Amazon SageMakerを使用した生成型AIモデルにおいて、Forethoughtがコストを66%以上削減する方法
How Forethought can reduce costs by 66% or more in AI models using Amazon SageMaker.
この投稿は、Forethought Technologies, Inc.のエンジニアリングディレクターであるJad ChamounとForethought Technologies, Inc.のシニアMLエンジニアであるSalina Wuが共同執筆しています。
Forethoughtは、顧客サービス向けの主要な生成AIスイートです。スイートの中核には、顧客サポートライフサイクルを変革するために機械学習を使用する革新的なSupportGPT™テクノロジーがあり、逸脱率の向上、CSATの改善、およびエージェントの生産性の向上を実現しています。SupportGPT™は、最新の情報検索(IR)システムと大規模言語モデル(LLM)を活用して、年間3000万件以上の顧客インタラクションを支援しています。

SupportGPT™の主な使用用途は、顧客サポートのインタラクションとオペレーションの品質と効率を向上させることです。埋め込みとランキングモデルを活用した最新のIRシステムを使用することで、SupportGPT™は迅速に関連する情報を検索し、正確で簡潔な回答を顧客のクエリに提供することができます。Forethoughtは、顧客の意図を検出し、顧客インタラクションを解決するために、カスタマイズされたモデルを使用しています。大規模言語モデルの統合により、自動エージェントとのインタラクションを人間らしくし、より魅力的で満足のいくサポート体験を実現しています。
- BrainPadがAmazon Kendraを使用して内部の知識共有を促進する方法
- Amazon TranslateのActive Custom Translationを使用して、マルチリンガル自動翻訳パイプラインを構築します
SupportGPT™は、自動補完の提案や、以前の返信に基づいて企業に合わせた適切な顧客チケットへの回答の作成を提供することで、顧客サポートエージェントを支援しています。高度な言語モデルを使用することで、エージェントはより迅速かつ正確に顧客の懸念に対処し、より高い顧客満足度を実現します。
また、SupportGPT™のアーキテクチャは、サポートナレッジベースのギャップを検出することができ、エージェントが顧客により正確な情報を提供することができます。これらのギャップが特定されると、SupportGPT™は、これらのナレッジの空白を埋めるための記事やその他のコンテンツを自動生成することができます。これにより、サポートナレッジベースが顧客中心で最新の状態に保たれます。
この記事では、Forethoughtが生成AIユースケースでAmazon SageMakerのマルチモデルエンドポイントを使用して、コストを66%削減する方法を共有します。
