QLoRAを使用して、Amazon SageMaker StudioノートブックでFalcon-40Bと他のLLMsをインタラクティブにチューニングしてください
使用して、Amazon SageMaker StudioノートブックでQLoRAと他のLLMsをインタラクティブにチューニングしてください
大規模な言語モデル(LLM)のファインチューニングにより、オープンソースの基礎モデルを調整して、特定のドメインタスクでのパフォーマンスを向上させることができます。この記事では、Amazon SageMakerノートブックを使用して、最新のオープンソースモデルをファインチューニングする利点について説明します。Hugging Faceのパラメータ効率の良いファインチューニング(PEFT)ライブラリと、bitsandbytesを通じた量子化技術を使用して、シングルノートブックインスタンスを使用して非常に大きなモデルの対話型ファインチューニングをサポートします。具体的には、Falcon-40Bを単一のml.g5.12xlargeインスタンス(4つのA10G GPU)を使用してファインチューニングする方法を示しますが、同じ戦略はp4d/p4deノートブックインスタンスでもさらに大きなモデルのチューニングにも適用できます。
通常、これらの非常に大きなモデルの完全精度の表現は、単一のGPUまたは複数のGPUにメモリに収まりません。このサイズのモデルでの対話型ノートブック環境をサポートするために、Quantized LLMs with Low-Rank Adapters(QLoRA)として知られる新しい技術を使用します。QLoRAは、LLMのメモリ使用量を削減しつつ、堅牢なパフォーマンスを維持する効率的なファインチューニング手法です。Hugging Faceと論文の著者は、TransformersとPEFTライブラリとの基本的な統合について詳細なブログ記事を公開しています。
ノートブックを使用してLLMをファインチューニングする
SageMakerには、データの探索と機械学習(ML)モデルの構築のためのフルマネージドノートブックを起動する2つのオプションがあります。最初のオプションは、Amazon SageMaker Studio内でアクセス可能な高速なスタートの共同作業ノートブックです。SageMaker Studioでは、SageMaker Studioでノートブックを迅速に起動し、基礎となる計算リソースを中断することなくダイアルアップまたはダウンすることができ、ノートブックをリアルタイムで共同編集・共同作業することもできます。ノートブックの作成に加えて、SageMaker Studioでは、SageMaker Studio内の単一の画面でモデルのビルド、トレーニング、デバッグ、トラッキング、デプロイ、モニタリングなど、すべてのML開発ステップを実行することができます。2番目のオプションは、SageMakerノートブックインスタンスであり、クラウド上でノートブックを実行する単一のフルマネージドMLコンピュートインスタンスであり、ノートブックの設定に対してより多くの制御を提供します。
この記事の残りの部分では、SageMaker Studioノートブックを使用します。なぜなら、SageMaker Studioの管理されたTensorBoard実験トラッキングを利用したいからです。ただし、例のコードで示されている同じコンセプトは、conda_pytorch_p310カーネルを使用するノートブックインスタンスでも機能します。なお、SageMaker StudioのAmazon Elastic File System(Amazon EFS)ボリュームは、LLMのモデルウェイトの大きさを考慮すると、あらかじめ指定されたAmazon Elastic Block Store(Amazon EBS)ボリュームサイズをプロビジョニングする必要がないため、便利です。
