AWS Inferentia2は、AWS Inferentia1をベースにしており、スループットが4倍に向上し、レイテンシが10倍低減されています
'AWS Inferentia2 improves throughput by 4 times and reduces latency by 10 times, based on AWS Inferentia1.'
機械学習(ML)モデルのサイズ、つまり大規模言語モデル(LLMs)とファウンデーションモデル(FMs)は、年々急速に増加しており、これらのモデルは特に生成AIにおいてより高速かつ強力なアクセラレータが必要です。AWS Inferentia2は、LLMsと生成AI推論のコストを低減しながら、より高いパフォーマンスを提供するために、グラウンドアップで設計されました。
本記事では、AWS Inferentia2の第2世代が、AWS Inferentia1で導入された機能に基づいて構築され、LLMsとFMsの展開と実行の独自の要求を満たす方法を示します。
2019年に発売された目的別アクセラレータの第1世代であるAWS Inferentiaは、ディープラーニング推論を加速するために最適化されています。AWS Inferentiaにより、MLユーザーは推論コストを削減し、予測スループットとレイテンシーを改善することができました。AWS Inferentia1では、類似の推論最適化Amazon Elastic Compute Cloud(Amazon EC2)インスタンスと比較して、最大2.3倍のスループット向上と最大70%の推論コスト削減が実現されました。
新しいAmazon EC2 Inf2インスタンスで紹介され、Amazon SageMakerでサポートされているAWS Inferentia2は、大規模生成AI推論に最適化され、アクセラレータ間の高速で低レイテンシーな接続を備えたAWSの最初の推論専用インスタンスです。
今すぐAWS Inferentia2を使用して、高価なトレーニングインスタンスを必要とせずに、単一のInf2インスタンス上で複数のアクセラレータを使って1750億パラメータモデルを推論効率的に展開することができます。これまで、大規模なモデルを持っていたお客様は、トレーニングに使用するインスタンスしか使用できなかったため、これはリソースの浪費でした。なぜなら、より高価でエネルギーを消費し、ワークロードが利用可能なすべてのリソース(より高速なネットワーキングやストレージなど)を活用していないためです。AWS Inferentia2を使用すると、AWS Inferentia1と比較して4倍のスループット向上と最大10倍のレイテンシー低減が実現できます。また、AWS Inferentiaの第2世代には、より多くのデータ型、カスタム演算子、ダイナミックテンソルなどの強化サポートが追加されています。
AWS Inferentia2は、AWS Inferentia1よりも4倍のメモリ容量、16.4倍のメモリ帯域幅を持ち、複数のアクセラレータをまたいで大規模なモデルを分割するためのネイティブサポートを提供しています。アクセラレータは、NeuronLinkおよびNeuron Collective Communicationを使用して、アクセラレータ間またはアクセラレータとネットワークアダプター間のデータ転送速度を最大化します。AWS Inferentia2は、複数のアクセラレータにシャーディングが必要な大規模なモデルに適していますが、小規模なモデルに対しては、AWS Inferentia1は代替手段と比較してより優れた価格性能を提供します。
アーキテクチャの進化
世代間でAWS Inferentiaを比較するために、AWS Inferentia1のアーキテクチャを見てみましょう。以下の図に示すように、各チップには4つのNeuronCores v1があります。

チップあたりの仕様:
- コンピュート – 4つのコアで合計128 INT8 TOPS、64FP16/BF16 TFLOPS
- メモリ – すべての4つのコアで共有されるDRAM 8 GB(50 GB/secの帯域幅)
- NeuronLink – 2つ以上のコアでモデルをシャーディングするためのリンク
AWS Inferentia2がどのように構成されるか見てみましょう。各AWS Inferentia2チップには、NeuronCore-v2アーキテクチャに基づく2つのアップグレードされたコアがあります。AWS Inferentia1と同様に、各NeuronCoreで異なるモデルを実行するか、複数のコアを組み合わせて大きなモデルをシャーディングできます。
