ウィスコンシン大学マディソン校の研究者たちは、「エベントフルトランスフォーマー:最小限の精度損失でコスト効果のあるビデオ認識手法」というタイトルで、イベントフルトランスフォーマーに基づくビデオ認識の費用対効果の高い手法を提案しています
Researchers at the University of Wisconsin-Madison propose a cost-effective method for video recognition based on Eventful Transformer with minimal loss of accuracy.


最近、言語モデリングを目的としたTransformerは、ビジョン関連のタスクのアーキテクチャとしても研究されています。オブジェクトの識別、画像の分類、ビデオの分類などのアプリケーションにおいて最先端のパフォーマンスを発揮し、さまざまな視覚認識の問題において優れた精度を示しています。ビジョンTransformerの主な欠点の1つは、高い処理コストです。ビジョンTransformerは、通常の畳み込みニューラルネットワーク(CNN)に比べて、数百GFlopsの処理が1枚の画像に対して必要となることもあります。ビデオ処理にかかるデータ量の多さは、これらの費用をさらに増加させます。この興味深い技術の潜在能力は、リソースが少ないデバイスや低遅延が必要なデバイスで使用することを妨げる高い計算要件によって制約されています。
ビデオデータと一緒に使用する場合、ビジョンTransformerのコストを削減するために、連続する入力間の時間的冗長性を活用する最初の手法の1つが、ウィスコンシン大学マディソン校の研究者によって提案されました。フレームごとまたはクリップごとにビデオシーケンスに適用されるビジョンTransformerを考えてみてください。このTransformerは、フレームごとのモデル(オブジェクト検出など)や時空間モデルの過渡的なステージ(初期の因子分解モデルなど)のようなものかもしれません。彼らは、時間を超えて複数の異なる入力(フレームまたはクリップ)にTransformerが適用されると考えています。これは、言語処理とは異なり、1つのTransformer入力が完全なシーケンスを表すものです。自然な動画は高い程度の時間的冗長性を持ち、フレーム間の変動が少ない傾向があります。しかし、これにもかかわらず、このような状況でも、Transformerなどの深層ネットワークは各フレームで頻繁に「ゼロから」計算されます。
この方法は効率的ではありません。なぜなら、それによって以前の結論からの潜在的に有用なデータが捨てられてしまうからです。彼らの主な洞察は、以前のタイムステップの中間計算を再利用することで冗長なシーケンスをより良く活用できるということです。知的推論。ビジョンTransformer(および深層ネットワーク全般)の推論コストは、設計によって決まることがよくあります。ただし、実際のアプリケーションでは、利用可能なリソースは時間とともに変化する可能性があります(たとえば、競合するプロセスや電源の変更など)。そのため、計算コストをリアルタイムに変更できるモデルが必要です。本研究では、適応性が主な設計目標の1つであり、計算コストに対してリアルタイムの制御を提供するためにアプローチが作成されています。映画の中で計算予算をどのように変更するかの例については、図1(下部)を参照してください。
- 「LLMはナレッジグラフを取って代わるのか? メタリサーチャーが提案する『ヘッド・トゥ・テイル』:大規模言語モデルの事実知識を測るための新たな基準」
- アリババの研究者は、Qwen-VLシリーズを紹介しますこれは、テキストと画像の両方を認識し理解するために設計された大規模なビジョン・ランゲージ・モデルのセットです
- 研究者たちは、ロボットが手全体を使って複雑な計画を立てることができるようにするAIを開発しました
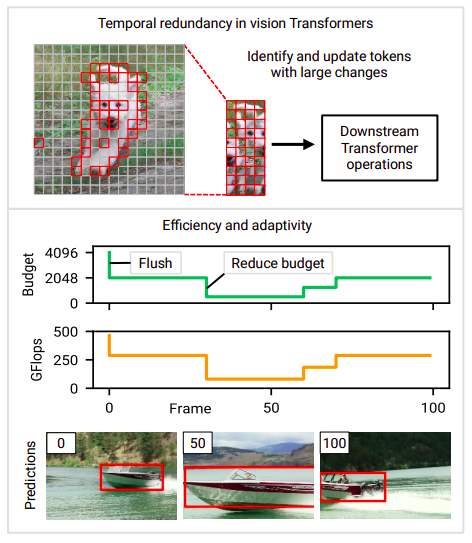
以前の研究では、CNNの時間的冗長性と適応性に関して調査されてきました。しかし、TransformerとCNNの間には重要なアーキテクチャの違いがあるため、これらのアプローチは通常、Transformerのビジョンには互換性がありません。特に、Transformerは複数のCNNベースの手法から逸脱した、新しい基本的な手法である自己注意を導入しています。しかし、このような障害にもかかわらず、ビジョンTransformerには大きな可能性があります。特に、時空間的な冗長性を考慮に入れることで獲得されるCNNのスパース性を実際の高速化に転送することは難しいです。これを行うには、スパース構造に大きな制約を課すか、特別な計算カーネルを使用する必要があります。一方、トークンベクトルの操作に焦点を当てたTransformerの性質により、スパース性をより短い実行時間に転送することはより簡単です。イベントを持つTransformer。
効果的で適応性のある推論を可能にするために、彼らはイベントフルTransformerという新しいタイプのTransformerを提案しています。イベントフルという言葉は、シーンの変化に応じて疎な出力を生成するセンサーであるイベントカメラを指すために作られました。イベントフルTransformerは、時間の経過に伴うトークンレベルの変化を追跡するために、各タイムステップでトークンの表現と自己注意マップを選択的に更新します。ゲーティングモジュールは、更新されるトークンの量をランタイムで制御するためのイベントフルTransformerのブロックです。彼らのアプローチは、さまざまなビデオ処理アプリケーションと共に動作し、再トレーニングなしで既存のモデルに使用することができます。彼らの研究は、最先端のモデルから作成されたイベントフルTransformerが、計算コストを大幅に削減しながら元のモデルの精度をほぼ保持することを示しています。
彼らのソースコードは、イベントフルトランスフォーマーを作成するためのPyTorchモジュールが公開されています。Wisionlabのプロジェクトページは、wisionlab.com/project/eventful-transformersにあります。CPUとGPUでは、壁時計の速度向上が示されています。彼らのアプローチは、標準的なPyTorchオペレータに基づいているため、技術的な観点からは最適とは言えないかもしれません。彼らは、オーバーヘッドを減らすための作業(ゲーティングロジックのための融合CUDAカーネルの構築など)を行うことで、速度向上比率がさらに高まる可能性があると確信しています。さらに、彼らのアプローチには、ある程度避けられないメモリオーバーヘッドが生じます。当然のことながら、一部のテンソルをメモリ上に保持することは、以前の時間ステップからの計算の再利用に必要です。
論文をチェックしてください。この研究に関する全てのクレジットは、このプロジェクトの研究者に帰属します。また、最新のAI研究ニュースや素敵なAIプロジェクトなどを共有している2.9万人以上のML SubReddit、4万人以上のFacebookコミュニティ、Discordチャンネル、およびメールニュースレターにも参加するのを忘れないでください。
私たちの活動が気に入ったなら、ニュースレターも気に入るはずです。
この投稿は、「ミニマルな精度損失を伴うコスト効果的なビデオ認識手法であるイベントフルトランスフォーマーについて、ウィスコンシン大学マディソン校の研究者が提案しました」という記事です。
(翻訳元:MarkTechPost)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『広範な展望:NVIDIAの基調講演がAIの更なる進歩の道を指し示す』
- 「この新しいAI研究は、事前学習されたタンパク質言語モデルを幾何学的深層学習ネットワークに統合することで、タンパク質構造解析を進化させます」
- スタンフォードの研究者たちは、DSPyを紹介します:言語モデル(LM)と検索モデル(RM)を用いた高度なタスクの解決のための人工知能(AI)フレームワーク
- 「ATLAS研究者は、教師なし機械学習を通じて異常検出を行い、新しい現象を探求しています」
- 「大規模な言語モデルは、多肢選択問題の選択の順序に敏感なのか」という新しいAI研究に答える
- CMU(カーネギーメロン大学)と清華大学の研究者が提案した「Prompt2Model:自然言語の指示から展開可能なAIモデルを生成する汎用メソッド」
- ETHチューリッヒの研究者が、大規模な言語モデル(LLM)のプロンプティング能力を向上させるマシンラーニングフレームワークであるGoT(Graph of Thoughts)を紹介しました





