらのフィルタリング手法は、事前トレーニングされた分類器の予測を使用するか、しばしばImageNetクラスのシスネットを使用します。SEERモデルは異なる方法で動作し、任意のランダムな画像で特徴を学習することを目指しているため、SEERモデルのトレーニングデータは事前に定義された特徴や概念のセットに一致するように編集されていません。
画像認識のためのアーキテクチャのスケーリング
モデルは通常、品質の高い視覚特徴を生み出すために、大規模なアーキテクチャでトレーニングすることで利益を得ます。大規模なデータセットで事前トレーニングする場合、容量の制限があるモデルはしばしば適合不足を引き起こすため、大規模なアーキテクチャをトレーニングすることが重要です。これは、コントラスティブ学習とともに事前トレーニングを行う場合にさらに重要です。その場合、モデルはデータインスタンスの識別方法を学習する必要があり、より良い視覚表現を学習することができます。
ただし、画像認識において、スケーリングアーキテクチャはモデルの深さと幅を変更するだけではありません。より高い容量を持つスケール効率の良いモデルを構築するには、多くの文献が必要です。SEERモデルは、自己教師あり学習を大規模に展開するためのRegNetsモデルファミリーの利点を示しています。
SEER:メソッドとコンポーネントの使用
SEERフレームワークでは、モデルを事前トレーニングして視覚表現を学習するためにさまざまなメソッドとコンポーネントを使用しています。SEERフレームワークで使用される主なメソッドとコンポーネントには、RegNetとSwAVがあります。SEERフレームワークで使用されるメソッドとコンポーネントについて簡単に説明しましょう。
SwAVによる自己教師あり事前トレーニング
SEERフレームワークは、オンラインの自己教師あり学習手法であるSwAVを使用して事前トレーニングされます。SwAVは、アノテーションなしでコンボリューションネットワークフレームワークをトレーニングするために使用されるオンラインクラスタリング手法です。SwAVフレームワークは、同じ画像の異なるビュー間で一貫してクラスタ割り当てを生成する埋め込みをトレーニングすることによって意味的表現を学習します。その後、データ拡張に対して不変なクラスタをマイニングすることによって意味的表現を学習します。
実際には、SwAVフレームワークでは、異なるビューの特徴をその独立したクラスタ割り当てを使用して比較します。これらの割り当てが同じまたは似た特徴を捉えている場合、1つのビューの特徴を使用して他のビューの割り当てを予測することが可能です。
SEERモデルはKクラスタのセットを考慮し、それぞれのクラスタは学習可能なd次元ベクトルvkと関連付けられます。 B枚の画像のバッチでは、各画像iは2つの異なるビューxi1 、xi2に変換されます。ビューはコンボリューションネットワークを使用して特徴化され、2つの特徴セット(f11、…、fB2)と(f12、…、fB2)が生成されます。各特徴セットは、Optimal Transportソルバーを使用してクラスタープロトタイプに独立に割り当てられます。
Optimal Transportソルバーは、特徴がクラスタ全体に均等に分割されるようにし、すべての表現が単一のプロトタイプにマッピングされるトリビアルな解決策を回避するのに役立ちます。その結果の割り当ては、2つのセットの間でスワップされます:ビューxi1のクラスタ割り当てyi1は、ビューxi2の特徴表現fi2を使用して予測する必要があり、逆も同様です。
プロトタイプの重みとコンボリューションネットワークは、すべての例の損失を最小化するためにトレーニングされます。クラスタ予測損失lは、fとクラスタ割り当てのドット積のソフトマックス間のクロスエントロピーです。

