LlamaIndex インデックスと検索のための究極のLLMフレームワーク
LlamaIndex LLM framework for ultimate indexing and searching.
LlamaIndexの概要
LlamaIndexは、以前はGPT Indexとして知られていましたが、LLM(Large Language Models)を使用したアプリケーションの構築を支援するためのデータフレームワークで、データのインジェスト、構造化、検索、およびさまざまなアプリケーションフレームワークとの統合を容易にする必須ツールを提供します。LlamaIndexが提供する機能は多岐にわたり、非常に有用です:
✅ データコネクタ(Llama Hub)を使用して、さまざまなデータソースとデータ形式からのインジェストを実現します。 ✅ 挿入、削除、更新、およびドキュメントインデックスの更新など、ドキュメント操作を有効にする。 ✅ 異種データと複数のドキュメントに対する総合サポート。 ✅ 異なるクエリエンジンの間での選択に「Router」を使用します。 ✅ 出力品質を向上させるための仮想ドキュメント埋め込みを可能にします。 ✅ 多様なベクトルストア、ChatGPTプラグイン、トレーシングツール、LangChainなど、さまざまな統合を提供します。 ✅ 最新のOpenAI関数呼び出しAPIをサポートします。
LlamaIndexが提供する機能はこれらの例にすぎません。このブログ投稿では、私がLlamaIndexを使用する上で特に有用だと考える機能のいくつかを探求してみたいと思います。
データコネクタ(LlamaHub)
LLMアプリケーションを開発する場合、外部データソースとの効果的な対話を実現することが重要です。ここで重要なのは、データのインジェスト方法です。Llama Hubは、LlamaIndexまたはLangChainが一貫した方法でデータをインジェストできるよう、100以上のデータソースと形式を幅広く提供しています。
デフォルトでは、pip install llama-hubを使用してスタンドアロンパッケージとして使用できます。また、download_loaderメソッドを使用して、LlamaIndexで使用するために個別にデータローダーをダウンロードすることもできます。
以下に、llama-hubパッケージからWikipediaデータローダーをロードする例を示します。一貫した構文が非常に素晴らしいです。
from llama_hub.wikipedia.base import WikipediaReaderloader = WikipediaReader()documents = loader.load_data(pages=['Berlin', 'Rome', 'Tokyo', 'Canberra', 'Santiago'])出力を確認してください:

Llama Hubは、マルチモーダルドキュメントもサポートしています。たとえば、ImageReaderローダーは、pytesseractまたはDonutトランスフォーマーモデルを使用して画像からテキストを抽出します。
基本的なクエリ機能
インデックス、リトリーバ、およびクエリエンジン
インデックス、リトリーバ、およびクエリエンジンは、データまたはドキュメントに対して質問するための3つの基本コンポーネントです:
- インデックスは、外部ドキュメントからユーザークエリに関連する情報を迅速に取得できるデータ構造です。インデックスは、ドキュメントをテキストチャンクに解析し、「ノード」と呼ばれるオブジェクトに変換し、そのチャンクからインデックスを構築することで機能します。
- リトリーバは、ユーザークエリに対して関連する情報を取得し、取得するために使用されます。
- クエリエンジンは、インデックスとリトリーバの上に構築され、データに関する質問を一般的なインターフェイスで提供します。
以下は、ドキュメントに関する質問をする最も簡単な方法です。まず、ドキュメントからインデックスを作成し、次にクエリエンジンを使用して質問のインターフェイスを作成します。
from llama_index import VectorStoreIndexindex = VectorStoreIndex.from_documents(docs)query_engine = index.as_query_engine()response = query_engine.query("Who is Paul Graham.")さまざまなタイプのインデックス、リトリーバメソッド、およびクエリエンジンがあり、LlamaIndexドキュメントで詳しく説明されています。この記事の残りについては、次に有用だと考えるクールな機能について説明していきます。
ドキュメントの更新の処理
ドキュメントに対するインデックスを作成した後、定期的にドキュメントを更新する必要がある場合があります。このプロセスは、ドキュメント全体の埋め込みを再作成する必要があるため、コストがかかる場合があります。LlamaIndexインデックス構造は、効率的な挿入、削除、更新、およびリフレッシュ操作を可能にすることで、解決策を提供します。たとえば、新しいドキュメントを追加ノード(テキストチャンク)として挿入することができます。これにより、以前のドキュメントからノードを再作成する必要がありません。
# ソース:https://gpt-index.readthedocs.io/en/latest/how_to/index/document_management.htmlfrom llama_index import ListIndex, Documentindex = ListIndex([])text_chunks = ['text_chunk_1', 'text_chunk_2', 'text_chunk_3']doc_chunks = []for i, text in enumerate(text_chunks): doc = Document(text, doc_id=f"doc_id_{i}") doc_chunks.append(doc)# 挿入for doc_chunk in doc_chunks: index.insert(doc_chunk)複数のドキュメントをクエリ
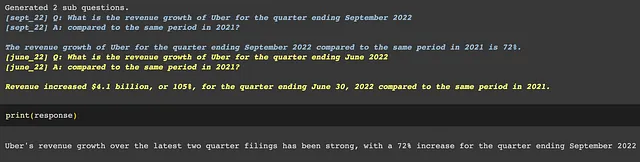
LlamaIndexを使用すると、複数のドキュメントを簡単にクエリできます。この機能は、`SubQuestionQueryEngine`クラスを介して有効になります。クエリを与えると、クエリエンジンはサブドキュメントに対するサブクエリから構成される「クエリプラン」を生成し、それらを合成して最終的な回答を提供します。