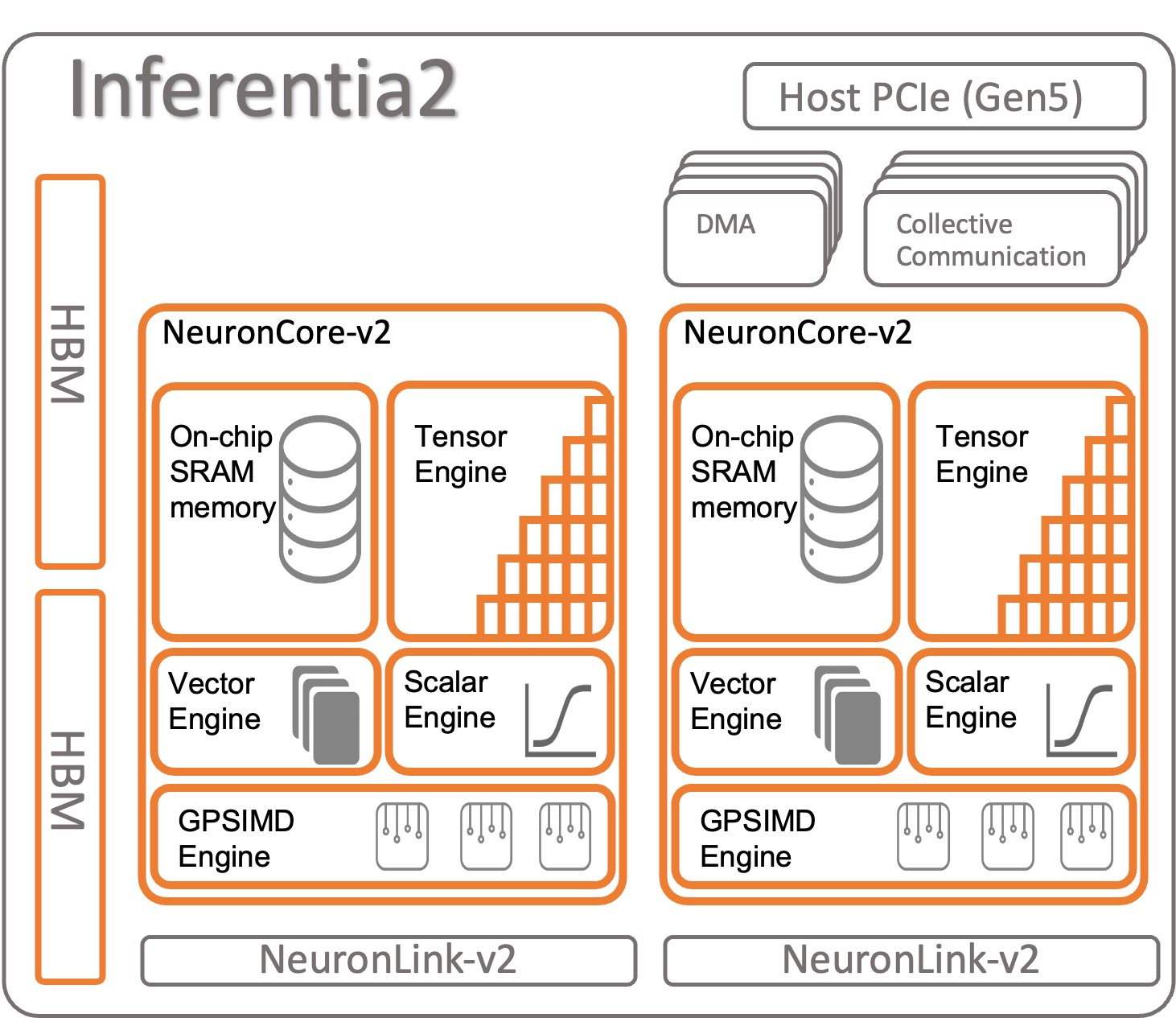
チップあたりの仕様:
- コンピュート – 2つのコアで合計380 INT8 TOPS、190 FP16/BF16/cFP8/TF32 TFLOPS、47.5 FP32 TFLOPS
- メモリ – 両方のコアで共有される32 GBのHBM
- NeuronLink – 2つ以上のコアでモデルをシャーディングするためのデバイスあたり384 GB/secのリンク
NeuronCore-v2は、4つの独立したエンジンを備えたモジュラーデザインを持っています:
- ScalarEngine(v1より3倍高速) – 浮動小数点数(BF16 / FP16)に作用する-1600 FLOPS
- VectorEngine(v1より10倍高速) – 数値のベクトルに作用し、正規化、プーリングなどの計算に単一の操作を行います。
- TensorEngine(v1より6倍高速) – Conv、Reshape、Transposeなどのテンソル計算を実行します。
- GPSIMD-Engine – 8つの完全にプログラム可能な512ビット幅の汎用プロセッサを備えており、標準のPyTorchカスタムC ++オペレータAPIを使用してカスタムオペレータを作成できます。これはNeuronCore-v2で導入された新機能です。
AWS Inferentia2 NeuronCore-v2は、より高速かつ最適化されています。また、ResNet 50などの単純なモデルから、GPT-3(1750億パラメーター)などの数十億のパラメーターを持つ大規模な言語モデルや基礎モデルなど、さまざまなタイプやサイズのモデルを加速できます。 AWS Inferentia2は、AWS Inferentia1と比較して、より大きく、より高速な内部メモリを持っています。次の表に示すように。
| チップ | ニューロンコア | メモリタイプ | メモリサイズ | メモリバンド幅 |
| AWS Inferentia | x4(v1) | DDR4 | 8GB | 50GB/S |
| AWS Inferentia 2 | x2(v2) | HBM | 32GB | 820GB/S |
AWS Inferentia2にあるメモリは、High-Bandwidth Memory(HBM)タイプです。各AWS Inferentia2チップに32 GBがあり、NeuronLink(デバイス間接続)を使用して他のチップと組み合わせて非常に大きなモデルを分散させることができます。たとえば、inf2.48xlargeには、合計384 GBの加速メモリを持つ12個のAWS Inferentia2アクセラレータがあります。 AWS Inferentia2メモリの速度は、前の表に示されているように、AWS Inferentia1の16.4倍速いです。
その他の機能
AWS Inferentia2には、以下の追加機能があります。
- ハードウェアサポート – cFP8(新しい、設定可能なFP8)、FP16、BF16、TF32、FP32、INT8、INT16、INT32。詳細については、データタイプを参照してください。
- レイジーTensor推論 – 後でこの記事でレイジーTensor推論について説明します。
- カスタムオペレータ – 開発者は、カスタムC ++オペレータのプログラミングインターフェースを使用して、カスタムオペレータを使用できます。カスタムオペレータは、Tensor Factory Functionsで利用可能な低レベルのプリミティブで構成され、GPSIMD-Engineで加速されます。
- 制御フロー(近日公開) – これは、モデル内でネイティブプログラミング言語の制御フローを使用して、データを前処理して後処理するために使用されます。
- ダイナミックシェイプ(近日公開) – これは、モデルが内部レイヤーの出力のサイズや形状を動的に変更する場合に役立ちます。たとえば:入力データに基づいて出力テンソルのサイズまたは形状を縮小するフィルター。
AWS Inferentia1およびAWS Inferentia2でのモデルの加速
AWS Neuron SDKは、モデルのコンパイルと実行に使用されます。それはPyTorchとTensorFlowとネイティブに統合されています。そのため、追加のツールを実行する必要はありません。これらのMLフレームワークのいずれかで書かれた元のコードを使用し、数行のコード変更でAWS Inferentiaを使用できます。
今回は、PyTorchを使用してAWS Inferentia1およびAWS Inferentia2でモデルをコンパイルおよび実行する方法を見ていきましょう。