RegNetY:スケール効率の高いモデルファミリー
モデルのキャパシティとデータのスケーリングには、メモリだけでなくランタイムにも効率的なアーキテクチャが必要です。RegNetsフレームワークは、特にこの目的に特化して設計されたモデルファミリーです。
RegNetアーキテクチャファミリーは、4つのステージで構成されるコンブネットの設計空間によって定義されます。各ステージには、同一のブロックが一連のブロックとして含まれますが、そのブロックの構造(主に残差ボトルネックブロック)は固定されたままです。
SEERフレームワークは、RegNetYアーキテクチャに焦点を当て、標準のRegNetsアーキテクチャにスクイーズアンドエキサイテーションを追加してパフォーマンスを向上させようとします。さらに、RegNetYモデルには、リソースを適切に消費する一定数のFLOPを持つ良いインスタンスを検索するのに役立つ5つのパラメータがあります。SEERモデルは、そのセルフサプライズドプレトレーニングタスクで直接RegNetYアーキテクチャを実装することで、結果を向上させることを目指しています。
RegNetY 256GFアーキテクチャ:SEERモデルは、RegNetYファミリーの中で主にRegNetY 256GFアーキテクチャに焦点を当て、そのパラメータはRegNetsアーキテクチャのスケーリングルールを使用しています。パラメータは以下のように説明されます。