インフラストラクチャの課題
これらの機能を市場に提供するために、ForethoughtはMLワークロードを効率的にスケーリングし、それぞれの顧客の特定のユースケースに合わせたハイパーカスタマイズされたソリューションを提供しています。このハイパーカスタマイゼーションは、カスタマーデータに埋め込みモデルと分類器を微調整して実現し、正確な情報検索結果と、各クライアントのユニークなニーズに対応するドメイン知識を保証します。カスタマイズされた自動補完モデルも、顧客データで微調整され、生成される回答の正確性と関連性がさらに向上します。
AI処理における重要な課題の1つは、GPUなどのハードウェアリソースの効率的な利用です。この課題に対処するため、ForethoughtはSageMakerマルチモデルエンドポイント(MME)を使用して、1つの推論エンドポイントで複数のAIモデルを実行し、スケールを拡大しています。モデルのハイパーカスタマイゼーションには、独自のモデルをトレーニングして展開する必要があるため、モデルの数はクライアントの数と線形的にスケーリングし、コストがかかる可能性があります。
リアルタイム推論のパフォーマンスとコストの適切なバランスを実現するために、ForethoughtはSageMaker MMEを使用することを選択しました。SageMaker MMEはGPUアクセラレーションをサポートしており、高性能でスケーラブルで、サブセカンドレイテンシーで費用効果の高いソリューションを提供し、スケールで複数の顧客サポートシナリオに対応します。
SageMakerとForethought
SageMakerは、開発者とデータサイエンティストが迅速にMLモデルを構築、トレーニング、展開することができる、完全に管理されたサービスです。SageMaker MMEは、大量のモデルをリアルタイム推論のために展開するためのスケーラブルで費用効果の高いソリューションを提供します。MMEは、共有サービングコンテナとリソースフリートを使用し、すべてのモデルをホストするためにGPUなどのアクセラレーションインスタンスを使用できます。これは、シングルモデルエンドポイントを使用する場合に比べてエンドポイントの利用率を最大化することにより、ホスティングコストを削減します。また、SageMakerは、エンドポイントのトラフィックパターンに基づいてモデルの読み込みとアンロードを管理し、スケーリングするための組み込み機能を備えているため、展開オーバーヘッドも低減されます。さらに、すべてのSageMakerリアルタイムエンドポイントは、シャドウバリアント、自動スケーリング、およびAmazon CloudWatchとのネイティブ統合など、モデルを管理および監視するための組み込み機能を備えています(詳細については、マルチモデルエンドポイント展開のCloudWatchメトリックを参照してください)。