大規模なGPUインスタンスをバックエンドとするノートブックを使用すると、コールドスタートのコンテナ起動なしで迅速なプロトタイピングとデバッグが可能になります。ただし、余分なコストを避けるために、ノートブックインスタンスを使用した作業が終了したらシャットダウンする必要があります。ファインチューニングには、Amazon SageMaker JumpStartやSageMaker Hugging Faceコンテナなどの他のオプションも使用できますので、以下の投稿を参照して最適なオプションを選択することをお勧めします。
- Amazon SageMaker JumpStartを使用したファイナンシャルデータへの基礎モデルのドメイン適応ファインチューニング
- Hugging FaceとLoRAを使用した単一のAmazon SageMaker GPUでの大規模言語モデルのトレーニング
前提条件
SageMaker Studioを使用するのは初めての場合は、まずSageMakerドメインを作成する必要があります。また、このチュートリアルではオプションですが、実験トラッキングのために管理されたTensorBoardインスタンスも使用します。
さらに、対応するSageMaker Studio KernelGatewayアプリのサービスクォータの増加を要求する必要がある場合があります。Falcon-40Bのファインチューニングには、ml.g5.12xlargeインスタンスを使用します。
サービスクォータの増加を要求するには、AWS Service QuotasコンソールでAWSサービス、Amazon SageMaker、ml.g5.12xlargeインスタンス上で実行されるStudio KernelGatewayアプリに移動します。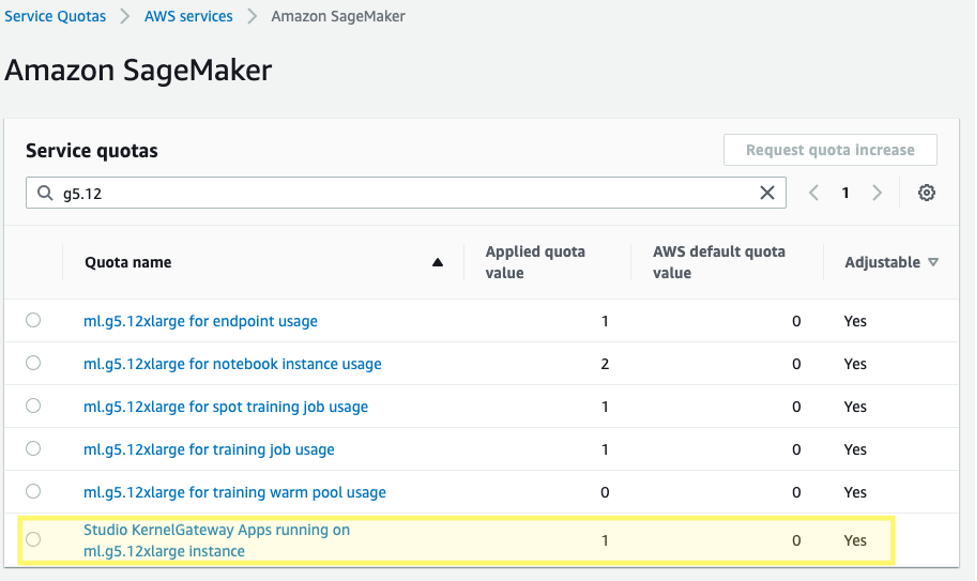
はじめに
この記事のコードサンプルは、以下のGitHubリポジトリで見つけることができます。始めるには、SageMaker StudioからData Science 3.0イメージとPython 3カーネルを選択し、パッケージをインストールするための最新のPython 3.10環境を用意します。

PyTorchと必要なHugging Faceとbitsandbytesライブラリをインストールします:
%pip install -q -U torch==2.0.1 bitsandbytes==0.39.1
%pip install -q -U datasets py7zr einops tensorboardX
%pip install -q -U git+https://github.com/huggingface/transformers.git@850cf4af0ce281d2c3e7ebfc12e0bc24a9c40714
%pip install -q -U git+https://github.com/huggingface/peft.git@e2b8e3260d3eeb736edf21a2424e89fe3ecf429d
%pip install -q -U git+https://github.com/huggingface/accelerate.git@b76409ba05e6fa7dfc59d50eee1734672126fdba次に、PyTorchのインストールに依存するCUDAを使用してCUDA環境パスを設定します。これは、bitsandbytesライブラリが正しいCUDA共有オブジェクトバイナリを見つけてロードするために必要なステップです。