RegNetY 256GFアーキテクチャは、ステージ幅(528、1056、2904、7392)とステージの深さ(2、7、17、1)を持ち、総パラメータ数は6億9600万を超えます。512のV100 32GB NVIDIA GPUでトレーニングする場合、バッチサイズが8,704の画像について、各イテレーションには約6125msかかります。512のGPUでバッチサイズが8,704の画像を使用して10億枚以上のデータセットでモデルをトレーニングするには、114,890回のイテレーションが必要で、トレーニングには約8日かかります。
スケールでの最適化とトレーニング
SEERモデルは、自己教師法をトレーニングするためにいくつかの調整を提案して、これらの手法を大規模なスケールに適用および適応させることを目指しています。これらの手法には以下があります。
- 学習率スケジュール。
- GPUごとのメモリ消費量の削減。
- トレーニング速度の最適化。
- 大規模なデータでの事前トレーニング。
それでは、それらを簡単に説明しましょう。
学習率スケジュール
SEERモデルでは、2つの学習率スケジュールを使用する可能性を探求しています:コサイン波学習率スケジュールと固定学習率スケジュール。
コサイン波学習率スケジュールは、異なるモデルを公平に比較するために使用されます。ただし、コサイン波学習率スケジュールは大規模なトレーニングに適応できず、トレーニング中に画像を見るタイミングに応じて画像の重みを異なるようにし、スケジューリングのために完全な更新を使用します。
固定学習率スケジュールは、損失が非減少であるまで学習率を一定に保ち、その後学習率を2で割ります。分析によると、固定学習率スケジュールの方が良い結果が得られます。ただし、モデルは10億枚の画像だけでトレーニングされるため、最大のモデルであるRegNet 256GFのトレーニングにはコサイン波学習率を使用します。
GPUごとのメモリ消費量の削減
モデルは、混合精度とグラデーションチェックポイントを利用して、トレーニング期間中に必要なGPUの量を削減することを目指しています。モデルは、NVIDIA Apex LibraryのO1最適化レベルを使用して、畳み込みやGEMMなどの操作を16ビット浮動小数点精度で実行します。また、モデルはPyTorchの勾配チェックポイントの実装も使用し、メモリとのトレードオフを行います。
さらに、モデルは前方パス中に作成された中間アクティベーションを破棄し、逆方向パス中にこれらのアクティベーションを再計算します。
トレーニングのスピード最適化
FP16のサイズがFP32と比較して小さくなることにより、メモリ使用量の最適化にミックスドプレシジョンを使用することには、アクセラレータがFP16のサイズを利用してスループットを増加させるという追加の利点があります。これにより、メモリ帯域幅のボトルネックを改善することでトレーニング期間を短縮するのに役立ちます。
SEERモデルはまた、通常よりも時間がかかるグローバル同期ではなく、プロセスグループを作成するために複数のGPU間でBatchNormレイヤーを同期させます。最後に、SEERモデルで使用されるデータローダーは、PyTorchのデータローダーと比較して、より多くのトレーニングバッチを事前に取得するため、データのスループットが高くなります。
大規模な事前トレーニングデータ
SEERモデルは事前トレーニング中に10億以上の画像を使用し、インターネットとInstagramから直接ランダムな画像をサンプリングするデータローダーを考慮しています。SEERモデルはこれらの画像を野生でオンラインでトレーニングするため、これらの画像には事前処理や重複削除やハッシュタグフィルタリングなどのプロセスを適用しません。
データセットが静的ではないことと、データセット内の画像が毎回3ヶ月ごとに更新されることに注意する価値があります。ただし、データセットの更新はモデルのパフォーマンスに影響しません。
SEERモデルの実装
SEERモデルは、2×224 + 4×96の解像度を持つ各画像に対して6つのクロップを使用して、RegNetY 256GFをSwAVを使用して事前トレーニングします。事前トレーニングフェーズでは、モデルは寸法10444×8192、8192×8192、および8192×256の射影ヘッドを持つ3層のMLPまたは多層パーセプトロンを使用します。
ヘッドではBatchNormレイヤーの代わりに、SEERモデルは温度tを0.1に設定した16,000のプロトタイプを使用します。Sinkhorn正規化パラメータは0.05に設定され、アルゴリズムの10回の反復を実行します。モデルはさらにBatchNormスタッツをGPU間で同期し、同期にはサイズ64の多数のプロセスグループを作成します。
さらに、モデルはLARS(Layer-wise Adaptive Rate Scaling)オプティマイザー、重み減衰率10-5、アクティベーションチェックポイント、およびO1混合精度最適化を使用します。モデルは512のNVIDIA GPU上に分散された8192のランダムな画像のバッチサイズを使用して確率的勾配降下法によってトレーニングされ、1つのGPUあたり16の画像が得られます。
学習率は最初の8000回のトレーニングアップデートに対して線形に0.15から9.6まで増加します。ウォームアップ後、モデルは余弦学習率スケジュールに従い、最終値0.0096まで減衰します。全体として、SEERモデルは122,000回の反復で10億以上の画像をトレーニングします。
SEERフレームワーク:結果
自己教師付き事前トレーニングアプローチによって生成される特徴の品質は、さまざまなベンチマークや下流のタスクで研究および分析されます。モデルはまた、下流のタスクに対して画像とそのラベルへの制限されたアクセスを提供する低ショット設定を考慮しています。
大規模な事前トレーニング済みモデルの微調整
モデルは、ランダムデータで事前トレーニングされたモデルの品質を、ImageNetベンチマークのオブジェクト分類に転送することによって測定します。大規模な事前トレーニング済みモデルの微調整結果は、次のパラメータで決定されます。
実験設定
モデルは、SwAVを使用して10億以上のランダムおよび一般公開のInstagram画像に対してRegNetY- {8,16,32,64,128,256}GFという異なる容量の6つのRegNetアーキテクチャを事前トレーニングします。その後、モデルはImageNet上での画像分類の目的で微調整され、適切なラベルが付いた128万以上の標準的なトレーニング画像と、評価用の5万以上の標準的な検証画像が使用されます。
モデルはSwAVと同じデータ拡張技術を適用し、SGDオプティマイザーまたは確率的勾配降下法を使用して35エポックで微調整されます。バッチサイズは256、学習率は30エポック後に10倍に減少する0.0125、運動量は0.9、重み減衰率は10-4です。モデルは、中央の224×224のクロップを使用して検証データセットのトップ1の精度を報告します。
他の自己教師付き事前学習手法との比較
以下の表では、RegNetY-256GFの最大の事前学習モデルが、自己教師付き学習手法を使用した既存の事前学習モデルと比較されています。
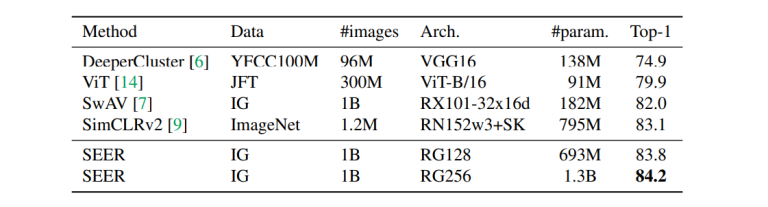
ご覧のように、SEERモデルはImageNetで84.2%のトップ-1正答率を示し、最も優れた既存の事前学習モデルであるSimCLRv2を1%上回ります。
さらに、以下の図では、SEERフレームワークを異なる容量のモデルと比較しています。ご覧のように、モデル容量に関係なく、RegNetフレームワークとSwAVを組み合わせることで、事前学習中に正確な結果が得られます。