ForethoughtがGPUリソースも必要とする数百のモデルをホストするにつれて、SageMaker MMEを介したより費用効果が高く、信頼性が高く、管理が容易なアーキテクチャを作成する機会がありました。SageMaker MMEに移行する前は、モデルはAmazon Elastic Kubernetes Service(Amazon EKS)上のKubernetesに展開されていました。Amazon EKSは管理機能を提供していましたが、推論に特化したインフラストラクチャではなかったため、ForethoughtはAmazon EKSでモデル推論を自分たちで管理する必要がありました。たとえば、複数のモデル間で高価なGPUリソースを共有するために、展開時に指定されたモデルごとに厳格なメモリ割り当てを行う責任がありました。Forethoughtは、次の主要な問題を解決したかったのです。
- 高いコスト – 各モデルに十分なリソースが割り当てられるように、1つのインスタンスあたりにフィットするモデル数に非常に慎重でした。これにより、モデルホスティングのコストが必要以上に高くなってしまいました。
- 低い信頼性 – メモリ割り当てに慎重であったにもかかわらず、すべてのモデルが同じ要件を持っているわけではなく、場合によってはモデルがメモリ不足エラー(OOM)を投げることがありました。
- 非効率的な管理 – 分類器、埋め込み、自動補完など、各種類のモデルごとに異なるデプロイメントマニフェストを管理する必要があり、時間がかかり、エラーが発生しやすかったです。また、異なるモデルタイプのメモリ割り当てを決定するためのロジックも維持する必要がありました。
結局、ランタイムでモデルを管理するための推論プラットフォームが必要であり、コスト、信頼性、モデルの配信管理を改善するためにSageMaker MMEを使用することにしました。
SageMaker MMEは、スマートかつダイナミックなモデルのロードおよびアンロード、およびスケーリング機能により、モデルホスティングのコストを大幅に削減し、信頼性が向上しました。今では、1つのインスタンスに多数のモデルをフィットさせることができ、SageMaker MMEがモデルの動的なロードおよびアンロードを処理するため、OOMエラーの心配をする必要がありません。さらに、デプロイメントは、Boto3 SageMaker APIを呼び出し、適切なオートスケーリングポリシーを添付するだけで簡単に行えます。
以下の図は、私たちの既存のアーキテクチャを示しています。
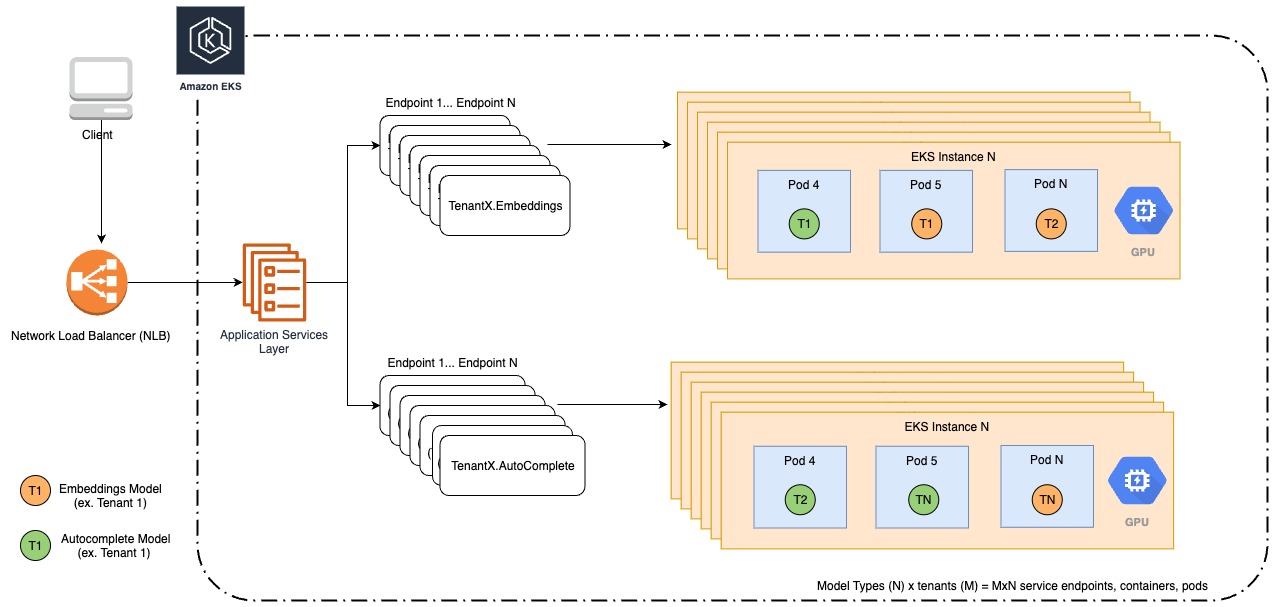
SageMaker MMEへの移行を開始するにあたり、MMEの最適なユースケースと、この変更に最も利益をもたらすモデルを特定しました。MMEは、以下のようなモデルに最適です。
- レイテンシが低く、コールドスタート時間(最初にロードされたとき)に耐えられるモデル
- 頻繁で一貫して呼び出されるモデル