torchvisionから事前学習済みモデル(ResNet50)を読み込む
事前学習済みモデルを読み込み、1回実行して暖機運転を行います:
import torch
import torchvision
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
x = torch.rand(1,3,224,224).float().cpu() # ダミー入力
y = model(x) # モデルの暖機運転Inferentia1で加速モデルをトレースおよびデプロイする
モデルをAWS Inferentiaにトレースするには、torch_neuronをインポートしてトレース関数を呼び出します。モデルがPyTorch Jitトレース可能である必要があることに注意してください。
トレースプロセスの最後に、モデルを通常のPyTorchモデルとして保存します。モデルを1回コンパイルし、必要に応じて何度でも読み込み直します。Neuron SDKランタイムはすでにPyTorchに統合されており、オペレータを自動的にAWS Inferentia1チップに送信してモデルを加速します。
推論コードでは、常に統合ランタイムをアクティブにするためにtorch_neuronをインポートする必要があります。
モデルを最適化する方法をカスタマイズするために、コンパイラに追加のパラメータを渡したり、ニューロンパイプラインコアなどの特別な機能を有効にしたりすることができます。モデルを複数のコアに分割してスループットを向上させることができます。
import torch_neuron
# NeuronSDKを使用してモデルをトレースする
neuron_model = torch_neuron.trace(model,x) # Inferentiaにモデルをトレース
# 保存して将来のために使用する
neuron_model.save('neuron_resnet50.pt')
# 次回からはモデルをトレースする必要はありません
# ただ、AWS NeuronSDKは自動的にInferentiaに送信します。
neuron_model = torch.jit.load('neuron_resnet50.pt')
# Inferentiaで加速された推論
y = neuron_model(x)Inferentia2で加速モデルをトレースおよびデプロイする
AWS Inferentia2では、プロセスは同様です。唯一の違いは、インポートするパッケージがxで終わることです:torch_neuronx 。Neuron SDKは、透過的にモデルのコンパイルと実行を処理します。また、コンパイラに追加のパラメータを渡して操作を微調整したり、特定の機能を有効化することもできます。
import torch_neuronx
# NeuronSDKを使用してモデルをトレースする
neuron_model = torch_neuronx.trace(model,x) # Inferentiaにモデルをトレース
# 保存して将来のために使用する
neuron_model.save('neuron_resnet50.pt')
# 次回からはモデルをトレースする必要はありません
# ただ、NeuronSDKは自動的にInferentiaに送信します。
neuron_model = torch.jit.load('neuron_resnet50.pt')
# Inferentiaで加速された推論
y = neuron_model(x)AWS Inferentia2では、Lazy Tensor推論と呼ばれる2番目のモデル実行方法も提供されています。このモードでは、モデルをトレースしたり、コンパイルしたりする必要はありません。代わりに、コンパイラはコードを実行するたびに実行されます。トレースモードと比較して、多くの利点を持っているため、本番では推奨されていません。ただし、モデルの開発中である場合、テストをより速く実行する必要がある場合は、Lazy Tensor推論が適しています。次に、Lazy Tensorを使用してモデルをコンパイルおよび実行する方法を示します。
import torch
import torchvision
import torch_neuronx
import torch_xla.core.xla_model as xm
device = xm.xla_device() # XLAデバイスを作成する
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
model.to(device)
x = torch.rand((1,3,224,224), device=device) # ダミー入力
