郵便番号レベルでの地理空間データの操作
'郵便番号レベルの地理空間データ操作'
「ポイント」郵便番号と地域の国勢調査データの関連付け方法
一部の国では、郵便番号は地域ではなく、ポイントまたはルートとなっています。たとえば、カナダの郵便番号の最後の3桁は、一つの通りの片側または農村のルートに対応する場合があります。同様に、イギリスの郵便番号は「YO8 9UR」という形式の郵便番号です。これはロンドンの一つの建物ほど小さい場合もあります。5+4桁のアメリカの郵便番号では、最後の4桁は郵便配達ルート(つまり、一連の住所)を決定し、地域ではありません。一般的な認識とは異なり、アメリカの5桁の郵便番号も地域ではなく、通常、単一の郵便局から提供される5+4桁の郵便ルートの集合体です。
メートル法の生みの親であるフランスは非常に論理的です。フランスでは、郵便番号は地域に対応します。最後の2桁は区(arrondissement)に対応し、たとえば75008はパリの8区に対応し、本当に地域です。ただし、郵便物の配達ルートはおそらく最適ではないでしょう。
人々や店舗は住所を持っており、住所には関連する郵便番号がありますので、ほとんどの消費者データは郵便番号レベルで報告されます。地域のカバレッジ、市場シェアなどの計算を行うためには、郵便番号の地域範囲を特定する必要があります。これはフランスでは簡単ですが、郵便番号が郵便ルートであり地域ではない国では困難です。

郵便番号が郵便配達の住所であるため、イギリス/カナダ/アメリカを有効な郵便番号「地域」に分割するためには、無限に多くのポリゴンを描くことができます。これがイギリスの人口統計データが国立統計庁(ONS)によって郵便番号ではなく行政区域(州など)で公開される理由です。アメリカの国勢調査は「Zip code tabulation area」(ZCTA)レベルでデータを公開し、アメリカの選挙データは郡レベルで公開されています。イギリス/カナダ/アメリカのデータを扱う際には、住所(ポイント)と地域全体で収集された空間データの類似の組み合わせがよくあります。これらをどのように関連付けるのでしょうか?
例を挙げるために、この記事ではイギリスの郵便番号データと国勢調査データを結びつけます。
ダウンロードリンク
お急ぎの場合は、https://github.com/lakshmanok/lakblogs/tree/main/uk_postcode から分析結果をダウンロードできます。そこにはいくつかのCSVファイルがあり、必要なデータが含まれています。
ukpopulation.csv.gzには、以下の列があります:
postcode,latitude,longitude,area_code,area_name,all_persons,females,malesukpostcodes.csv.gzには、ワールド座標系(WKT)形式で各郵便番号のポリゴンが1つの追加列として含まれています:
postcode,latitude,longitude,area_code,area_name,all_persons,females,males,geometry_wktデータまたはコードの使用は自己責任で行ってください。これらは「現状のまま」で提供され、明示または黙示の保証なしに配布されます。
この記事では、GitHubリポジトリ内のデータセットの作成方法をステップバイステップで説明します。ノートブックuk_postcodes.ipynbを使用して一緒に進めることができます。
生データ
私たちは、以下の3つのソースから始めます。これらのデータはUK Open Government Licenseの下で公開されています:
- Free Map Toolsは、各郵便番号の重心の緯度と経度が含まれたダウンロード可能なファイルを提供しています。これだけでは空間分析などはできませんが、良い出発点です。
- ONSは、「County Durham」などの地域の国勢調査データを公開しています。ただし、これらは郵便番号ではありません。通常、ワード、県、または地域レベルのデータです。
- イギリス統計局は、各郵便番号に関連する地域を明示的に特定しています。各郵便番号は、異なる目的と解像度のために定義された異なる地域に存在します。これには、教区、ワード、県、および地域などが含まれます。完全性のために、使用可能なすべての他の関連付けを以下に示します(空間データセットに応じて、他の列が必要な場合があります):
pcd、pcd2、pcds、dointr、doterm、oscty、ced、oslaua、osward、parish、usertype、oseast1m、osnrth1m、osgrdind、oshlthau、nhser、ctry、rgn、streg、pcon、eer、teclec、ttwa、pct、itl、statsward、oa01、casward、park、lsoa01、msoa01、ur01ind、oac01、oa11、lsoa11、msoa11、wz11、sicbl、bua11、buasd11、ru11ind、oac11、lat、long、lep1、lep2、pfa、imd、calncv、icb、oa21、lsoa21、msoa21私のノートブックは、wgetを使用してデータファイルをダウンロードします:
mkdir -p indatacd indataif [ ! -f census2021.xlsx ]; then wget -O census2021.xlsx https://www.ons.gov.uk/file?uri=/peoplepopulationandcommunity/populationandmigration/populationestimates/datasets/populationandhouseholdestimatesenglandandwalescensus2021/census2021/census2021firstresultsenglandwales1.xlsxfiデータの読み取り
PandasへのCSVの直接読み込みは簡単です:
import pandas as pdpd.read_csv(POSTCODES_CSV)これにより、すべての郵便番号の重心緯度経度が得られます:
ExcelファイルをPandasに直接読み込むための多くのパッケージがありますが、SQLを使用して3つのデータセットを結合するために後でノートブックで使用するため、DuckDBを使用することにしました:
import duckdbconn = duckdb.connect()ukpop = conn.execute(f"""install spatial;load spatial;SELECT * FROMst_read('{POPULATION_XLS}', layer='P01')""").df()このExcelファイルには7行のヘッダ情報があり、削除することができます。また、列名を意味のある変数に変更します:
ukpop = ukpop.drop(range(0,7), axis=0).rename(columns={ 'Field1': 'area_code', 'Field2': 'area_name', 'Field3': 'all_persons', 'Field4': 'females', 'Field5': 'males'})これはP01という名前のシートでした。P04シートには人口密度情報がありますが、面積コードに均等に分布していないため、有用ではありません。各郵便番号の人口を導出します。
これをCSVファイルに書き出して、DuckDBから簡単に読み込むことができるようにします。
ukpop.to_csv("temp/ukpop.csv", index=False)同様に、イギリス統計局のファイルから必要な列を抽出して、CSVファイルに書き込みます:
onspd = pd.read_csv(ONSPD_CSV)onspd = onspd[['pcd', 'oslaua', 'osward', 'parish']]onspd.to_csv("temp/onspd.csv", index=False)データの関連付け
さて、3つの準備されたデータセットを結合して、すべての郵便番号の人口密度を取得するためにDuckDBを使用できます。なぜDuckDBを使用するのですか?Pandasで結合することもできますが、SQLの方がはるかに読みやすいと考えています。また、これは新しい注目を浴びているものを使用する口実でもあります。
データセットをDuckDBに最初にread_csv_autoを使用して読み込みます。次に、郵便番号が含まれるワード、教区、郡を検索し、人口密度データが報告されるエリア(教区、ワード、または郡)を見つけます:
/* pcd,oslaua,osward,parish */WITH onspd AS ( SELECT * FROM read_csv_auto('temp/onspd.csv', header=True)),/* area_code,area_name,all_persons,females,males */ukpop AS ( SELECT * FROM read_csv_auto('temp/ukpop.csv', header=True)),/* id,postcode,latitude,longitude */postcodes AS ( SELECT * FROM read_csv_auto('indata/ukpostcodes.csv', header=True)),/* postcode, area_code */postcode_to_areacode AS ( SELECT pcd AS postcode, ANY_VALUE(area_code) as area_code FROM onspd JOIN ukpop ON (area_code = oslaua OR area_code = osward OR area_code = parish) GROUP BY pcd)SELECT postcode, latitude, longitude, /* from postcodes */ area_code, area_name, /* from ukpop */ all_persons,females,males /* from ukpop, but has to be spatially corrected */FROM postcode_to_areacodeJOIN postcodes USING (postcode)JOIN ukpop USING (area_code)空間量は、郵便番号ではなく全体のエリアに対応するスカラーです。これらは郵便番号ごとに分割する必要があります。
郵便番号間でエリアの数量を分割する
all_persons、females、males はすべて、特定の郵便番号ではなく全体のエリアに対応します。郵便番号のエリアに比例して分割することもできますが、郵便番号に合わせることができる無限に多くのポリゴンがあり、また後で見るように、公園や湖の近くの郵便番号の面積は少し曖昧です。したがって、私たちは単純な方法を使って、一つの一意な回答を得ることができるようにします – エリア内のすべての郵便番号でスカラー値を均等に分割します!これは思われるほど奇妙ではありません – 高密度な近隣では、より多くの郵便番号がありますので、郵便番号に均等に分割することは、人口密度に比例したスカラー量の分布に相当します。
npostcodes = ukpop.groupby('area_code')['postcode'].count()for col in ['females', 'males', 'all_persons']: ukpop[col] = ukpop.apply(lambda row: row[col]/npostcodes[row['area_code']], axis=1)この時点で、各郵便番号の数量が得られます – これが必要な関連付けです:
では、書き出しましょう:
ukpop.to_csv("ukpopulation.csv", index=False)郵便番号の面積範囲
多くの分析では、ポイントではなくエリアとしての郵便番号が必要になる場合があります。イギリスを分割して、ポリゴンごとに1つの郵便番号の重心が存在するようにするために、使用できるポリゴンは無限に多く存在しますが、”最良の”ポリゴンの概念が存在します。それはボロノイ分割です。この分割では、任意の点がそれに最も近い郵便番号に属するようにエリアが分割されます:

これを計算するために、scipyを使用することができます:
import numpy as npfrom scipy.spatial import Voronoi, voronoi_plot_2dpoints = df[['latitude', 'longitude']].to_numpy()vor = Voronoi(points)ここでは、エリアが小さすぎて、緯度と経度から計算される測地距離とユークリッド距離にはほとんど差がないと仮定しています。イギリスの郵便番号は十分に小さいため、これは当てはまります。
結果は、各ポイントに対して頂点の集合から成る領域があるように整理されています。次のコードを使用して、各ポイントのためのWKTポリゴン文字列を作成できます:
def make_polygon(point_no): region_no = vor.point_region[point_no] region = vor.regions[region_no] if len(region) >= 3: # リングを閉じる closed_region = region.copy() closed_region.append(closed_region[0]) # ポイントのWKTを作成する polygon = "POLYGON ((" + ','.join([ f"{vor.vertices[v][1]} {vor.vertices[v][0]}" for v in closed_region]) + "))" return polygon else: return None以下は例の結果です:
POLYGON ((-0.32491691953979235 51.7393550489536,-0.32527234008402217 51.73948967705648,-0.32515738641624575 51.73987124225542,-0.3241646650618929 51.74087626616231,-0.3215663358407994 51.742660660928614,-0.32145633473723817 51.742228570262824,-0.32491691953979235 51.7393550489536))GeoDataFrameを作成し、郵便番号のサブセットをプロットすることができます:
import geopandas as gpdfrom shapely import wktdf['geometry'] = gpd.GeoSeries.from_wkt(df['geometry_wkt'])gdf = gpd.GeoDataFrame(df, geometry='geometry')gdf[gdf['area_name'] == 'St Albans'].plot()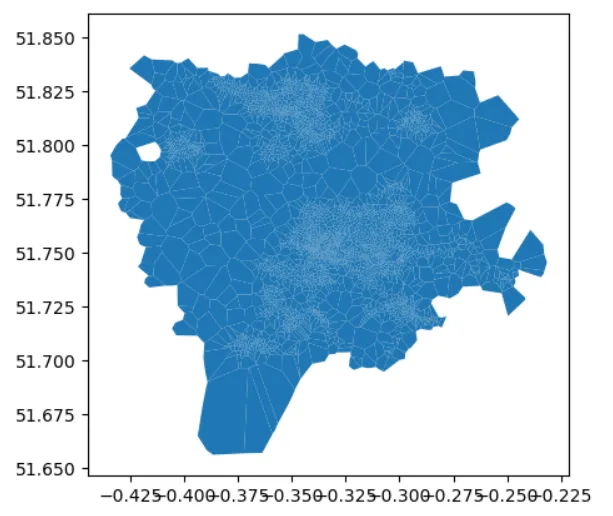
こちらがバーミンガムです:
gdf[gdf['area_name'] == 'バーミンガム'].plot()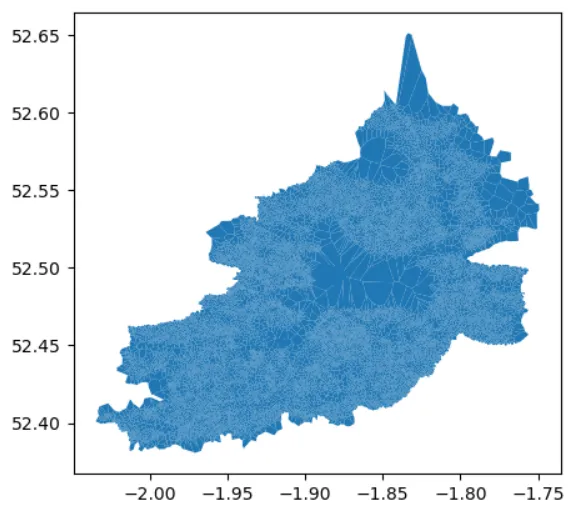
人口の少ない地域
上部の角や中央部の大きな青い領域に注目してください。何が起こっているのでしょうか?Googleマップでバーミンガムを見てみましょう:
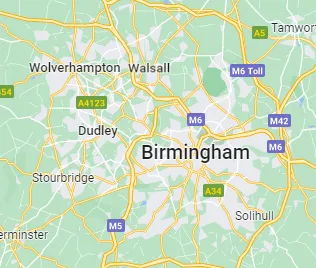
公園の領域に注目してください。ロイヤルメールはそこには配達しない必要がありません。そのため、その地域には郵便番号がありません。そのため、近くの郵便番号がその地域に「拡張」されます。これにより、空間計算に問題が生じます。これらの郵便番号は実際のサイズよりも大きく見えることになります。
これを修正するために、ある程度のヒューリスティックな手法を採用します。イギリスを0.01×0.01(おおよそ1平方キロメートル)の解像度のグリッドセルに分割し、郵便番号が存在しないグリッドセルを見つけます:
GRIDRES = 0.01
min_lat, max_lat = np.round(min(df['latitude']), 2) - GRIDRES, max(df['latitude']) + GRIDRES
min_lon, max_lon = np.round(min(df['longitude']), 2) - GRIDRES, max(df['longitude']) + GRIDRES
print(min_lat, max_lat, min_lon, max_lon)
npostcodes = np.zeros([ int(1+(max_lat-min_lat)/GRIDRES), int(1+(max_lon-min_lon)/GRIDRES) ])
for point in points:
latno = int((point[0] - min_lat)/GRIDRES)
lonno = int((point[1] - min_lon)/GRIDRES)
npostcodes[latno, lonno] += 1
unpop = []
for latno in range(len(npostcodes)):
for lonno in range(len(npostcodes[latno])):
if npostcodes[latno][lonno] == 0:
# ここには誰も住んでいません。
# この場所のために郵便番号を作成します。
# 郵便番号 緯度 経度 エリアコード エリア名 1平方キロメートルあたりの人口
unpop.append({
'postcode': f'UNPOP {latno}x{lonno}',
'latitude': min_lat + latno * 0.01,
'longitude': min_lon + lonno * 0.01,
'all_persons': 0
})このような人口の少ないグリッドセルの中心に偽の郵便番号を作成し、それらに人口密度ゼロを割り当てます。これらの偽の郵便番号を実際の郵便番号に追加し、Voronoi解析を繰り返します:
df2 = pd.concat([df, pd.DataFrame.from_records(unpop)])
points = df2[['latitude', 'longitude']].to_numpy()
vor = Voronoi(points)
df2['geometry_wkt'] = [make_polygon(x) for x in range(len(vor.point_region))]
df2['geometry'] = gpd.GeoSeries.from_wkt(df2['geometry_wkt'])
gdf = gpd.GeoDataFrame(df2, geometry='geometry')これで、バーミンガムをプロットすると、より見栄えの良いものが得られます:
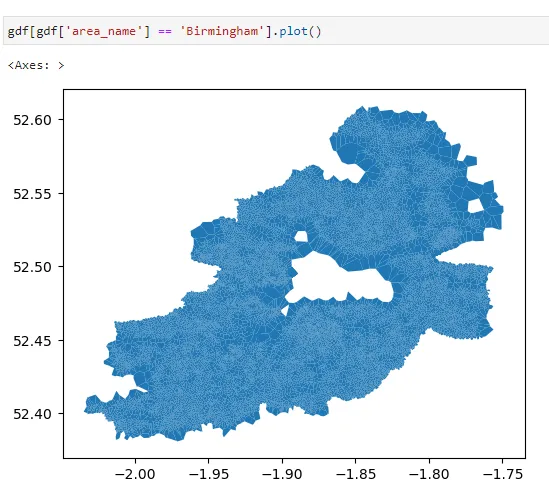
このデータフレームを第2のCSVファイルとして保存しました:
gdf.to_csv("ukpostcodes.csv", index=False)[オプション] BigQueryへの読み込み
CSVファイルをBigQueryに読み込み、それを使って空間解析を行うことができますが、まずBigQueryに最後の文字列列をジオメトリとして解析させ、郵便番号でデータをクラスタリングする方が良いでしょう:
CREATE OR REPLACE TABLE uk_public_data.postcode_popgeo2CLUSTER BY postcodeASSELECT * EXCEPT(geometry_wkt), SAFE.ST_GEOGFROMTEXT(geometry_wkt, make_valid=>TRUE) AS geometry,FROM uk_public_data.postcode_popgeoこれで、簡単にクエリを実行できます。例えば、郵便番号の面積にST_AREAを使用することができます:
SELECT COUNT(*) AS num_postcodes, SUM(ST_AREA(geometry))/1e6 AS total_area, SUM(all_persons) AS population, area_name FROM uk_public_data.postcode_popgeo2 GROUP BY area_name ORDER BY population DESC概要
空間解析では、単にポイントの位置だけでなく、面積が必要です。郵便番号がポイント/ルートである国では、郵便番号の多角形空間範囲を生成する方法は無限にあります。妥当なアプローチは、ボロノイ領域を使用して、それらの郵便番号を含む多角形を作成することです。ただし、そうすると、郵便局が郵便物を配達しない湖や公園周辺の非常に大きな多角形が生成されます。これを修正するために、国をグリッド化し、非人口のグリッドセルに人工的な郵便番号を作成します。この記事では、英国の場合にこれを行う方法を示しました。関連するノートブックは他の場所に適応することができます。
次のステップ
- 完全なコードはhttps://github.com/lakshmanok/lakblogs/blob/main/uk_postcode/uk_postcodes.ipynbで確認してください
- データはhttps://github.com/lakshmanok/lakblogs/tree/main/uk_postcodeからダウンロードしてください
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