- 一部のGPUリソースが必要なモデル
- 共通の要件と推論ロジックを共有するモデル
私たちは、埋め込みモデルとオートコンプリート言語モデルを移行するための最適な候補として特定しました。これらのモデルをMMEの下で整理するために、モデルタイプまたはタスクごとに1つのMME、すなわち埋め込みモデル用の1つとオートコンプリート言語モデル用のもう1つを作成します。
私たちはすでに、モデルの管理と推論のためのAPIレイヤーを持っていました。私たちの課題は、このAPIがSageMakerでモデルをデプロイし、推論を処理する方法を再設計することでしたが、クライアントや製品チームがAPIとやり取りする方法には最小限の変更しか必要ありませんでした。また、私たちは、NVIDIA Triton Inference Serverに互換性があるように、モデルとカスタム推論ロジックをSageMaker MMEでパッケージ化する必要がありました。
以下の図は、私たちの新しいアーキテクチャを示しています。
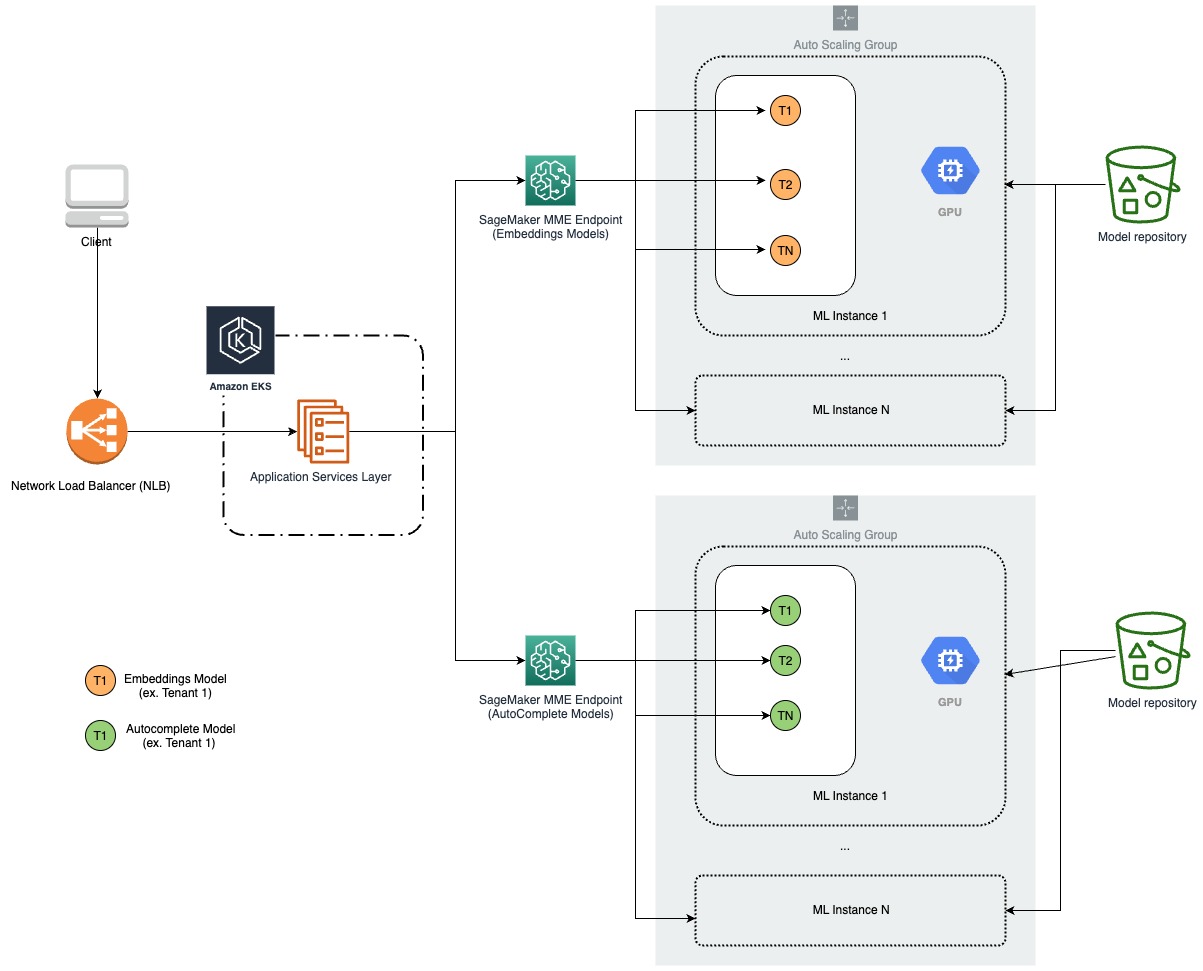
カスタム推論ロジック
SageMakerに移行する前、Forethoughtのカスタム推論コード(前処理と後処理)は、モデルが呼び出されたときにAPIレイヤーで実行されていました。目的は、責任の分離を明確にし、コードをモジュール化して簡素化し、APIの負荷を減らすために、この機能をモデル自体に移行することでした。
埋め込み
Forethoughtの埋め込みモデルは、2つのPyTorchモデルアーティファクトから構成されており、推論リクエストによって呼び出すモデルが決定されます。各モデルは、前処理されたテキストを入力として必要とします。主な課題は、前処理ステップの統合と、モデル定義ごとに2つのモデルアーティファクトを収容することでした。推論ロジックで複数のステップを必要とすることを考慮し、Forethoughtは、2つのステップを持つTritonアンサンブルモデルを開発しました。Pythonバックエンドの前処理プロセスとPyTorchバックエンドのモデルコールです。アンサンブルモデルは、各ステップを任意のバックエンドタイプのTritonモデルで表し、推論ロジックのステップを定義および順序付けることができます。Triton PyTorchバックエンドとの互換性を確保するために、既存のモデルアーティファクトはTorchScript形式に変換されました。各モデル定義に対して別々のTritonモデルが作成され、ForethoughtのAPIレイヤーが着信リクエストに基づいて適切なTargetModelを呼び出す責任を持ちました。
オートコンプリート