SEERモデルは、非整理およびランダムな画像で事前学習されており、SwAV自己教師付き学習手法を使用してRegNetアーキテクチャを持っています。SEERモデルは、SimCLRv2および異なるネットワークアーキテクチャを持つViTモデルと比較されます。最後に、モデルはImageNetデータセットで微調整され、トップ-1正答率が報告されます。
モデル容量の影響
モデル容量は、事前学習のモデルパフォーマンスに大きな影響を与えます。以下の図は、それをスクラッチからトレーニングする場合と比較しています。

事前学習モデルのトップ-1正答率は、スクラッチからトレーニングされるモデルよりも高くなっていることが明確にわかります。また、パラメータ数が増えるにつれてその差も大きくなっています。モデル容量は、事前学習およびスクラッチからトレーニングされるモデルの両方に利益をもたらすことが明らかですが、パラメータ数が多い場合には事前学習モデルにより大きな影響を与えることがわかります。
ImageNetデータセットでモデルをスクラッチからトレーニングする場合、オーバーフィットが発生する可能性があるのは、データセットのサイズが小さいためです。
低ショット学習
低ショット学習とは、ダウンストリームタスクを実行する際に、総データの一部のみを使用するセットアップであるSEERモデルのパフォーマンスを評価することを指します。
実験設定
SEERフレームワークでは、Places205およびImageNetの2つのデータセットを低ショット学習に使用します。さらに、モデルは転移学習中にデータセットへのアクセスが制限されることを前提としています。イメージとそのラベルの両方のアクセスが制限されるという制限アクセス設定は、モデルが利用可能なデータセット全体にアクセスできる自己教師付き学習のデフォルト設定とは異なります。
-
Place205データセットの結果
以下の図は、Place205データセットの異なる部分でモデルを事前学習した場合の影響を示しています。

使用された手法は、同じRegNetY-128 GFアーキテクチャでImageNetデータセットを教師付きで事前学習した結果と比較されます。比較結果からわかるように、Places205データセットでの微調整のために使用可能なトレーニングデータの部分に関係なく、トップ-1正答率は安定して約2.5%向上しています。
教師ありと自己教師付きの事前学習プロセスの間に観察される違いは、トレーニングデータの性質の違いによって説明されます。モデルが野生のランダムな画像から学習することで獲得した特徴は、シーンを分類するのに適している場合があります。さらに、Places205のような不均衡なデータセットでの事前学習は、潜在的な概念の非均一な分布が利点となる可能性があります。
ImageNetの結果
![]()
上記の表は、SEERモデルの手法を自己教師付き事前学習手法および半教師あり手法と比較したものです。これらの手法はすべて、1,200,000枚のImageNetデータセットを事前学習に使用し、ラベルへのアクセスのみを制限しています。一方、SEERモデルの手法では、データセット内の画像の1〜10%のみを使用することができます。
ネットワークは、事前学習中に同じディストリビューションからの画像をより多く見ているため、これらの手法には非常に有利です。しかし、印象的なのは、SEERモデルがImageNetデータセットのわずか1〜10%しか見なくても、上記の表で議論された手法の精度スコアには及ばないものの、トップ1の精度スコアが約80%に達することです。
モデルの容量の影響
以下の図は、モデルの容量が低ショット学習に与える影響について説明しています:ImageNetデータセットの1%、10%、および100%での影響を示しています。

