「現代の自然言語処理:詳細な概要パート3:BERT」
Modern Natural Language Processing Detailed Overview Part 3 BERT
以前のトランスフォーマーやGPTについての記事では、NLPのタイムラインと開発のシステム的な分析を行いました。シーケンス・モデリングからトランスフォーマーへとドメインが移り、さらに汎用学習アプローチへと進んでいく様子を見てきました。この記事では、Googleが公開したもう1つの最も影響力のある作品であるBERT(Bi-directional Encoder Representation from Transformers)について話します。
BERTは、NLPの領域においていくつかの重要な改善をもたらしました。BERTの著者たちは非常に高貴なアーキテクチャを提案したわけではありませんが、OpenAIのGPTの作業と同様に、トランスフォーマー、事前学習、転移学習など、NLPの現代の概念を巧みに利用して優れたパフォーマンスを実現しました。
前提条件
BERTを理解するためには、モデルを作成するために著者が他のいくつかの先行作品からいくつかの概念と改善を使用または参照していることを理解する必要があります。これらの概念を理解するためには、Transformers、Semi-supervised Sequence Learning、ULMFit、OpenAI GPT、ELMoについて非常によく理解する必要があります。ELMo以外の必要なトピックについてはすでに議論してきましたので、これらの記事を一読し、概念が理解されていない場合は戻ってきて旅を続けることをお勧めします。ELMoに関しては心配しないでください、この概念を理解することから始めましょう。
- 「GPT4の32Kを忘れてください:LongNetは10億トークンのコンテキストを持っています」
- コーディウムのVarun MohanとJeff Wangによるソフトウェア開発におけるAIの力の解放について
- 「責任あるAIの推進のための新しいパートナーシップ」
深層コンテキスト化された単語表現
この論文は、2018年にAllen-AIによって公開されました。それ以降、Bag of Words、Word2Vec、Gloveなどの事前学習された単語の埋め込みはすでに人気を博しており、トレーニングモデルのパフォーマンスを大幅に向上させることが証明されています。しかし、成功を収めたにもかかわらず、これらのモデルから得られる単語の埋め込みは、一般的なアプローチに基づいており、文脈に依存しないものです。言い換えれば、文中で単語は異なる文脈で使用されることがあり、文によって意味が変わりますが、表現や埋め込みは同じままです。例えば、次の2つの文を考えてみてください。
ビジネスの取引はうまくいった。
問題に対処してください。
「取引」という単語は両方の文で使用されていますが、意味は使用によって異なりますので、同じ埋め込みで表現してはいけません。これがELMoの役割です。
ELMoの著者は、単語の埋め込みが2つのことを表現すべきだと提案しています:
(i) セマンティックな意味での単語の使用の複雑な特徴と
(ii) 単語がさまざまな言語的文脈で使用される方法。
ELMoは、これらの両方の問題に対処し、単語の埋め込みまたは表現を、入力文全体の関数として生成します。著者は、提案された方法が他のモデルにも簡単に適応できると主張しており、それによって改善が見られると述べています。
アーキテクチャ:著者は、このコンセプトをデモするために、2層の双方向LSTMを使用しました。モデルの双方向性、つまり前後の単語の両方を発見する能力が、基本的な単方向LSTMに比べて文のコンテキストを理解するための上位に立つことが観察されました。これにより、埋め込みの品質が向上します。