with torch.no_grad():
y = model(x)
xm.mark_step() # コンパイルはここで実行されますAWS Inferentia2に慣れたら、PyTorchまたはTensorflowを始めて、開発環境を設定し、チュートリアルや例を実行する方法を学びましょう。また、AWS Neuron Samples GitHubリポジトリを確認して、Inf2、Inf1、Trn1で実行するための複数の例を見つけることができます。
AWS Inferentia1 と AWS Inferentia2 の機能比較の要約
AWS Inferentia2 コンパイラは XLA ベースであり、AWS は OpenXLA イニシアチブの一部です。これは AWS Inferentia1 との最大の違いであり、PyTorch、TensorFlow、JAX にはネイティブの XLA 統合があるため、重要です。XLA は、グラフを最適化して結果を単一のカーネル起動で計算するため、多くのパフォーマンス改善をもたらします。連続したテンソル操作を融合し、モデルを AWS Inferentia2 上で実行するための最適なマシンコードを出力します。AWS Inferentia2 の他の部分も改善されましたが、モデルのトレースと実行をできるだけシンプルなユーザーエクスペリエンスに保ちながらです。以下の表は、コンパイラとランタイムの両方で利用可能な機能を示しています。
| 機能 | torch-neuron | torch-neuronx |
| Tensorboard | Yes | Yes |
| サポートされるインスタンス | Inf1 | Inf2 & Trn1 |
| 推論サポート | Yes | Yes |
| トレーニングサポート | No | Yes |
| アーキテクチャ | NeuronCore-v1 | NeuronCore-v2 |
| トレース API | torch_neuron.trace() | torch_neuronx.trace() |
| 分散推論 | NeuronCore Pipeline | Collective Communications |
| IR | GraphDef | HLO |
| コンパイラ | neuron-cc | neuronx-cc |
| 監視 | neuron-monitor / monitor-top | neuron-monitor / monitor-top |
torch-neuron (Inf1) と torch-neuronx (Inf2 & Trn1) のより詳細な比較については、Comparison of torch-neuron (Inf1) versus torch-neuronx (Inf2 & Trn1) for Inference を参照してください。
モデルサービング
Inf2 にデプロイするモデルをトレースした後、さまざまなデプロイメントオプションがあります。リアルタイム予測やバッチ予測を異なる方法で実行できます。EC2 インスタンスは、Amazon Elastic Container Service(Amazon ECS)、Amazon Elastic Kubernetes Service(Amazon EKS)、および SageMaker など、Deep Learning Containers(DLC)を使用する他の AWS サービスとネイティブに統合されているため、Inf2 が利用可能です。
AWS Inferentia2 は、最も一般的なデプロイメントテクノロジーと互換性があります。AWS Inferentia2 を使用してモデルを展開するためのいくつかのオプションを以下に示します:
- SageMaker – データの準備、ML モデルの構築、トレーニング、デプロイを完全に管理するサービス
- TorchServe – PyTorch 統合デプロイメントメカニズム
- TensorFlow Serving – TensorFlow 統合デプロイメントメカニズム
- Deep Java Library – モデルの展開とトレーニングのためのオープンソース Java メカニズム
- Triton – モデル展開のための NVIDIA オープンソースサービス
ベンチマーク
AWS Inferentia2がAWS Inferentia1に対してもたらす改善点を示す以下の表。具体的には、レイテンシ(各アクセラレータを使用してモデルが予測を行う速度)、スループット(1秒あたりの推論数)、推論あたりのコスト(米ドル)を測定しています。ミリ秒単位でのレイテンシと米ドルでのコストが低いほど、より優れています。スループットが高いほど良いです。