# ソース:https://gpt-index.readthedocs.io/en/latest/examples/usecases/10q_sub_question.html# データのロードmarch_2022 = SimpleDirectoryReader(input_files=["../data/10q/uber_10q_march_2022.pdf"]).load_data()june_2022 = SimpleDirectoryReader(input_files=["../data/10q/uber_10q_june_2022.pdf"]).load_data()sept_2022 = SimpleDirectoryReader(input_files=["../data/10q/uber_10q_sept_2022.pdf"]).load_data()# インデックスの構築march_index = VectorStoreIndex.from_documents(march_2022)june_index = VectorStoreIndex.from_documents(june_2022)sept_index = VectorStoreIndex.from_documents(sept_2022)# クエリエンジンの構築march_engine = march_index.as_query_engine(similarity_top_k=3)june_engine = june_index.as_query_engine(similarity_top_k=3)sept_engine = sept_index.as_query_engine(similarity_top_k=3)query_engine_tools = [ QueryEngineTool( query_engine=sept_engine, metadata=ToolMetadata(name='sept_22', description='Provides information about Uber quarterly financials ending September 2022') ), QueryEngineTool( query_engine=june_engine, metadata=ToolMetadata(name='june_22', description='Provides information about Uber quarterly financials ending June 2022') ), QueryEngineTool( query_engine=march_engine, metadata=ToolMetadata(name='march_22', description='Provides information about Uber quarterly financials ending March 2022') ),]# クエリの実行s_engine = SubQuestionQueryEngine.from_defaults(query_engine_tools=query_engine_tools)response = s_engine.query('Analyze Uber revenue growth over the latest two quarter filings')以下のように、LlamaIndexは複雑なクエリを2つのサブクエリに分解し、複数のドキュメントから情報を比較して最終的な回答を得ることができました。
異なるクエリエンジンを選択するために「ルーター」を使用する
NotionとSlackから情報を取得するためのボットを構築していると想像してください。言語モデルは、どのツールを使用して情報を検索するかをどのように知るのでしょうか? LlamaIndexは、異なる場所にあるものであっても、あなたのために物事を見つけることができる賢いヘルパーのようなものです。具体的には、LlamaIndexの「ルーター」は、異なるクエリエンジンを「選択」することができる、非常にシンプルな抽象化です。
この例では、NotionとSlackの2つのドキュメントインデックスがあり、それぞれのために2つのクエリエンジンを作成します。その後、すべてのツールをまとめて、個々のツールに与えた説明に基づいてどのツールを使用するかを選択するスーパーツールであるRouterQueryEngineを作成します。これにより、Notionについての質問をする場合、ルーターは自動的にNotionドキュメントから情報を検索します。
# ソース:https://gpt-index.readthedocs.io/en/latest/use_cases/queries.html#routing-over-heterogeneous-datafrom llama_index import TreeIndex, VectorStoreIndexfrom llama_index.tools import QueryEngineTool# サブインデックスを定義するindex1 = VectorStoreIndex.from_documents(notion_docs)index2 = VectorStoreIndex.from_documents(slack_docs)# クエリエンジンとツールを定義するtool1 = QueryEngineTool.from_defaults(query_engine=index1.as_query_engine(),description="Use this query engine to do…",)tool2 = QueryEngineTool.from_defaults(query_engine=index2.as_query_engine(),description="Use this query engine for something else…",)from llama_index.query_engine import RouterQueryEnginequery_engine = RouterQueryEngine.from_defaults(query_engine_tools=[tool1, tool2])response = query_engine.query("In Notion, give me a summary of the product roadmap.")これには多くのエキサイティングなユースケースがあります。ここでは、ルーターを使用してSQLとベクトルDBの間を選択する完全な例があります:https://gpt-index.readthedocs.io/en/latest/examples/query_engine/SQLRouterQueryEngine.html 。
仮想ドキュメント埋め込み(HyDE)
通常、外部ドキュメントに関する質問をする場合、通常の手順は、質問とドキュメントの両方に対してテキスト埋め込みを使用してベクトル表現を作成します。その後、意味的検索を使用して、質問に最も関連性があるテキストチャンクを見つけます。ただし、質問の答えは質問自体と大きく異なる場合があります。仮想回答をまず生成してから、仮想回答に最も関連性があるテキストチャンクを見つけることができたらどうでしょうか?これが仮想ドキュメント埋め込み(HyDE)が登場し、出力の品質を向上させる可能性がある方法であります。
