この脳AIの研究では、安定した拡散を用いて脳波から画像を再現します
In this brain AI research, images are reproduced from brain waves using stable diffusion.


人間の視覚システムと似たように、世界を見て認識する人工システムを構築することは、コンピュータビジョンの重要な目標です。 人工ネットワークのアーキテクチャの特徴を生物学的脳の潜在的表現と比較することで、最近の人口脳活動測定の進歩と深層ニューラルネットワークモデルの実装と設計の改善により、脳活動から視覚画像を再構築することが可能になりました。 たとえば、機能的磁気共鳴イメージング(fMRI)によって検出される脳活動のようなものです。 これは魅力的ですが、脳の基礎となる表現はほとんどわかっておらず、脳データのサンプルサイズが通常小さいため、困難な問題です。
近年の学術研究では、教師なし学習や生成的対抗ネットワーク(GAN)、自己教師あり学習などの深層学習モデルや技術が、これらの課題に取り組むために使用されています。 ただし、これらの試みは、fMRI実験で使用される特定の刺激に対して微調整するか、fMRIデータを使用して新しい生成モデルをトレーニングする必要があります。 これらの試みは、脳科学データの量が少ないことと、複雑な生成モデルの構築に関連する複数の困難により、ピクセルごとの信頼性や意味の信頼性において非常に制約されたパフォーマンスを示しました。
拡散モデル、特に計算資源をあまり必要としない潜在的拡散モデルは、最近のGANの代替手段です。 しかし、LDMはまだ比較的新しいため、内部でどのように機能するかを完全に理解することは困難です。
- 「UBCカナダの研究者が、都市ドライバーに最も安全な経路をマッピングする新しいAIアルゴリズムを紹介」
- 「AIの画像をどのように保存すべきか?Googleの研究者がスコアベースの生成モデルを使用した画像圧縮方法を提案」
- 研究者たちは、ビデオ記録を使用して、鳥の姿勢を3Dで追跡するための新しいマーカーレスAIメソッドを開発しました
大阪大学とCiNetの研究チームは、fMRI信号から視覚画像を再構築するためのLDMであるStable Diffusionを使用して、上記で述べた問題に取り組む試みを行いました。 彼らは、複雑な深層学習モデルのトレーニングや調整の必要性を排除し、高解像度で高い意味の信頼性を持つ画像を再構築することができる直感的なフレームワークを提案しました。

この調査で著者が使用したデータセットは、ナチュラルシーンデータセット(NSD)であり、各被験者が10,000枚の画像の3回のリピートを見た間に収集されたfMRIスキャナからのデータを提供しています。
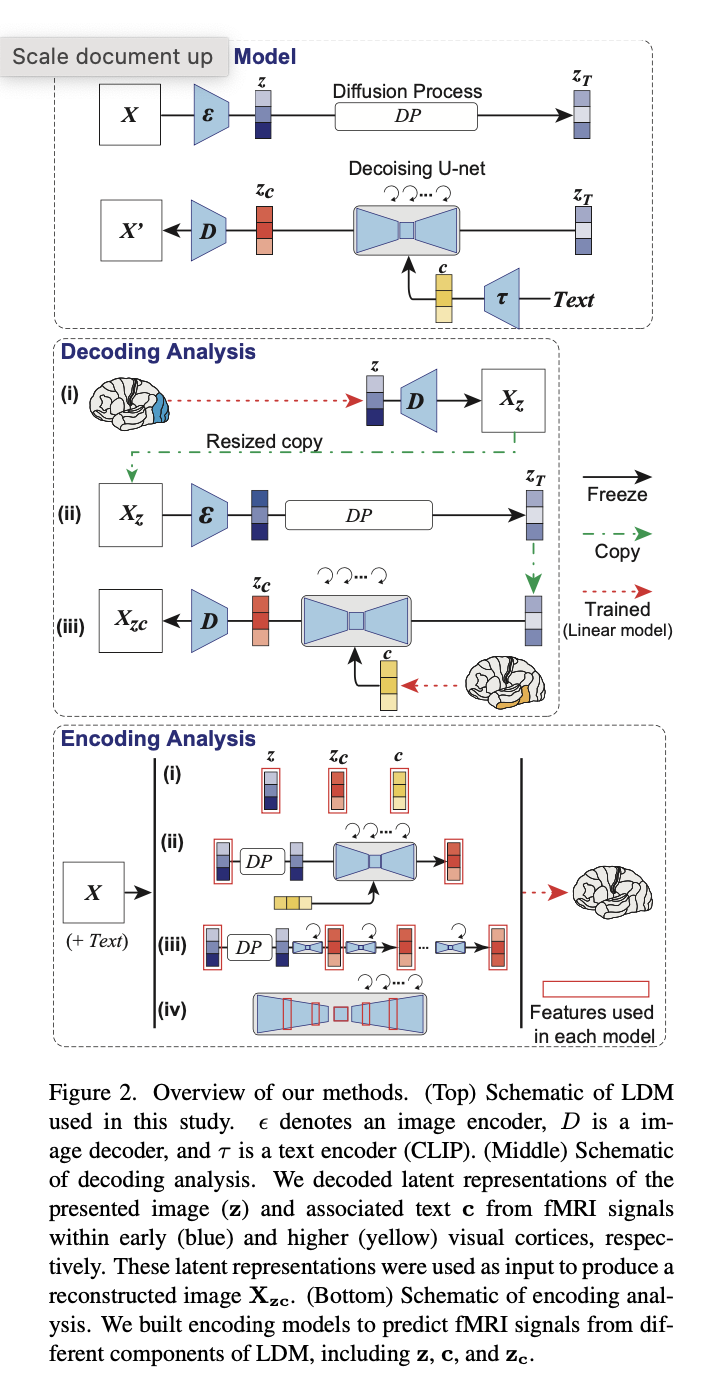
まず、著者たちはLatent Diffusion Modelを使用してテキストから画像を作成しました。上の図(上部)では、zは生成された潜在表現であり、cは画像を説明するテキストの潜在表現であり、zcはオートエンコーダによって圧縮された元の画像の潜在表現と定義されています。
デコーディングモデルを分析するために、著者たちは3つのステップに従いました(上の図、中央)。まず、彼らは初期の視覚皮質(青)内のfMRI信号から提示された画像Xの潜在表現zを予測しました。 zはその後、デコーダによって粗い復号化画像Xzを生成するために処理され、次に拡散プロセスを経てエンコードされました。最後に、ノイズのある画像には、高次視覚皮質(黄色)内のfMRI信号からの復号化された潜在テキスト表現cが追加され、zcが作成されました。 zcから、デコーディングモジュールが最終的な再構築画像Xzcを生成しました。このプロセスに必要なトレーニングは、fMRI信号をLDMコンポーネントzc、z、およびcに線形にマッピングすることだけであることを強調しておくことが重要です。
zc、z、およびcから始めると、著者たちはエンコーディング分析を実施し、それらを脳活動にマッピングすることでLDMの内部動作を解釈しました(上の図、下部)。表現から画像を再構築した結果は以下の通りです。

単にzを使用して再作成された画像は、元の画像と視覚的な一貫性を持っていましたが、その意味的な価値は失われました。一方、cを使用して部分的に再構築された画像は、意味的な忠実度が高いが視覚的に不一致な画像を生成しました。zcを使用して回復された画像が高解像度の画像を作成し、意味的な忠実度も高いことで、この方法の妥当性が示されました。