オートコンプリートモデル(シーケンス・トゥ・シーケンス)には、異なる要件がありました。特に、複数のモデル呼び出しをループさせ、各呼び出しの大量の入力をキャッシュする機能を有効にする必要がありましたが、レイテンシを低く保つ必要がありました。さらに、これらのモデルには前処理と後処理の両方のステップが必要でした。これらの要件を満たし、所望の柔軟性を実現するために、Forethoughtは、Triton Pythonバックエンドを利用したオートコンプリートMMEモデルを開発しました。この方法では、モデルをPythonコードとして記述することができます。
ベンチマーク
Tritonモデルの形状が決定した後、ステージングエンドポイントにモデルを展開し、リソースとパフォーマンスのベンチマークを実施しました。主な目標は、コールドスタートとインメモリモデルのレイテンシー、レクエストサイズと同時性がどのようにレイテンシーに影響するかを決定することでした。また、各インスタンスにどの程度のモデルを収容できるか、どの程度のモデルが自動スケーリングポリシーによってインスタンスをスケールアップするか、そしてスケールアップがどの程度速く行われるかを知りたかった。既に使用していたインスタンスタイプに合わせて、ml.g4dn.xlargeおよびml.g4dn.2xlargeインスタンスでベンチマークを実施しました。
結果
以下の表は、私たちの結果をまとめたものです。
| リクエストサイズ | コールドスタートレイテンシー | キャッシュされた推論レイテンシー | 同時性のレイテンシー(5リクエスト) |
| 小(30トークン) | 12.7秒 | 0.03秒 | 0.12秒 |
| VoAGI(250トークン) | 12.7秒 | 0.05秒 | 0.12秒 |
| 大(550トークン) | 12.7秒 | 0.13秒 | 0.12秒 |
特に、コールドスタートリクエストのレイテンシーは、キャッシュされた推論リクエストのレイテンシーよりも著しく高いことがわかります。これは、コールドスタートリクエストが行われた場合、モデルをディスクまたはAmazon Simple Storage Service(Amazon S3)からロードする必要があるためです。同時リクエストのレイテンシーも、シングルリクエストのレイテンシーよりも高くなります。これは、モデルを同時リクエスト間で共有する必要があるため、競合が生じる可能性があるためです。
以下の表は、レガシーモデルとSageMakerモデルのレイテンシーを比較したものです。
| リクエストサイズ | レガシーモデル | SageMakerモデル |
| 小(30トークン) | 0.74秒 | 0.24秒 |
| VoAGI(250トークン) | 0.74秒 | 0.24秒 |
| 大(550トークン) | 0.80秒 | 0.32秒 |
全体的に、SageMakerモデルはレガシーモデルよりも自動補完モデルのホスティングに適しています。低いレイテンシー、スケーラビリティ、信頼性、セキュリティを提供します。
リソース使用量
各インスタンスに収容できる最適なモデル数を決定するために、一連のテストを実施しました。ml.g4dn.xlargeインスタンスタイプを使用して、自動スケーリングポリシーなしでモデルをエンドポイントにロードする実験を行いました。