モデルの容量を増やすと、データセット内の画像とラベルへのアクセスが減少し、モデルの精度スコアが向上することが観察されます。
他のベンチマークへの転移
SEERモデルをさらに評価し、そのパフォーマンスを分析するために、事前学習された特徴量を他のダウンストリームタスクに転送します。
画像分類の線形評価

上記の表は、SEERの事前学習されたRegNetY-256GFとRegNetY128-GFの特徴量を、同じアーキテクチャでImageNetデータセット上で教師ありと教師なしの状態で比較しています。特徴量の品質を分析するために、モデルは重みを固定し、トレーニングセットを使用してダウンストリームタスクのための特徴量の上に線形分類器を使用します。このプロセスでは、以下のベンチマークが考慮されます:Open-Images(OpIm)、iNaturalist(iNat)、Places205(Places)、およびPascal VOC(VOC)。
検出とセグメンテーション
以下の図は、検出とセグメンテーションの事前学習された特徴量を比較し、評価します。

SEERフレームワークは、事前学習されたRegNetY-64GFとRegNetY-128GFをビルディングブロックとして使用して、COCOベンチマークでMask-RCNNモデルをトレーニングします。アーキテクチャとダウンストリームタスクの両方において、SEERの自己教師あり事前学習アプローチは、教師あり学習よりも1.5〜2 APポイント優れています。
弱教師あり事前学習との比較
インターネット上で利用可能なほとんどの画像には、メタ説明やaltテキスト、説明、またはジオロケーションがあり、事前学習中にこれらを活用することができます。これまでの研究では、キュレーションされたまたはラベル付けされた一連のハッシュタグの予測が、生成された視覚的な特徴の品質を向上させることが示されています。ただし、このアプローチは画像をフィルタリングする必要があり、テキストメタデータが存在する場合にのみ最適です。
以下の図は、ランダムな画像でトレーニングされたResNetXt101-32dx8dアーキテクチャと、ハッシュタグとメタデータを使用してトレーニングされた同じアーキテクチャのモデルを事前学習した場合のトップ1の精度を比較しています。

SEERフレームワークは事前学習中にメタデータを使用しないにも関わらず、その精度はメタデータを使用するモデルに匹敵することがわかります。
アブレーションスタディ
アブレーションスタディは、モデル全体のパフォーマンスに特定のコンポーネントが与える影響を分析するために行われます。アブレーションスタディは、そのコンポーネントをモデルから完全に削除し、モデルのパフォーマンスに対するそのコンポーネントの影響を理解することにより、開発者にその概要を提供します。
モデルアーキテクチャの影響
モデルのアーキテクチャは、モデルのパフォーマンスに大きな影響を与えます。特に、モデルがスケーリングされた場合や、事前学習データの仕様が変更された場合には、その影響が顕著です。
以下の図は、アーキテクチャの変更が事前学習された特徴量の品質に与える影響を、ImageNetデータセットを線形的に評価することで説明しています。この場合、事前学習された特徴量は直接プローブできます。なぜなら、評価はImageNetデータセットをゼロからトレーニングした場合に高い精度を返すモデルを好まないからです。

ResNeXtとResNetアーキテクチャにおいて、現在の設定ではペンultimate層から得られる特徴がより優れていることが観察されます。一方、RegNetアーキテクチャは他のアーキテクチャよりも優れたパフォーマンスを発揮します。
全体的に、モデルの容量を増やすことは特徴の品質に肯定的な影響を与え、モデルのパフォーマンスには対数的な利益があると結論付けられます。
事前学習データのスケーリング
モデルをより大きなデータセットでトレーニングすることが、モデルが学習する視覚特徴の全体的な品質を向上させる2つの主要な理由があります:ユニークな画像の増加とパラメータの増加です。これらの理由がモデルのパフォーマンスにどのように影響するかを簡単に見てみましょう。
ユニークな画像の数を増やす