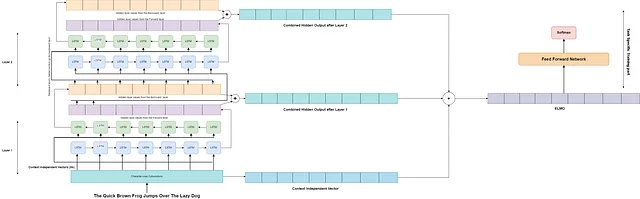
アプローチ:著者は、まず文を文字畳み込み層に通し、コンテキストに依存しないベクトル(Xk)を作成します。各ステップkのコンテキストベクトル(Xk)は、2つのLSTM層を通過します。最初のLSTM層(Layer 1)の後、前向きのシーケンスと後ろ向きのシーケンスのために2つの中間隠れベクトル(Hk-forward、Hk-backward)が生成されます。2つの中間ベクトルは合計され、両側から接近する単語の周囲の知識を表す最終的な中間ベクトル(Hk-final-layer-1)が作成されます。次に、隠れ状態ベクトルは、もう1つのLSTMモデルの第2層(Layer 2)を再度通過し、各ステップまたは単語kに対して別の最終的な中間ベクトル(Hk-final-layer-2)が作成されます。第2の中間ベクトルは、最初のLSTM層と比較して、コンテキストの情報の範囲がより広いです。
最後に、(Hk-final-layer-1)、(Hk-final-layer-2)、および(Xk)が追加され、最終的なELMo埋め込みが作成されます。このELMo埋め込みはタスク固有のアプリケーションに使用されます。著者は、LSTMモデルはより多くの層を持つことができ、特定のタスクのために任意のモデルに簡単に追加できることを確立しています。このようなアプローチは特徴ベースアプローチと呼ばれ、OpenAIなどのアプローチと比較してファインチューニングベースアプローチとなります。
埋め込みベクトルの方程式は次のとおりです:

論文リンク: https://arxiv.org/pdf/1802.05365.pdf
重要な結論: 双方向LSTMモデルは文脈に基づいた埋め込みを生成するために使用できます。
それでは、最後にBERTについて説明します。

BERT: ディープバイダイレクショナルトランスフォーマーの言語理解のための事前学習
BERTは、2019年にGoogleのJacob Devlinと彼の同僚によって導入されました。BERTアーキテクチャと動作の詳細な議論に入る前に、いくつかのことを明確にしておきましょう。NLPの世界では、通常、2つのタイプのモデルまたはタスクがあります。つまり、自己回帰モデルと自己符号化モデルです。
自己回帰モデルは、文または開始単語トークンを入力すると、入力に関連する単語を生成するモデルです。例えば、GPTがその一例です。テキスト生成、翻訳、要約などのタスクに最適です。
もう1つのタイプのモデルは自己符号化モデルであり、タスクには文全体の文脈を理解する必要があります。これにより、分類、質問応答、含意、固有表現認識などのタスクをより良く達成できます。現在のGoogle検索では、ウェブページで検索クエリに一致する行が強調表示されることがあります。
ただし、自己回帰モデルは符号化タスクに使用できないわけではありませんし、その逆も同様です。ただし、モデルはそれぞれのドメインにおいて最も適しています。
BERTは自己符号化モデルとして設計されています。そのため、GPTなどのモデルがトランスフォーマーのデコーダー部分を使用するのに対し、BERTモデルはトランスフォーマーのエンコーダー部分のみで構成されています。その理由は、なぜですか?
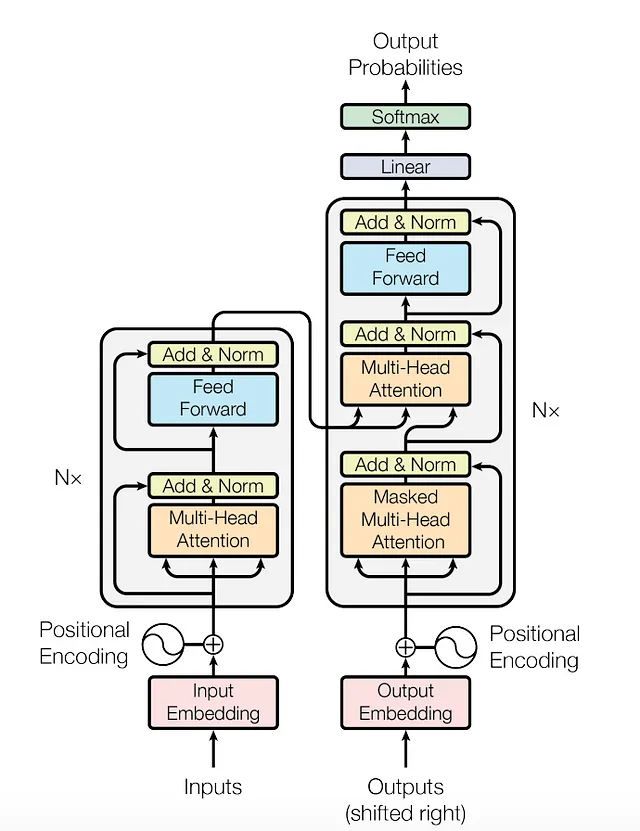
アーキテクチャを見ると、デコーダーは出力を受け取り、または最初のステップでは開始トークンを取り、自己注意を適用し、次の単語の確率を生成します。つまり、デコーダーは前のトークンまたは単語のみを見るか、前のコンテキストのみを知っているため、単語を生成するために最適です。一方、エンコーダーは文全体を見るため、全文脈を持っており、より良い推論を行うことができます。これは自己符号化タスクに適しています。