これらの特定のインスタンスは、15.5 GBのメモリを提供しており、各GPUメモリ使用率が80%程度になるように目標を設定しました。各エンコーダモデルアーティファクトのサイズを考慮すると、目標のGPUメモリ使用率に到達するために1つのインスタンスにロードする最適なTritonエンコーダの数を見つけることができました。さらに、各埋め込みモデルが2つのTritonエンコーダモデルに対応するため、1つのインスタンスに収容できる埋め込みモデルの数を決定することができました。その結果、すべての埋め込みモデルをサービスするために必要なインスタンスの総数を計算しました。この実験は、リソース使用量を最適化し、モデルの効率を向上させる上で重要でした。
私たちは、オートコンプリートモデルについても同様のベンチマークを実施しました。これらのモデルはそれぞれ約292.0MBでした。単一のml.g4dn.xlargeインスタンスにどのくらいのモデルが適合するかをテストしたところ、モデルのサイズが小さいにもかかわらず、インスタンスがモデルをアンロードし始める前に4つのモデルしか適合しないことがわかりました。私たちの主な懸念点は以下のとおりです。
- CPUメモリ使用量の上昇原因
- 最近使用されたモデル(LRU)ではなく、1つのモデルだけをロードしようとすると、モデルがアンロードされる原因
私たちは、PythonモデルでCUDAランタイム環境を初期化することからCPUメモリ使用量が急増する原因を突き止めました。これは、モデルとデータをGPUデバイスに移動するために必要なものでした。CUDAは、ランタイムが初期化されると、多数の外部依存関係をCPUメモリにロードします。Triton PyTorchバックエンドは、データをGPUデバイスに移動することを扱い、抽象化するため、埋め込みモデルではこの問題に遭遇しませんでした。この問題に対処するために、同じGPUメモリ容量を持つがCPUメモリが2倍のml.g4dn.2xlargeインスタンスを使用しました。さらに、テンソルの使用後の削除、キャッシュのクリア、勾配の無効化、およびガベージコレクションなど、Pythonバックエンドコードのいくつかの最適化を追加しました。大きなインスタンスタイプを使用すると、1つのインスタンスあたり10個のモデルを適合させ、CPUとGPUメモリ使用量がより一致したものになりました。
以下の図は、このアーキテクチャを示しています。
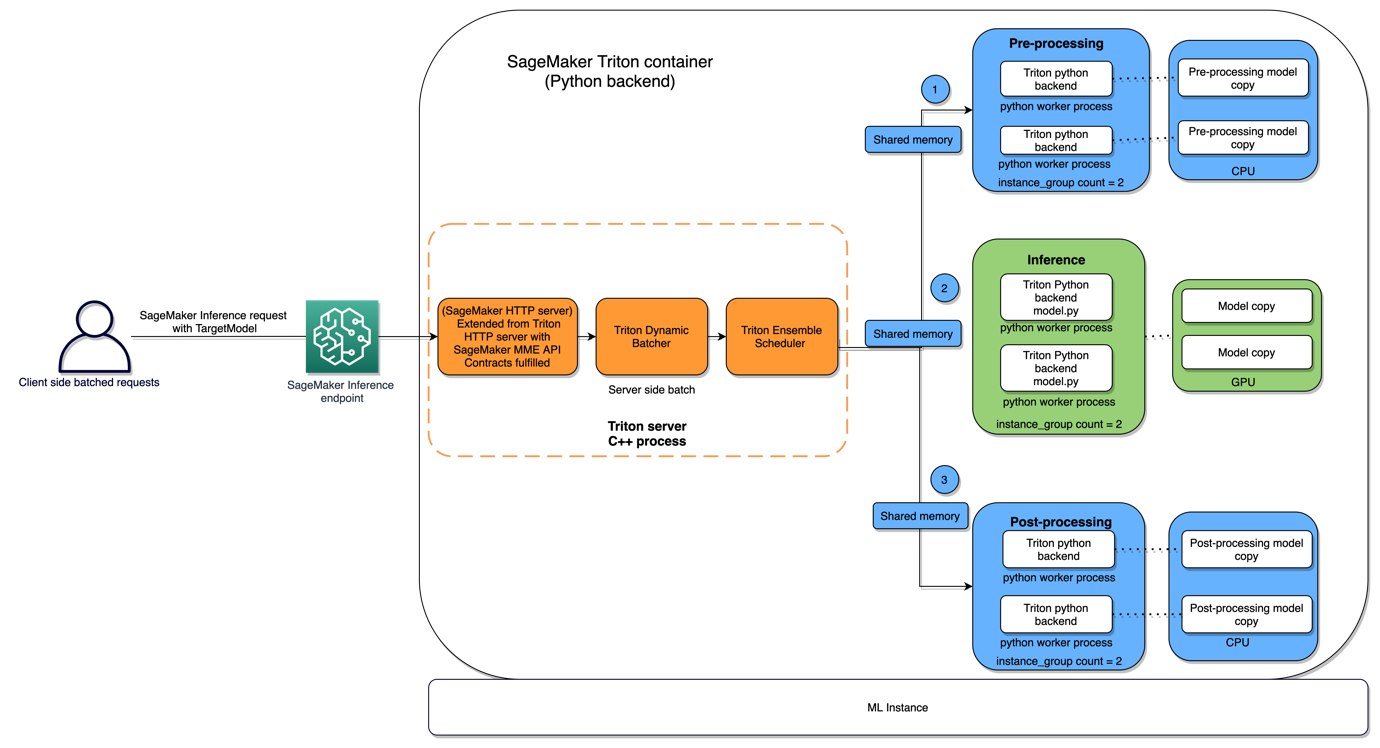
オートスケーリング
