Amazon Lex、Langchain、およびSageMaker Jumpstartを使用した会話型エクスペリエンスにおける生成AIの探求:イントロダクション
Introduction to exploring generative AI in conversational experiences using Amazon Lex, Langchain, and SageMaker Jumpstart.
現在の急速な世界では、顧客はビジネスから迅速かつ効率的なサービスを期待しています。しかしながら、問い合わせの量が対応する人員を上回っている場合、優れた顧客サービスを提供することは大きな課題となることがあります。しかし、大規模言語モデル(LLM)によって強化された生成AI(生成型人工知能)の進歩により、ビジネスはこの課題に対応しながら、パーソナライズされた効率的な顧客サービスを提供することができます。
生成型AIチャットボットは、人間の知性を模倣する能力で有名になりました。しかし、タスク指向のボットとは異なり、これらのボットはLLMを使用してテキスト分析とコンテンツ生成を行います。LLMはTransformerアーキテクチャに基づいており、2017年6月に導入された深層学習ニューラルネットワークであり、大量の未ラベル化されたテキストコーパスで訓練することができます。このアプローチにより、より人間らしい会話体験が生まれ、さまざまなトピックに対応できます。
この執筆時点では、あらゆる規模の企業がこの技術を利用したいと考えていますが、どこから始めればよいかわからない場合があります。もし生成型AIやLLMを会話型AIに使用することを始めたい場合は、この記事を参考にしてください。Amazon Lexボットを迅速に展開し、事前にトレーニングされたオープンソースのLLMを利用するサンプルプロジェクトを含めました。また、カスタムメモリマネージャを実装するための出発点も含まれています。このメカニズムにより、LLMは以前のやりとりを思い出し、会話の文脈とペースを保持することができます。最後に、ファインチューニングプロンプトやLLMのランダム性や決定性パラメータを実験することで、一貫した結果を得ることの重要性にも触れておきます。
ソリューションの概要
このソリューションは、Amazon SageMaker JumpStartからアクセスできる人気のあるオープンソースLLMを使用したAmazon Lexボットを統合します。また、LLMによって強化されたアプリケーションを簡素化する人気のフレームワークであるLangChainを使用します。最後に、QnABotを使用してチャットボットにユーザーインターフェースを提供します。
- オープンソースのAmazon SageMaker Distributionで始めましょう
- Amazon SageMakerでTritonを使用してMLモデルをホストする:ONNXモデル
- Amazon SageMakerのHugging Face推定器とモデルパラレルライブラリを使用してGPT-Jを微調整する

まず、前述の図の各コンポーネントについて説明します。
- JumpStartは、様々な問題タイプに対して事前にトレーニングされたオープンソースモデルを提供しています。これにより、機械学習(ML)をすぐに開始できます。FLAN-T5-XLモデルは、LLMを深層学習コンテナにデプロイしたものであり、テキスト生成を含む様々な自然言語処理(NLP)タスクで優れたパフォーマンスを発揮します。
- SageMakerリアルタイム推論エンドポイントを使用すると、イベントの予測に対してMLモデルを迅速かつスケーラブルに展開できます。Lambda関数と統合可能であるため、エンドポイントを使用してカスタムアプリケーションを構築できます。