特徴ベースの埋め込みをサポートするためのELMoの組み込み: BERTの著者は、特定のタスクの場合、左から右への学習アプローチのみでは非常に高い価格を払う必要があると主張しました。なぜなら、単語の後の文脈の知識が失われるからです。BERTは双方向学習を導入し、自己注意を使用して単語を左から右へと学習し、また右から左へとも学習します。著者はまた、これまでに考案された2つの学習アプローチに焦点を当てました。ELMoのような特徴ベースの学習アプローチと、OpenAIのGPTのようなファインチューニングベースの学習アプローチです。BERTは両方のアプローチの長所を組み合わせました。すでに学んだように、Bi-LSTMベースのELMoはモデルに簡単に統合できます。したがって、エンコーダーを活用して一度に全文を受け取るために、BERTはELMoを追加し、単語の高品質な文脈依存埋め込みを生成しました。
事前学習とGPT: 著者はまた、事前学習がモデルの性能に大きく寄与し、非常に必要であることに気付きました。そのため、提案された手法が提供するものを完全に実現するために、GPTの事前学習と微調整技術を使用することにしました。問題は、GPTのトレーニングが左から右に予測するモデルにのみ適しているが、BERTは双方向のデータを持っているということでした。もう1つの問題は、通常の言語モデリングタスクを事前学習に使用すると、モデルが学習を迂回し、右から左へのモデルから左から右へのデータが漏れる可能性があることです。これらの問題を解消するために、著者は主要な事前学習タスクとしてMLMまたはマスクされた言語モデリングタスクを導入しました。これは、テキスト内の単語をランダムにマスクし、モデルがマスクされた単語を予測するというものです。
アーキテクチャとトレーニング:
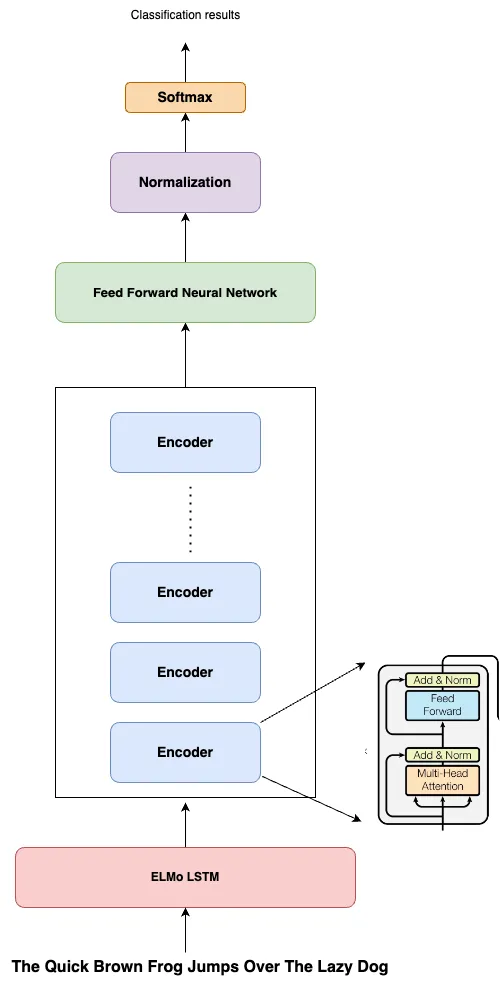
BERTは、Vaswaniらによって提案されたトランスフォーマーのエンコーダベースのアーキテクチャをほとんど変更せずに使用しています。BERTにはBERT-BaseとBERT-Largeの2つのモデルがあります。BERT-Baseは、12のエンコーダレイヤ、サイズ768の隠れ層ベクトル、および各ブロックに12個のセルフアテンションヘッドを含んでおり、約1億1000万のパラメータがあります。一方、BERT-Largeは、24のエンコーダレイヤがあり、各レイヤには16個のアテンションヘッドがあり、1024サイズのベクトルを扱うため、合計で3億4000万のパラメータがあります。
BERTは2ステップのアプローチでトレーニングされます:事前学習の後に微調整が行われます。BERTの場合、事前学習は2つのタスクを使用して行われます:
- マスクされた言語モデリング: この場合、テキスト内の単語のうち15%がランダムにマスクされ、モデルは文脈を使用して単語を予測する必要があります。
- 次の文予測: BERTは質問応答や含意などのタスクに使用することを目的としているため、BERTは長いシーケンスの文脈を分析するために学習することが重要です。そのため、この場合、モデルには文が渡され、次の文を予測するように指示されます。トレーニングのために、著者は、次の文が実際の次の文である場合のケースの50%(IsNextSequence)と、そうでない場合の50%(IsNotNextSequence)を考慮しました。これらの2つのケースの間の確率を提供するために、モデルの上部にSoftMax層が追加されます。
入力が単一の文の場合、[CLS]トークンが文の前に追加されます。これは著者が説明するように、分類タスクを示します。文の類似性や質問応答などのタスクには、文を区切るために[SEP]トークンが中間に配置され、その後に文の所属する側の文脈埋め込みベクトルが配置されます。事前学習コーパスには、BooksCorpus(8億ワード)と英語のWikipedia(25億ワード)が使用されます。Wikipediaでは、リスト、テーブル、ヘッダーは無視し、テキストパッセージのみを抽出します。