埋め込みエンドポイントとオートコンプリートMMEの両方に自動スケーリングポリシーを添付しました。私たちの埋め込みエンドポイントのポリシーは、カスタムメトリックを使用して80%の平均GPUメモリ使用量を対象としました。私たちのオートコンプリートモデルは、ビジネス時間中は高いトラフィックパターンを示し、夜間は最小限のトラフィックしかありませんでした。このため、トラフィックパターンに基づいたInvocationsPerInstanceに基づいた自動スケーリングポリシーを作成し、信頼性を犠牲にすることなくコストを節約できるようにしました。リソース使用のベンチマークに基づいて、スケーリングポリシーを225 InvocationsPerInstanceのターゲットで構成しました。
ロジックとパイプラインの展開
SageMakerでのMMEの作成は簡単で、他のエンドポイントと同様に行います。エンドポイントが作成されたら、モデルアーティファクトをエンドポイントがターゲットするS3パスに移動するだけで、エンドポイントに追加のモデルを追加することができます。この時点で、新しいモデルに対する推論リクエストを行うことができます。
私たちは、モデルメタデータを受け取り、メタデータに基づいてエンドポイントを決定的にフォーマットし、エンドポイントが存在するかどうかを確認し、存在しない場合はエンドポイントを作成し、TritonモデルアーティファクトをエンドポイントのS3パスに追加するようにロジックを定義しました。たとえば、モデルメタデータがオートコンプリートモデルであることを示す場合、オートコンプリートモデル用のエンドポイントを作成し、オートコンプリートモデルアーティファクト用の関連するS3パスを作成します。エンドポイントが存在する場合は、モデルアーティファクトをS3パスにコピーします。
これで、MMEモデルのモデルシェイプとモデルをMMEに展開する機能があるため、展開を自動化する方法が必要になります。ユーザーは展開したいモデルを指定する必要があります。私たちは、モデルのパッケージ化と展開を処理します。モデルと一緒にパッケージ化されたカスタム推論コードはバージョン管理され、Amazon S3にプッシュされます。パッケージングステップでは、指定されたバージョン(または最新バージョン)に基づいて推論コードを取得し、Tritonモデルのファイル構造を示すYAMLファイルを使用します。
私たちの要件の1つは、すべてのMMEモデルをメモリにロードして、プロダクション推論リクエスト中にコールドスタートのレイテンシを回避することでした。これを実現するために、私たちは、すべてのモデルに適合するだけのリソースを提供し、毎時MME内のすべてのモデルを呼び出しました。
以下の図は、モデル展開パイプラインを示しています。
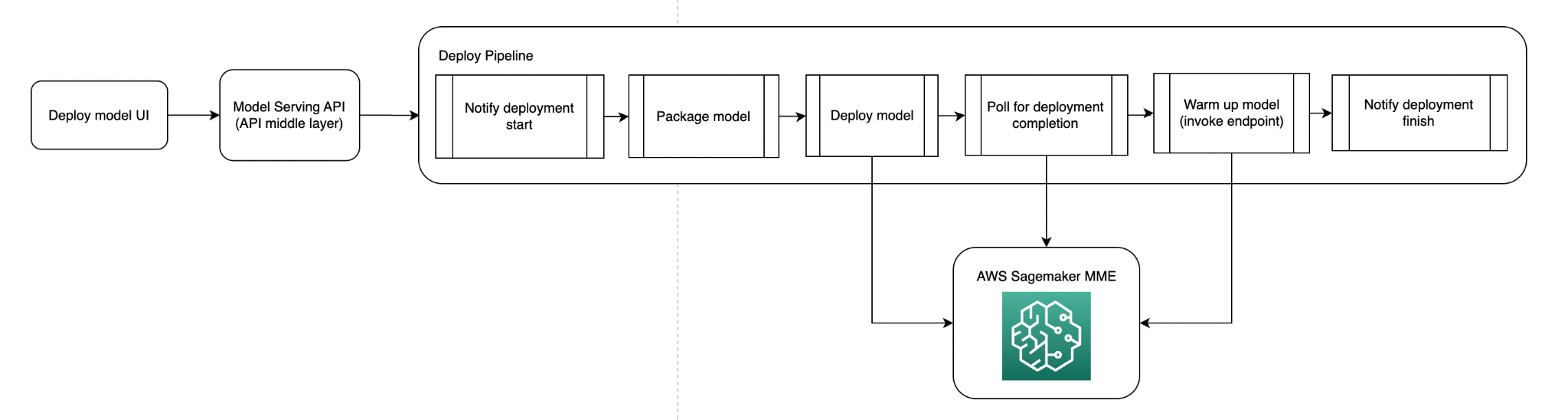
以下の図は、モデルウォームアップパイプラインを示しています。

モデル呼び出し
現在のAPIレイヤーでは、すべてのMLモデルに対する推論を行うための抽象化が提供されています。これにより、呼び出しコードの変更なしに、推論リクエストに応じた適切なターゲットモデルでSageMaker MMEを呼び出すAPIレイヤーの機能を追加するだけで済みました。SageMaker推論コードは、推論リクエストを取得し、私たちのTritonモデルで定義されたTriton入力をフォーマットし、Boto3を使用してMMEを呼び出します。