- AWS Lambda関数は、Amazon LexボットまたはQnABotからのリクエストを使用して、LangChainを使用してSageMakerエンドポイントを呼び出すペイロードを準備します。LangChainは、LLMによって強化されたアプリケーションを開発できるフレームワークです。
- Amazon Lex V2ボットには、
AMAZON.FallbackIntentインテントタイプが組み込まれています。これは、ユーザーの入力がボットのいずれのインテントにも一致しない場合にトリガーされます。 - QnABotは、Amazon Lexボットにユーザーインターフェースを提供するためのオープンソースのAWSソリューションです。Lambdaフック関数を
CustomNoMatchesアイテムに構成し、QnABotが回答を見つけられなかった場合にLambda関数をトリガーするように構成しました。すでに展開しているものと仮定し、次のセクションに構成手順を含めました。
このソリューションは、以下のシーケンス図で高レベルに説明されています。
ソリューションによって実行される主なタスク
このセクションでは、当社のソリューションで実行される主要なタスクについて説明します。このソリューションのプロジェクト全体のソースコードは、このGitHubリポジトリで参照できます。
チャットボットのフォールバックを処理する
Lambda関数は、Amazon Lex V2のAMAZON.FallbackIntentおよびQnABotのCustomNoMatchesアイテムを介して「わからない」回答を処理します。トリガーされると、この関数はセッションとフォールバックインテントのリクエストを確認します。一致する場合は、Lex V2ディスパッチャにリクエストを引き渡します。そうでなければ、QnABotディスパッチャがリクエストを使用します。以下のコードを参照してください。
def dispatch_lexv2(request):
"""概要
Args:
request (dict): ユーザーの入力チャットメッセージとコンテキスト(過去の会話)を含むLambdaイベント
過去の入力を管理するために、LexV2セッションAPIを使用します。https://docs.aws.amazon.com/lexv2/latest/dg/using-sessions.html
Returns:
dict: 説明
"""
lexv2_dispatcher = LexV2SMLangchainDispatcher(request)
return lexv2_dispatcher.dispatch_intent()
def dispatch_QnABot(request):
"""概要
Args:
request (dict): ユーザーの入力チャットメッセージとコンテキスト(過去の会話)を含むLambdaイベント
Returns:
dict: AWS SolutionのQnABotに対する「わからない」回答のラムダフックとしてドキュメント化された形式のdict
https://docs.aws.amazon.com/solutions/latest/QnABot-on-aws/specifying-lambda-hook-functions.html
"""
request['res']['message'] = "こんにちは!これはあなたのカスタムPythonフックです!"
qna_intent_dispatcher = QnASMLangchainDispatcher(request)
return qna_intent_dispatcher.dispatch_intent()
def lambda_handler(event, context):
print(event)
if 'sessionState' in event:
if 'intent' in event['sessionState']:
if 'name' in event['sessionState']['intent']:
if event['sessionState']['intent']['name'] == 'FallbackIntent':
return dispatch_lexv2(event)
else:
return dispatch_QnABot(event)LLMにメモリを提供する
マルチターンの会話でLLMメモリを保存するため、Lambda関数にはAmazon Lex V2 Sessions APIを使用してセッション属性を追跡し、以前のやりとりを介して会話モデルに文脈を提供するLangChainカスタムメモリクラスメカニズムが含まれています。以下のコードを参照してください:
class LexConversationalMemory(BaseMemory, BaseModel):
"""Lex Conversation履歴を使用するLangchainカスタムメモリクラス
Attributes:
history (dict): Langchainメモリとして機能する会話履歴を格納するdict
lex_conv_context (str): 会話履歴の入力となるLexV2 Sessions API
メモリはここからロードされます
memory_key (str): chat history Langchainメモリ変数のキー - "history"
"""
history = {}
memory_key = "chat_history" #キーをpromptに渡す
lex_conv_context = ""
def clear(self):
"""チャット履歴をクリアする
"""
self.history = {}
@property
def memory_variables(self) -> List[str]:
"""メモリ変数をロードする
Returns:
List[str]: Langchainメモリを含むキーのリスト
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, str]:
"""Lexからメモリをロードして現在のLangchainセッションメモリにロードする
Args:
inputs (Dict[str, Any]): 現在のLangchainセッションのユーザー入力
Returns:
Dict[str, str]: Langchainメモリオブジェクト
"""
input_text = inputs[list(inputs.keys())[0]]
ccontext = json.loads(self.lex_conv_context)
memory = {
self.memory_key: ccontext[self.memory_key] + input_text + "\nAI: ",
}
return memory以下は、LangChain ConversationChainでカスタムメモリクラスを紹介するために作成したサンプルコードです:
#プロンプト、Sagemakerにホストされたllm、およびカスタムメモリクラスを使用して会話チェーンを作成する
self.chain = ConversationChain(
llm=sm_flant5_llm,
prompt=prompt,
memory=LexConversationalMemory(lex_conv_context=lex_conv_history),
verbose=True
)プロンプトの定義
LLMのプロンプトとは、生成された応答のトーンを設定する質問または文です。プロンプトは、関連する応答を生成するためにモデルを誘導するコンテキストの形式として機能します。以下のコードを参照してください:
#プロンプトを定義する
prompt_template = """以下は、人間とAIの友好的な会話です。 AIはおしゃべりであり、コンテキストから多くの具体的な詳細を提供します。 AIが質問に答えられない場合は、真実を言います。 関連する場合は、Humanが言及したエンティティについての情報を提供します。
チャット履歴:
{chat_history}
会話:
Human:{input}
AI:"""LLMメモリサポートにAmazon Lex V2セッションを使用する
ユーザーがボットに対話すると、Amazon Lex V2はセッションを開始します。セッションは手動で停止するかタイムアウトするまで時間をかけて継続します。セッションには、セッション属性として知られるメタデータとアプリケーション固有のデータが格納されます。Lambda関数がセッション属性を追加または変更すると、Amazon Lexはクライアントアプリケーションを更新します。QnABotには、Amazon Lex V2の上にセッション属性を設定および取得するインターフェースが含まれています。
私たちのコードでは、LangChain内のカスタムメモリクラスを構築するためにこのメカニズムを使用して、会話履歴を追跡し、LLMが短期および長期の相互作用を思い出すことができるようにしました。次のコードを参照してください。
class LexV2SMLangchainDispatcher():
def __init__(self, intent_request):
# See lex bot input format to lambda https://docs.aws.amazon.com/lex/latest/dg/lambda-input-response-format.html
self.intent_request = intent_request
self.localeId = self.intent_request['bot']['localeId']
self.input_transcript = self.intent_request['inputTranscript'] # user input
self.session_attributes = utils.get_session_attributes(
self.intent_request)
self.fulfillment_state = "Fulfilled"
self.text = "" # response from endpoint
self.message = {'contentType': 'PlainText','content': self.text}
class QnABotSMLangchainDispatcher():
def __init__(self, intent_request):
# QnABot Session attributes
self.intent_request = intent_request
self.input_transcript = self.intent_request['req']['question']
self.intent_name = self.intent_request['req']['intentname']
self.session_attributes = self.intent_request['req']['session']前提条件
展開を開始するには、次の前提条件を満たす必要があります。
- AWS CloudFormationスタックを起動できるユーザー経由でAWS Management Consoleにアクセスすることができます
- LambdaおよびAmazon Lexコンソールをナビゲートすることに慣れています
ソリューションの展開
ソリューションを展開するには、次の手順を実行してください。
- Launch Stackを選択して、
us-east-1リージョンでソリューションを起動します:
- スタック名に、一意のスタック名を入力してください。
- HFModelでは、JumpStartで利用可能な