# bitsandbytesのためにインストールしたcudaランタイムをパスに追加
import os
import nvidia
cuda_install_dir = '/'.join(nvidia.__file__.split('/')[:-1]) + '/cuda_runtime/lib/'
os.environ['LD_LIBRARY_PATH'] = cuda_install_dir事前学習済みの基礎モデルをロードする
bitsandbytesを使用して、Falcon-40Bモデルを4ビット精度で量子化し、Hugging Face Accelerateの単純なパイプライン並列処理を使用して4つのA10G GPUのメモリにモデルをロードできるようにします。以前に述べたHugging Faceのポストで説明されているように、QLoRAチューニングは、モデルの重みが4ビットのNormalFloatとして保存されるため、16ビットの微調整方法と一致することが多くの実験で示されていますが、必要に応じて前方および後方のパスで計算用bfloat16に非量子化されます。
model_id = "tiiuae/falcon-40b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)事前学習済みの重みをロードする際に、device_map="auto"を指定することで、Hugging Face Accelerateが自動的にモデルの各層をどのGPUに配置するかを決定します。このプロセスはモデル並列処理として知られています。
# Falconでは、リモートコードの実行を許可する必要があります。これは、モデルがtransformersの一部ではない新しいアーキテクチャを使用しているためです。
# コードはモデルの作者によって提供されています。
model = AutoModelForCausalLM.from_pretrained(model_id, trust_remote_code=True, quantization_config=bnb_config, device_map="auto")Hugging FaceのPEFTライブラリを使用すると、元のモデルのほとんどの重みを凍結し、追加の非常に小さなパラメーターセットをトレーニングしてモデルのレイヤーを置き換えたり拡張したりすることができます。これにより、必要な計算リソースの面でトレーニングがはるかに安価になります。LoRA構成でファインチューニングしたいFalconモジュールをtarget_modulesに設定します:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
# 出力: trainable params: 55541760 || all params: 20974518272|| trainable%: 0.2648058910327664モデルのパラメーターの0.26%のみをファインチューニングしていることに注意してください。これにより、合理的な時間内にこの処理が実行可能になります。
データセットをロードする
ファインチューニングにはsamsumデータセットを使用します。Samsumは、ラベル付きの要約を持つ16,000のメッセンジャーのような会話のコレクションです。以下はデータセットの例です:
{
"id": "13818513",
"summary": "アマンダはクッキーを焼いて、ジェリーに明日持って行きます。",
"dialogue": "アマンダ:クッキーを焼いたよ。食べる?\r\nジェリー:いいよ!\r\nアマンダ:明日持って行くね :-)"