# ソース:https://gpt-index.readthedocs.io/en/latest/examples/query_transformations/HyDEQueryTransformDemo.html# ドキュメントの読み込みdocuments = SimpleDirectoryReader('llama_index/examples/paul_graham_essay/data').load_data()index = VectorStoreIndex.from_documents(documents)query_str = "what did paul graham do after going to RISD"# 今、HyDEQueryTransformを使用して仮想ドキュメントを生成し、埋め込みの検索に使用します。hyde = HyDEQueryTransform(include_original=True)hyde_query_engine = TransformQueryEngine(query_engine, hyde)response = hyde_query_engine.query(query_str)display(Markdown(f"<b>{response}</b>"))# この例では、HyDEは出力品質を大幅に向上させ、正確にPaul GrahamがRISDの後に何をしたかを幻想することで、埋め込み品質と最終出力を向上させます。query_bundle = hyde(query_str)hyde_doc = query_bundle.embedding_strs[0]OpenAI関数呼び出しのサポート
OpenAIは最近、GPTの機能を外部ツールやAPIとより信頼性の高い接続するための関数呼び出し機能をリリースしました。それがどのように機能するかを確認するには、以前のビデオを確認してください。
LlamaIndexはすばやくこの機能を統合し、新しいOpenAIAgentを追加しました。詳細については、このノートブックを確認してください。
機能の数があまりにも多すぎる場合は、RetrieverOpenAIAgentを使用します! このノートブックを確認してください。
LlamaIndexをLangChainと一緒に使用する方法
LlmaIndexは、さまざまなベクトルストア、ChatGPTプラグイン、トレースツール、およびLangChainとの幅広い統合を提供しています。
LIamaIndexはLangChainとどう違うのですか?
LangChainを使用したことがある場合、LIamaIndexはLangChainとどう違うのか疑問に思うかもしれません。LangChainに慣れていない場合は、以前のブログ投稿とビデオを確認してください。機能に関しては、インデックス作成、意味的検索、検索、およびベクトルデータベースなど、LIamaIndexとLangChainの間に類似点があることがわかります。彼らはどちらも、質問に答える、ドキュメントを要約する、チャットボットを構築するなどのタスクで優れています。
ただし、それぞれに独自の重点領域があります。機能のリストが豊富なLangChainは、外部APIに接続するためにチェーンとエージェントを使用することに重点を置いています。一方、LlamaIndexはデータのインデックス作成とドキュメントの検索に特化した狭い焦点を持っています。
LlamaIndexをLangChainと一緒に使用する方法
興味深いことに、LIamaIndexとLangChainは相互排他的ではありません。実際、LLMアプリケーションで両方を使用できます。LlamaIndexのデータローダーとクエリエンジン、LangChainのエージェントの両方を使用できます。自分のプロジェクトでこれらのツールの両方を使用する人が多いことを知っています。
ここでは、LangChainエージェントを使用する場合にチャット履歴を保持するためにLlamaIndexを使用した例を示します。2回目の会話で「私の名前は何ですか?」と尋ねると、言語モデルは最初の会話から「私はボブである」と知っています。
# ソース:https://github.com/jerryjliu/llama_index/blob/main/examples/langchain_demo/LangchainDemo.ipynb# LlamaIndexをメモリモジュールとして使用する
from langchain import OpenAI
from langchain.llms import OpenAIChat
from langchain.agents import initialize_agent
from llama_index import ListIndex
from llama_index.langchain_helpers.memory_wrapper import GPTIndexChatMemory
index = ListIndex([])
memory = GPTIndexChatMemory(
index=index,
memory_key="chat_history",
query_kwargs={"response_mode": "compact"}, # return_sourceはクエリインデックスの代わりにソースノードを返す
return_source=True, # return_messagesはメッセージ形式でコンテキストを返す
return_messages=True)
llm = OpenAIChat(temperature=0)# llm=OpenAI(temperature=0)
agent_executor = initialize_agent([], llm, agent="conversational-react-description", memory=memory)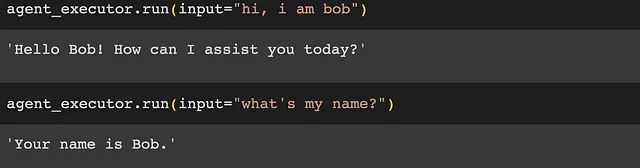
結論
LlamaIndexは、独自のデータで大規模言語モデルの機能を拡張するための非常に強力なツールです。そのデータコネクターの数々、高度なクエリインタフェース、柔軟な統合性は、LLMを用いたアプリケーション開発において不可欠なコンポーネントです。
謝辞
アドバイスとフィードバックをくれたJerry Liuさんに感謝します!

2023年6月19日、Sophia Yang著
Sophia Yangはシニアデータサイエンティストです。 LinkedIn、Twitter、YouTubeでつながり、DS/ML Book Clubに参加してください❤️
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