Hugging Face Flan-T5-XLモデルを使用しています。 - HFTaskには
text2textを入力してください。 - S3BucketNameはそのままにしておいてください。
これらは、ソリューションを展開するために必要なAmazon Simple Storage Service(Amazon S3)アセットを検索するために使用され、この投稿の更新に伴って変更される可能性があります。

- 機能について認識する。
- スタックを作成を選択してください。
正常に作成されたスタックは4つあります。

Amazon Lex V2ボットの構成
Amazon Lex V2ボットには何もする必要はありません。CloudFormationテンプレートがすでに重い作業を行いました。
QnABotの構成
既に環境に展開されているQnABotがあることを前提としています。ただし、必要に応じて、展開手順に従って展開してください。
- AWS CloudFormationコンソールで、展開したメインスタックに移動します。
- 出力タブで、
LambdaHookFunctionArnをメモしてください。これは、後でQnABotに挿入する必要があります。

- 管理者としてQnABot Designer User Interface (UI)にログインしてください。
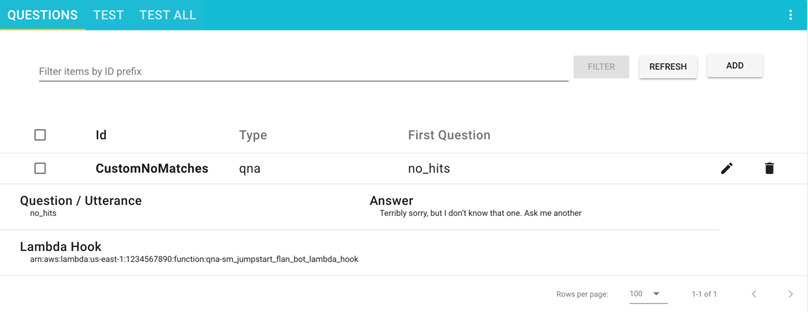
- Questions UIで、新しい質問を追加してください。

- 以下の値を入力してください:
- ID –
CustomNoMatches - Question –
no_hits - Answer – 「分からない」に対するデフォルトの回答
- ID –
- Advancedを選択して、Lambda Hookセクションに移動してください。
- 以前にメモしたLambda関数のAmazon Resource Name (ARN)を入力してください。
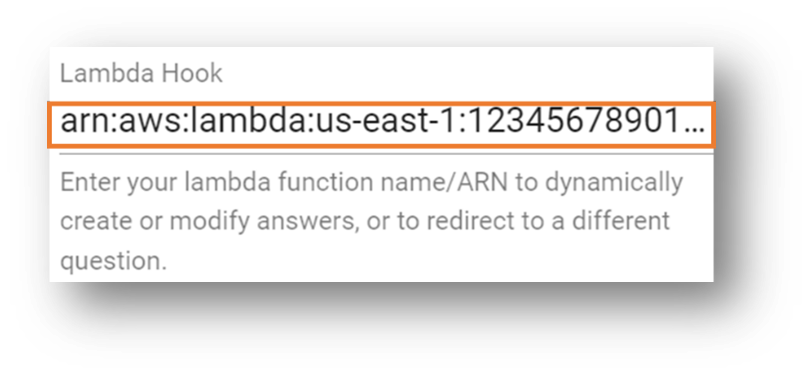
- セクションの最下部までスクロールして、Createを選択してください。
成功メッセージが表示されるウィンドウが表示されます。

質問はQuestionsページに表示されます。
ソリューションのテスト
次に、ソリューションをテストしてみましょう。FLAN-T5-XLモデルはJumpStartによって提供され、ファインチューニングなしで展開されています。これにより、応答にわずかなばらつきが生じる可能性があります。
Amazon Lex V2ボットでのテスト
このセクションでは、SageMakerエンドポイントにデプロイされたLLMを呼び出すLambda関数とのAmazon Lex V2ボットの統合をテストする手順を説明します。
- Amazon Lexコンソールで、
Sagemaker-Jumpstart-Flan-LLM-Fallback-Botという名前のボットに移動してください。このボットは、他のインテントが一致しない場合にフォールバックインテントとしてSageMakerエンドポイントを呼び出すLambda関数を呼び出すように構成されています。 - ナビゲーションペインでIntentsを選択してください。

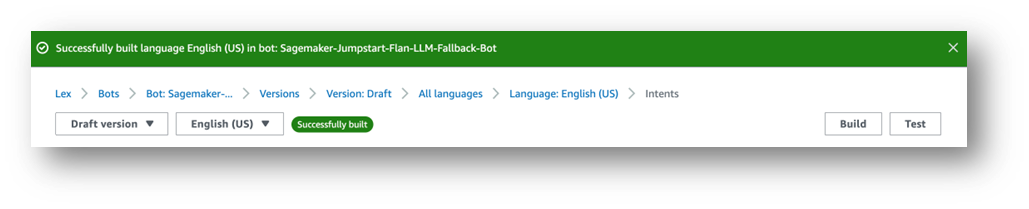
右上に「English (US) has not built changes.」というメッセージが表示されます。
- Buildを選択してください。
- 完了まで待ちます。
最後に、次のスクリーンショットに示すように、成功メッセージが表示されます。
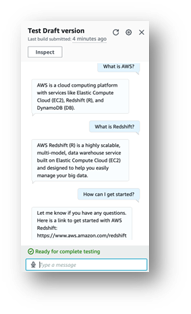
- テストを選択します。
モデルと対話できるチャットウィンドウが表示されます。