上記の図は、同じパラメータ数を持つRegNet8とRegNet16という2つの異なるアーキテクチャを比較しています。SEERフレームワークは、10億枚の画像に対応する更新をモデルに対して1エポック分、または32ユニークな画像に対して32エポック分トレーニングし、半波余弦学習率を使用しています。
モデルがうまく機能するためには、モデルに供給されるユニークな画像の数が理想的にはより多い方が良いことが観察されます。この場合、モデルはImageNetデータセットに存在する画像よりもユニークな画像を供給されると良いパフォーマンスを発揮します。
より多くのパラメータ
以下の図は、RegNet-128GFアーキテクチャを使用して10億枚の画像でトレーニングした場合のモデルのパフォーマンスを示しています。パラメータ数が増加すると、モデルのパフォーマンスが着実に向上することが観察されます。

実世界における自己教師ありコンピュータビジョン
これまで、自己教師あり学習とSEERモデルについて理論的に説明しました。では、実世界のシナリオで自己教師ありコンピュータビジョンがどのように機能するか、なぜSEERが自己教師ありコンピュータビジョンの未来なのかを見てみましょう。
SEERモデルは、自己教師あり学習フレームワークであるSwAVが開発した進歩を利用し、オンラインクラスタリングを使用して並行する視覚的な概念を持つ画像をグループ化またはペアリングし、これらの類似性を活用してパターンをより良く識別することを目指しています。

SwAVアーキテクチャを使用することで、SEERモデルは自己教師あり学習をコンピュータビジョンでより効果的に利用し、トレーニング時間を最大6倍短縮することができます。
さらに、このスケールで大規模なモデルをトレーニングする場合、1兆枚以上の画像を扱うために、ランタイムとメモリの面だけでなく、精度にも優れた効率的なモデルアーキテクチャが必要です。これがRegNetモデルの役割であり、これらのRegNetモデルはトリリオンのパラメータをスケーリングできるConvNetモデルであり、メモリ制約とランタイムの規制に適合するように最適化することができます。
結論:自己教師ありの未来
自己教師あり学習はAIおよびML業界で長い間話題となってきました。なぜなら、これによりAIモデルが特定の目的でなく、インターネット上でランダムに利用可能な大量のデータから直接情報を学習することができるからです。厳選されたラベル付きのデータセットに頼る必要がありません。
自己教師あり学習はAIおよびMLの将来において重要な概念です。なぜなら、これにより開発者が実世界のシナリオに適応し、特定の目的ではなく複数の用途を持つAIモデルを作成できる可能性があるからです。そして、SEERはコンピュータビジョン業界での自己教師あり学習の実装における重要な節目です。
SEERモデルは、コンピュータビジョン業界の変革の第一歩を踏み出し、ラベル付きデータセットへの依存を減らします。SEERモデルは、多様な大量のデータと作業することを開発者に許可するため、データセットの注釈付けの必要性を排除します。特に、画像やメタデータが限られている医療業界などのモデルに取り組む開発者にとって、SEERの実装は特に役立ちます。
さらに、人間の注釈を排除することで、開発者はモデルをより迅速に開発・展開することができ、迅速かつより高い精度で急速に進化する状況に対応することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『RAPとLLM Reasonersに会いましょう:LLMsを活用した高度な推論のための類似概念に基づく2つのフレームワーク』
- 「フューショットラーニングの力を解き放つ」
- 「Keras 3.0 すべてを知るために必要なこと」
- 「MC-JEPAに会おう:動きと内容の特徴の自己教師あり学習のための共同埋め込み予測アーキテクチャ」
- 「新しいHADARベースのイメージングツールにより、暗闇でもクリアに見ることができます」
- 中国のこのAI論文は、HQTrackというビデオ内のあらゆるものを高品質で追跡するためのAIフレームワークを提案しています
- 『Stack OverflowがOverflowをリリース:開発者コミュニティとAIの統合』