このプロセスで2つのモデルが使用されました-両方とも大規模な言語モデル:ELECTRA large discriminatorとBERT large uncasedです。この実験で主に使用されたPyTorch(1.13.1)およびHugging Face transformers(v4.7.0)のライブラリはPython 3.8で実行されました。前のセクションからのコードを参考にしてバッチサイズ= 1および10のためにモデルをコンパイルした後、各モデルはウォームアップされました(コンテキストを初期化するために1回呼び出されました)そして、10回連続して呼び出されました。次の表は、この単純なベンチマークで収集された平均数を示しています。
- Electra large discriminator(334,092,288パラメータ〜593 MB)
- Bert large uncased(335,143,938パラメータ〜580 MB)
- OPT-66B(660億パラメータ〜124 GB)
| モデル名 | バッチサイズ | 文の長さ | レイテンシ(ms) | Inf2がInf1より改善された回数(x回) | スループット(1秒あたりの推論数) | 推論あたりのコスト(EC2 us-east-1)** | |||
| Inf1 | Inf2 | Inf1 | Inf2 | Inf1 | Inf2 | ||||
| ElectraLargeDiscriminator | 1 | 256 | 35.7 | 8.31 | 4.30 | 28.01 | 120.34 | $0.0000023 | $0.0000018 |
| ElectraLargeDiscriminator | 10 | 256 | 343.7 | 72.9 | 4.71 | 2.91 | 13.72 | $0.0000022 | $0.0000015 |
| BertLargeUncased | 1 | 128 | 28.2 | 3.1 | 9.10 | 35.46 | 322.58 | $0.0000018 | $0.0000007 |
| BertLargeUncased | 10 | 128 | 121.1 | 23.6 | 5.13 | 8.26 | 42.37 | $0.0000008 | $0.0000005 |
* このベンチマークでは、32のAMD Epyc 7313 CPUを搭載したc6a.8xlargeが使用されました。
** 2021年4月20日のus-east-1におけるEC2パブリック価格:inf2.xlarge:$0.7582/hr;inf1.xlarge:$0.228/hr。1つのバッチあたりの要素ごとのコストを考慮した推論あたりのコスト。 (推論あたりのコストは、モデル呼び出し/バッチサイズの総コストと同じです。)
トレーニングと推論のパフォーマンスの詳細については、Trn1 / Trn1n Performanceを参照してください。
結論
AWS Inferentia2は、深層学習モデルの推論のパフォーマンスを向上させ、コストを削減するために設計された強力なテクノロジーです。AWS Inferentia1よりも高性能で、最大4倍のスループット、最大10倍の低レイテンシ、および他の比較可能な推論に最適化されたEC2インスタンスよりも最大50%優れた性能/ワットを提供します。最終的に、より少ない支払いでより速いアプリケーションを実現し、持続可能性の目標を達成できます。
AWS Inferentia2への推論コードの移行は、簡単で直感的で、大規模言語モデルや生成AIの基盤モデルを含むさまざまなモデルをサポートしています。
開発環境を設定して、加速された深層学習プロジェクトを開始するには、AWS Neuron SDKドキュメントに従って始めることができます。始めるために、Hugging FaceはNeuronのサポートをOptimumライブラリに追加しました。Optimumは、より速いトレーニングと推論のためにモデルを最適化し、Inf2で実行するための多くの例題を用意しています。また、大規模言語モデル推論コンテナを使用してAWS Inferentia2に大規模言語モデルをデプロイすることに関するDeploy large language models on AWS Inferentia2 using large model inference containersを確認して、追加の例を参照することもできます。AWS Neuron Samples GitHubリポジトリも参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful






