合成データは、機械学習のパフォーマンスを向上させることができるのか?
Can synthetic data improve the performance of machine learning?
不均衡データセット上でモデルのパフォーマンスを向上させるための合成データの能力の調査

背景 — 不均衡データセット
不均衡な分類問題は、商業的な機械学習のユースケースで頻繁に発生します。それは、チャーン予測、詐欺検知、医療診断、スパム検出などの場面で遭遇する可能性があります。これらのシナリオでは、私たちが検出しようとする対象は少数派のクラスに属することがあり、データ内で非常に少数派になることがあります。不均衡データセット上でモデルのパフォーマンスを向上させるためには、いくつかの手法が提案されています:
- アンダーサンプリング:多数派クラスをランダムにアンダーサンプリングしてよりバランスの取れたトレーニングデータセットを作成する。
- オーバーサンプリング:少数派クラスをランダムにオーバーサンプリングしてバランスの取れたトレーニングデータセットを作成する。
- 重み付け損失:少数派クラスに関連する損失関数に重みを割り当てる。
- 合成データ:生成的なAIを使用して少数派クラスの高品質な合成データサンプルを作成する。
この記事では、合成データでモデルをトレーニングすることが、分類器のパフォーマンスを向上させる他の手法を上回ることを示しています。
データセット
データはKaggleから取得されており、284,807件のクレジットカードの取引が含まれており、そのうち492件(0.172%)が詐欺とラベル付けされています。データは商用および非商用の使用のためにOpen Data Commonsライセンスの下で利用可能です。
興味がある読者のために、Kaggleはデータに関するより詳細な情報や基本的な記述統計を提供しています。
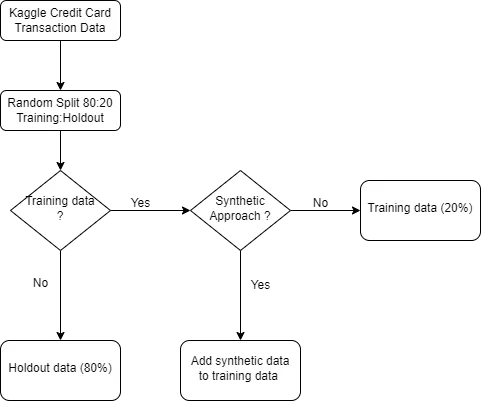
このKaggleのデータセットから、トレーニングセットとホールドアウトセットの2つのサブセットを作成します。トレーニングセットは全データの80%を占め、そのアプローチを探索する際には合成生成されたサンプルも含まれます。ホールドアウトセットは元のデータの20%を占め、合成サンプルは除外されます。
モデル
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- JavaScriptを使用してOracleデータベース内からHugging Face AIを呼び出す方法
- LangChainを使用したLLMパワードアプリケーションの構築
- LangChain:LLMがあなたのコードとやり取りできるようにします
- ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
- PythonのAsyncioをAiomultiprocessで強化しましょう:包括的なガイド
- 私が通常のRDBMSをベクトルデータベースに変換して埋め込みを保存する方法
- UCLAの研究者が、最新の気候データと機械学習モデルに簡単で標準化された方法でアクセスするためのPythonライブラリ「ClimateLearn」を開発しました