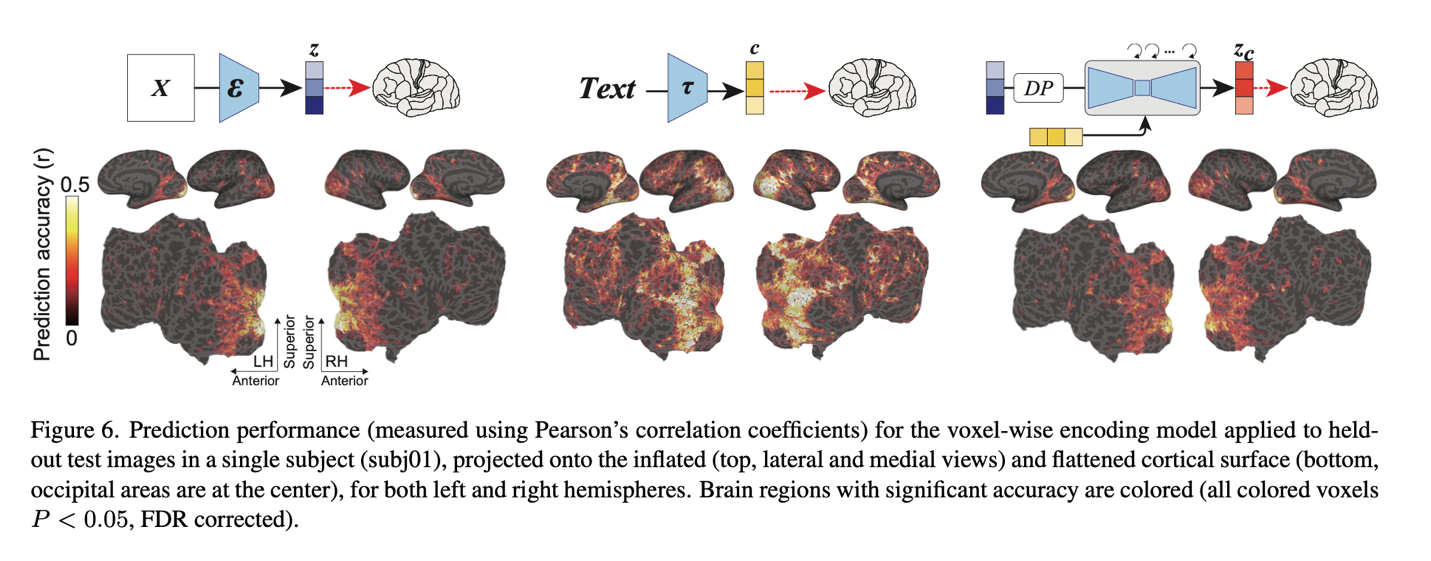
脳の最終解析では、DMモデルに関する新しい情報が明らかになりました。脳の後ろにある視覚皮質では、全ての3つの要素が優れた予測性能を達成しました。特に、zは視覚皮質の後ろにある初期視覚皮質で強力な予測性能を提供しました。また、上部視覚皮質(視覚皮質の前部)でも強力な予測値を示しましたが、他の領域ではより小さな値でした。一方、上部視覚皮質では、cが最も優れた予測性能を示しました。
論文とプロジェクトページをチェックしてください。この研究に関しては、このプロジェクトの研究者に全てのクレジットがあります。また、最新のAI研究ニュース、素晴らしいAIプロジェクトなどを共有している26k+ ML SubReddit、Discordチャンネル、メールニュースレターにもぜひ参加してください。
Tensorleapの解釈性プラットフォームでディープラーニングの秘密を解き放つ
この脳AI研究は、安定した拡散によって脳波から画像を再現します。MarkTechPostで最初に表示された記事です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- スタンフォード大学の研究者が、言語モデルの事前トレーニングのための拡張可能な二次最適化手法であるSophiaを紹介しました
- このPythonライブラリ「Imitation」は、PyTorchでの模倣と報酬学習アルゴリズムのオープンソース実装を提供します
- 「Ph.D.学生や研究者向けの無料オンラインコース10選」
- サムスンのAI研究者が、ニューラルヘアカットを紹介しましたこれは、ビデオや画像から人間の髪の毛のストランドベースのジオメトリを再構築するための新しいAI手法です
- 「サリー大学の研究者が開発した新しいソフトウェアは、AIが実際にどれだけの情報を知っているかを検証することができます」
- 新しいAIの研究は、事前学習済みおよび指示微調整モデルのゼロショットタスクの一般化性能を改善するために、コンテキスト内の指導学習(ICIL)がどのように機能するかを説明しています
- 「スタンフォード大学の新しいAI研究は、言語モデルにおける過信と不確実性の表現の役割を説明します」