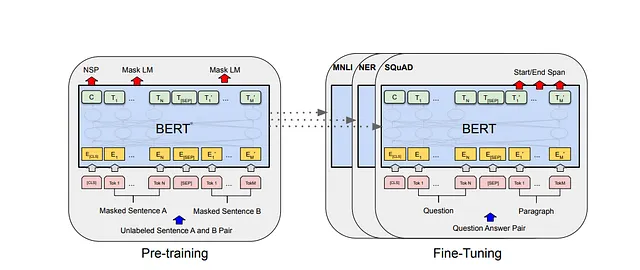
特定のターゲットタスクにBERTを微調整することは非常に簡単です。これは、他の微調整ベースの学習アプローチの場合と同じです。質問応答や類似性などのタスクの場合、文はセパレータを使用して連結されます。文のトークン埋め込みには、セグメンテーション埋め込みが追加され、単語がどの文に所属するかを決定するための位置埋め込みが追加されます。これは、元のトランスフォーマーペーパーで示されている方法です。
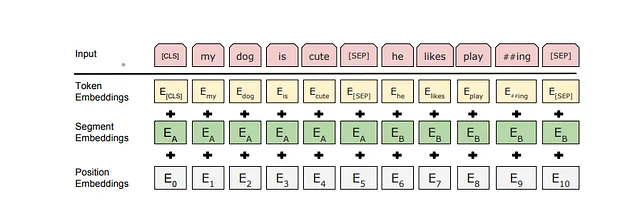
上記の画像は、学習のための最終的なトークン埋め込みの作成を示しています。
論文リンク:https://arxiv.org/pdf/1810.04805.pdf
これがBERTモデルの動作方法についてのすべてです。次に、BERTに基づいて行われた2つの作業について簡単に見ていきます。これらの作業は、広く使用され、成功しています。
RoBERTa:堅牢に最適化されたBERT事前学習アプローチ
メタAIリサーチのYinhan Liu率いるチームが2019年に発表したこの研究では、堅牢に最適化されたトレーニングアプローチを使用してBERTの性能を向上させることが試みられました。彼らはBERT-Largeを使用して仮定をテストしました。
著者は以下の変更を行いました:
- トレーニング中のBERTは、単語の埋め込みにセグメンテーションエンコーディングを追加して、単語がどの文章に属しているかを理解するためのものでした。RoBERTaはこのエンコーディングを削除し、代わりに文章を分けるためのトークン化セパレータ文字を追加しました。
- BERTは元々16GBのデータでトレーニングされましたが、RoBERTaは(1) BERT(16GB)のデータセット、(2) CC-NEWS(CommonCrawl Newsデータベースの英語部分から収集した76GB)、(3) Redditで3つ以上のアップボートを受けたURLから抽出したWebコンテンツであるオープンソースのWebTextの再作成であるOPENWEBTEXT(38GB)、(4) Winogradスキーマのストーリー風のスタイルに一致するようにフィルタリングされたCommonCrawlデータのサブセットであるSTORIES(31GB)という、独自の新しいデータセットを導入しました。これにより、合計で160GBのサイズになりました。著者は、より大きなデータセットがモデルによりコンパクトかつ包括的な事前学習の重みを得るのに役立つと主張しています。
- BERTはマスク言語モデリング(MLM)の技術を使用していますが、マスキングは前処理時に行われるため、基本的にはマスキングのパターンがあり、学習モデルが検出できてしまい、一般化性能が低下します。その代わり、RoBERTaではランタイムで動的なマスキングが導入されました。したがって、入力シーケンスは40エポックにわたって10つの異なるマスキングパターンでトレーニングされます。つまり、各マスキングパターンが4回現れるため、変動が生じ、モデルがマスキングパターンを学習しないようになります。
- RoBERTaの著者は、BERTの事前トレーニングにおける次の文予測目標が、モデルの長距離依存性の学習能力に影響を及ぼし、ダウンストリームのタスクの性能をわずかに低下させることを発見しました。そのため、その事前トレーニングのターゲットは削除されました。