コスト削減のメリット
SageMaker MMEへの移行により、Forethoughtはモデルホスティングコストを大幅に削減し、モデルOOMエラーを軽減することができました。この変更前は、Amazon EKSで実行されているml.g4dn.xlargeインスタンスがありました。MMEへの移行により、インスタンスごとに12個の埋め込みモデルを格納でき、80%のGPUメモリ使用率を達成できることがわかりました。これにより、月間費用が大幅に削減されました。例えば、80%までコストが削減され、3つのレプリカを使用する場合でも、コスト削減が約43%になることがわかりました。
SageMaker MMEを使用することで、最適なモデルパフォーマンスを維持しながら、費用を削減することができました。以前は、Forethoughtの自動補完言語モデルはAmazon EKSに展開され、モデルごとのメモリ割り当てに基づいて異なる数のml.g4dn.xlargeインスタンスが必要でした。これにより、かなりの月額費用が発生しました。しかし、最近のSageMaker MMEへの移行により、これらのコストを大幅に削減することができました。すべてのモデルをml.g4dn.2xlargeインスタンスにホストすることで、モデルをより効率的にパックすることができました。これにより、月間費用が大幅に削減され、コスト削減率は66〜74%に達しました。この移行により、SageMaker MMEを使用することで、効率的なリソース利用がどのようにして大幅な財務的節約につながるかを実証しました。
結論
本投稿では、ForethoughtがSageMakerマルチモデルエンドポイントを使用してリアルタイム推論のコストを削減する方法を説明しました。 SageMakerは未分化の重い作業を引き受けるため、Forethoughtはエンジニアリング効率を向上させることができます。また、ビジネスクリティカルな操作に必要なパフォーマンスを維持しながら、リアルタイム推論のコストを劇的に削減することができます。これにより、Forethoughtは超個人化モデルを使用した顧客向けの差別化提供を実現することができます。 SageMaker MMEを使用してモデルをスケーリングしてホストし、エンドポイントの利用を改善してホスティングコストを削減することができます。トラフィックパターンに基づいてモデルをメモリにロードし、スケーリングするため、Amazon SageMakerはデプロイメントのオーバーヘッドを削減します。SageMaker MMEを使用して複数のモデルをホストするコードサンプルは、GitHubで入手できます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