Amazon LexボットとAmazon Connectの組み込みインテグレーション、またはメッセージングプラットフォーム(Facebook、Slack、Twilio SMS)やAmazon Chime SDKおよびGenesys Cloudなどのサードパーティコンタクトセンターなど、さまざまな統合をお勧めします。
QnABotインスタンスでテストする
このセクションは、SageMakerエンドポイントにデプロイされたLLMを呼び出すLambda関数とのQnABot on AWSインテグレーションをテストします。
- 左上のツールメニューを開きます。
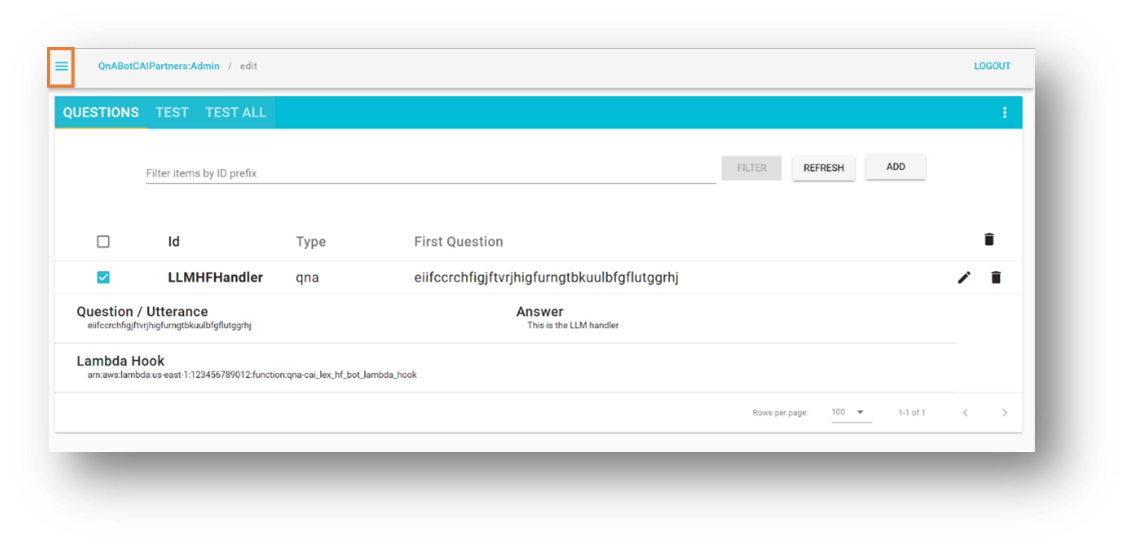
- QnABotクライアントを選択します。
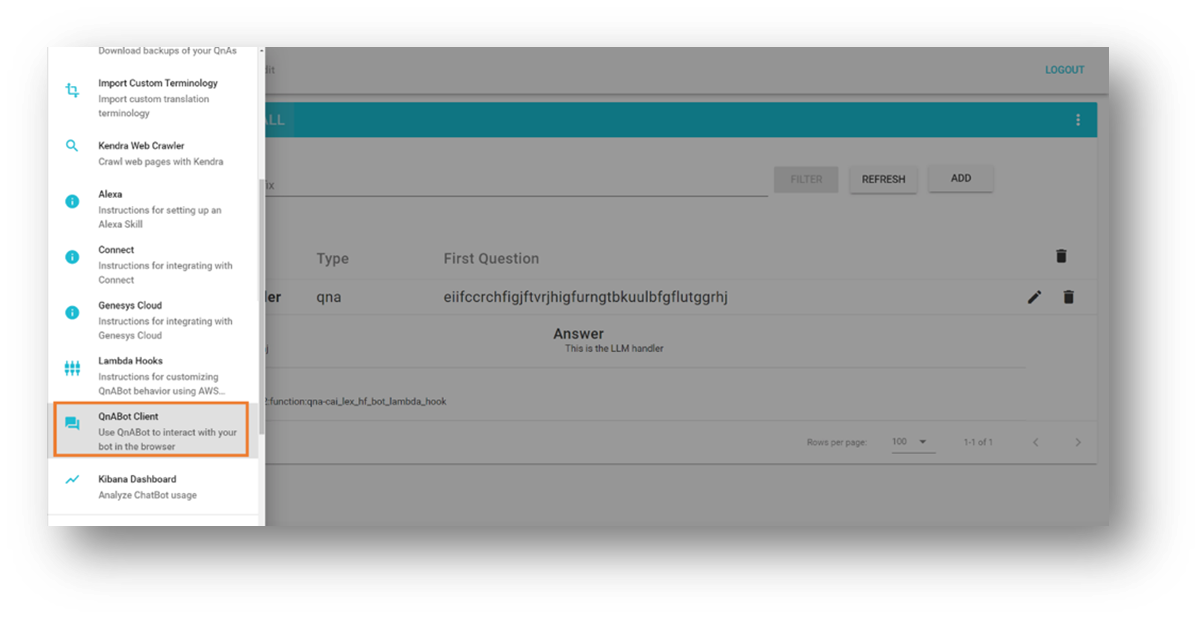
- 管理者としてサインインを選択します。

- ユーザーインターフェースに質問を入力します。
- 応答を評価します。

クリーンアップ
今後の料金発生を避けるために、以下の手順に従ってソリューションで作成されたリソースを削除してください。
- AWS CloudFormationコンソールで、
SagemakerFlanLLMStack(またはスタックに設定したカスタム名)という名前のスタックを選択します。 - 削除を選択します。
- テストのためにQnABotインスタンスをデプロイした場合は、QnABotスタックを選択します。
- 削除を選択します。
結論
この投稿では、タスク指向のボットにオープンドメインの機能を追加し、オープンソースの大規模言語モデルにユーザーのリクエストをルーティングする方法を探索しました。
以下をお勧めします:
- 会話履歴を外部の永続メカニズムに保存する。たとえば、Amazon DynamoDBやS3バケットに会話履歴を保存して、Lambda関数フックで取得することができます。これにより、Amazon Lexが提供する内部の非永続的セッション属性管理に依存する必要がなくなります。
- 要約を試してみる – マルチターンの会話では、プロンプトにコンテキストを追加して会話履歴の使用を制限するために、要約を生成することが役立ちます。これにより、ボットセッションのサイズを削減し、Lambda関数のメモリ消費量を低く保つことができます。
- プロンプトバリエーションを試してみる – 実験目的に合わせて元のプロンプト説明を変更します。
- 最適な結果のために言語モデルを適応する – アプリケーションに合わせてランダム性(
temperature)や決定論性(top_p)などの高度なLLMパラメータを微調整することができます。私たちは、サンプル値を使用した事前トレーニングされたモデルを使用したサンプル統合を示しましたが、使用ケースに合わせて値を調整して楽しんでください。
次回の投稿では、事前に学習されたLLMを使用したチャットボットを、独自のデータで微調整する方法を紹介します。
AWSでLLMチャットボットを試している場合は、コメントでお知らせください!
リソースと参考文献
- この投稿のコンパニオン・ソースコード
- Amazon Lex V2 開発者ガイド
- AWSソリューションライブラリ:AWS上のQnABot
- FLAN T5モデルを使用したText2Text Generation
- LLMを使用したアプリケーションの構築 – LangChain
- Jumpstart Foundationモデルを使用したAmazon SageMakerの例
- Amazon BedRock – ファンデーションモデルを使用してジェネラティブAIアプリケーションを構築およびスケーリングするための最も簡単な方法
- Amazon Kendra、LangChain、および大規模言語モデルを使用して企業データで高精度なジェネラティブAIアプリケーションを迅速に構築する
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