- 以前の研究から、学習率とミニバッチサイズを適切に増やすことで、速度と性能の最適化が向上することが確立されていました。元々、BERTは256シーケンスのバッチで100万ステップトレーニングされました。メモリ要件の量を一定に保ちながら、RoBERTaの著者は、2Kシーケンスバッチで125kステップ、または8Kバッチで31kステップのいずれかでモデルをトレーニングできることを発見しました。いくつかの削除実験の結果、著者は8Kバッチサイズを採用することにしました。
- RoBERTaは入力表現にも変更を加えました。BERTは元々30K語彙の文字レベルのBPE(バイトペアエンコーディング)を使用していましたが、RoBERTaでは50Kのバイトレベルの単語ユニットの語彙を使用しました。
RoBERTaがBERTの性能を改善するために後の研究で広く使用されている改善点をすべてリストアップしました。
論文リンク:https://arxiv.org/pdf/1907.11692.pdf
次に、BERTの最後であり、これまで最も使用されている変種であるDistilBERTを見ていきます。
DistilBERT:BERTの蒸留版 – より小さく、より速く、より安価で、より軽量な
この研究は、2020年にhugging faceによって発表され、BERTアーキテクチャの縮小とモデルのトレーニングにかかる時間を削減することを目的としています。著者は、トレーニングデータとモデルのサイズが各作業ごとに指数関数的に増加していることを観察しました。これは、最先端のパフォーマンスのための必要条件であり、メモリ制約下でこのようなモデルをトレーニングおよび使用することが非常に困難になっていました。この問題を解決するために、DistilBERTが導入されました。知識蒸留トレーニングの方法を用いて、BERTモデルのサイズを40%、トレーニング時間を60%削減し、性能の97%を保持すると主張しています。
知識蒸留は、2つの異なるモデル、教師モデルと生徒モデルが使用される方法です。
知識蒸留[Bucila et al., 2006, Hinton et al., 2015]は、コンパクトなモデル(生徒)が、より大きなモデル(教師)またはモデルのアンサンブルの振る舞いを再現するように訓練される圧縮技術です。
したがって、DistilBERTは生徒モデルとなり、BERTは教師となります。我々は、教師モデルが監視学習の場合、よく訓練されたモデルがインスタンスがクラスに属するかどうかを非常に高い確率で予測し、そうでない場合は非常に低い値で予測することを知っています。値があまりにも高くも低くもない場合は、生徒モデルが最適化するために使用され、簡単な場合は既に除外されているため、蒸留されたサンプルから学習します。
DistilBERTモデルはBERTと非常に似ていますが、エンコーダレイヤーの数が2で割られています。つまり、DistilBERTは6つのエンコーダレイヤーを持っています。学生モデルは、アーキテクチャが非常に似ているため、BERTの事前学習済みの重みのみで初期化されます。BERTの各2層について、著者はDistilBERTの各層の重みを1つの層の重みとして選択しました。
DistilBERTは、元のBERTモデルと同じコーパスでトレーニングされます:英語のウィキペディアとトロントブックコーパスの連結です。損失関数は、Distill Loss(教師と学生によって生成された隠れたベクトル間の距離を減らすことを試みるコサイン埋め込み損失関数)と、実際のマスクされた言語モデリング損失(元のBERT論文で使用されたもの)の合計です。
論文のリンク:https://arxiv.org/pdf/1910.01108.pdf
結論
この記事では、BERTとその改良について学ぼうとしました。このシリーズの後半では、この領域でのさらなる進展を見ることができます。
それまで、楽しい読書を!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






