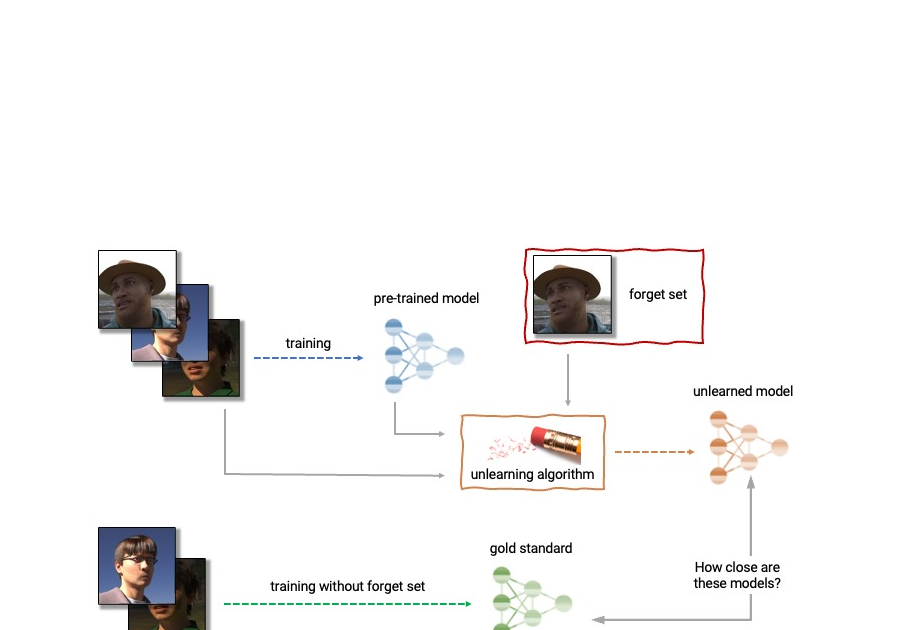
「トランスフォーマベースのLLMがパラメータから知識を抽出する方法」
Method for extracting knowledge from parameters using Transformer-based LLM


近年、トランスフォーマーベースの大規模言語モデル(LLM)が、事実の知識を捉えて保存する能力を持つため非常に人気があります。しかし、これらのモデルが推論中にどのように事実の関連性を抽出するのかは、比較的に未解明のままです。Google DeepMind、テルアビブ大学、Google Researchの研究者による最近の研究は、トランスフォーマーベースのLLMが事実の関連性をどのように保存し抽出するのか、内部のメカニズムを調査することを目的としました。
この研究では、モデルが正しい属性を予測する方法と、内部表現がレイヤーを通じてどのように進化して出力を生成するかを調べるために、情報フローの手法を提案しました。具体的には、研究者はデコーダのみを使用したLLMに焦点を当て、関係と主語の位置に関連する重要な計算ポイントを特定しました。これは、特定のレイヤーで最後の位置が他の位置にアテンションを与えないようにする「ノックアウト」戦略を使用し、推論中の影響を観察することで達成されました。
さらに、属性の抽出が行われる場所を特定するために、研究者はこれらの重要なポイントで情報が伝播する様子と、それに続く表現構築プロセスを分析しました。これは、語彙とモデルのマルチヘッドセルフアテンション(MHSA)およびマルチレイヤーパーセプトロン(MLP)のサブレイヤーとプロジェクションに対する追加の介入を通じて達成されました。
- 「TR0Nに会ってください:事前学習済み生成モデルに任意のコンディショニングを追加するためのシンプルで効率的な方法」
- 「合成キャプションはマルチモーダルトレーニングに役立つのか?このAI論文は、合成キャプションがマルチモーダルトレーニングにおけるキャプションの品質向上に効果的であることを示しています」
- 「もしも、視覚のみのモデルを、わずかな未ラベル化画像を使って線形層のみを訓練することで、ビジョン言語モデル(VLM)に変換できたらどうでしょうか? テキストから概念へ(そしてその逆)のクロスモデルアラインメントによる、Text-to-Conceptの紹介」
研究者は、主語の豊か化プロセスと属性の抽出操作に基づく属性の抽出の内部メカニズムを特定しました。具体的には、モデルの初期のレイヤーで主語に関する情報が最後の主語トークンに豊かになり、関係は最後のトークンに渡されます。最後のトークンは関係を使用して、主語表現から対応する属性をアテンションヘッドパラメータを介して抽出します。
この研究の結果は、LLM内部で事実の関連性がどのように保存され抽出されるかについての洞察を提供しています。研究者は、これらの結果が知識の特定やモデルの編集の新たな研究方向を開く可能性があると考えています。例えば、この研究の手法は、LLMがバイアスのある情報を獲得し保存する内部メカニズムを特定し、そのようなバイアスを軽減する方法を開発するために使用することができます。
全体的に、この研究は、トランスフォーマーベースのLLMが事実の関連性をどのように保存し抽出するか、内部のメカニズムを調査することの重要性を強調しています。これらのメカニズムを理解することで、研究者はモデルの性能を向上させ、バイアスを減らすためのより効果的な方法を開発することができます。さらに、この研究の手法は、感情分析や言語翻訳などの自然言語処理の他の領域にも適用することができ、これらのモデルが内部でどのように動作するかをよりよく理解することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「LogAIとお会いしましょう:ログ分析と知能のために設計されたオープンソースライブラリ」
- 「最も適応能力の高い生存者 コンパクトな生成型AIモデルは、コスト効率の高い大規模AIの未来です」
- 「17/7から23/7までのトップコンピュータビジョン論文」
- 「大規模言語モデルのための任意のPDFおよび画像からテキストを抽出する方法」
- LangChain 101 パート1. シンプルなQ&Aアプリの構築
- 「Brain2Musicに会ってください:機能的磁気共鳴画像法(fMRI)を用いた脳活動から音楽を再構築するためのAI手法」
- 「拡散を支配するための1つの拡散:マルチモーダル画像合成のための事前学習済み拡散モデルの調節」