}実際には、モデルを調整するために特定の知識を持つデータセットを使用することが望ましいです。このようなデータセットの構築は、Amazon SageMaker Ground Truth Plus を使用することで加速することができます。詳細については、Amazon SageMaker Ground Truth Plus からのジェネレーティブAIアプリケーションのための高品質な人間フィードバックの説明をご覧ください。
モデルの微調整
微調整の前に、使用するハイパーパラメータを定義し、モデルをトレーニングします。また、TensorBoardにメトリクスを記録するために、パラメータlogging_dirを定義し、Hugging Faceトランスフォーマーにreport_to="tensorboard"を要求することもできます。
bucket = ”<YOUR-S3-BUCKET>”
log_bucket = f"s3://{bucket}/falcon-40b-qlora-finetune"
import transformers
# デモンストレーションを実行するために、num_train_epochs=1を設定しています
trainer = transformers.Trainer(
model=model,
train_dataset=lm_train_dataset,
eval_dataset=lm_test_dataset,
args=transformers.TrainingArguments(
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_dir=log_bucket,
logging_steps=2,
num_train_epochs=1,
learning_rate=2e-4,
bf16=True,
save_strategy = "no",
output_dir="outputs",
report_to="tensorboard",
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)微調整のモニタリング
上記の設定を使用することで、リアルタイムで微調整をモニタリングすることができます。リアルタイムでGPUの使用状況をモニタリングするには、カーネルのコンテナから直接nvidia-smiを実行することができます。イメージコンテナ上でターミナルを起動するには、ノートブックの上部にあるターミナルアイコンを選択してください。

ここから、Linuxのwatchコマンドを使用して、0.5秒ごとにnvidia-smiを繰り返し実行することができます:
watch -n 0.5 nvidia-smi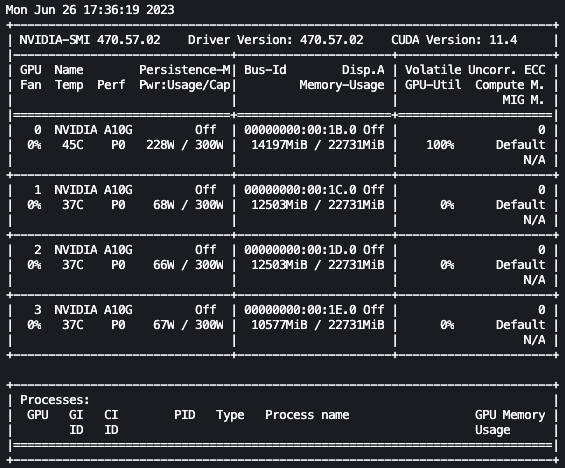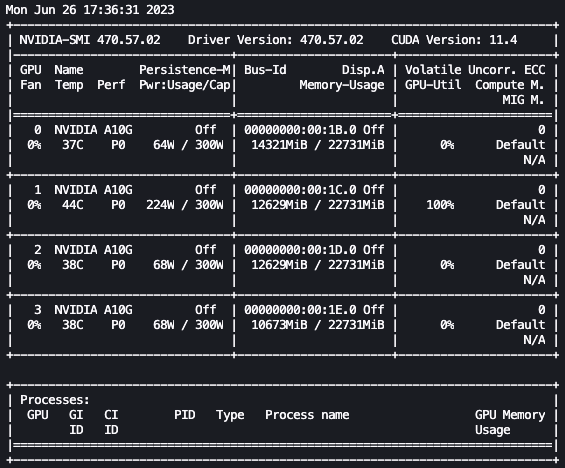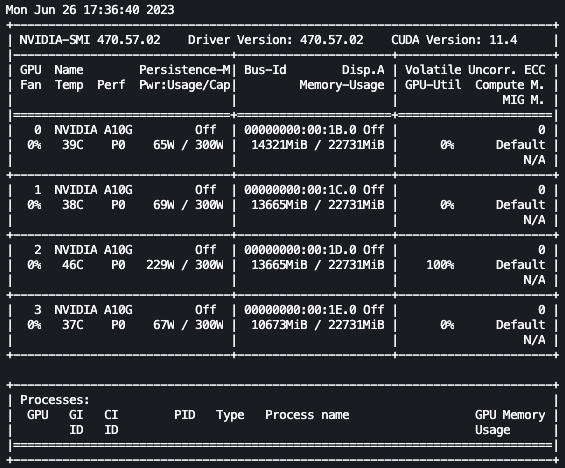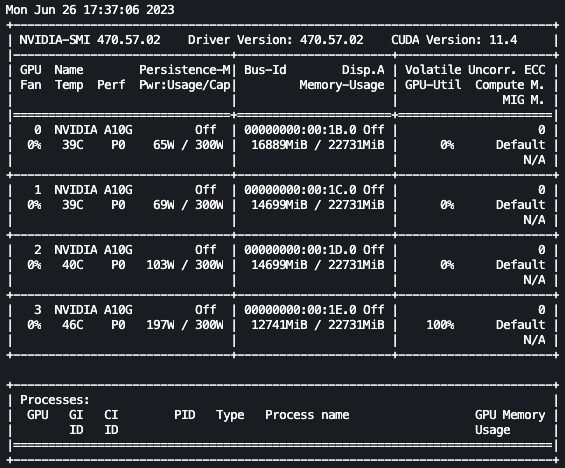
上記のアニメーションでは、モデルの重みが4つのGPUに分散され、層が直列に処理されるたびに計算がそれらに分散されていることがわかります。
トレーニングメトリクスをモニタリングするためには、指定したAmazon Simple Storage Service(Amazon S3)バケットに書き込むTensorBoardログを利用します。AWS SageMakerコンソールからSageMaker StudioドメインユーザーのTensorBoardを起動することができます:
ロード後、トレーニングおよび評価メトリクスを表示するために、Hugging Faceトランスフォーマーにログを記録するよう指示したS3バケットを指定できます。
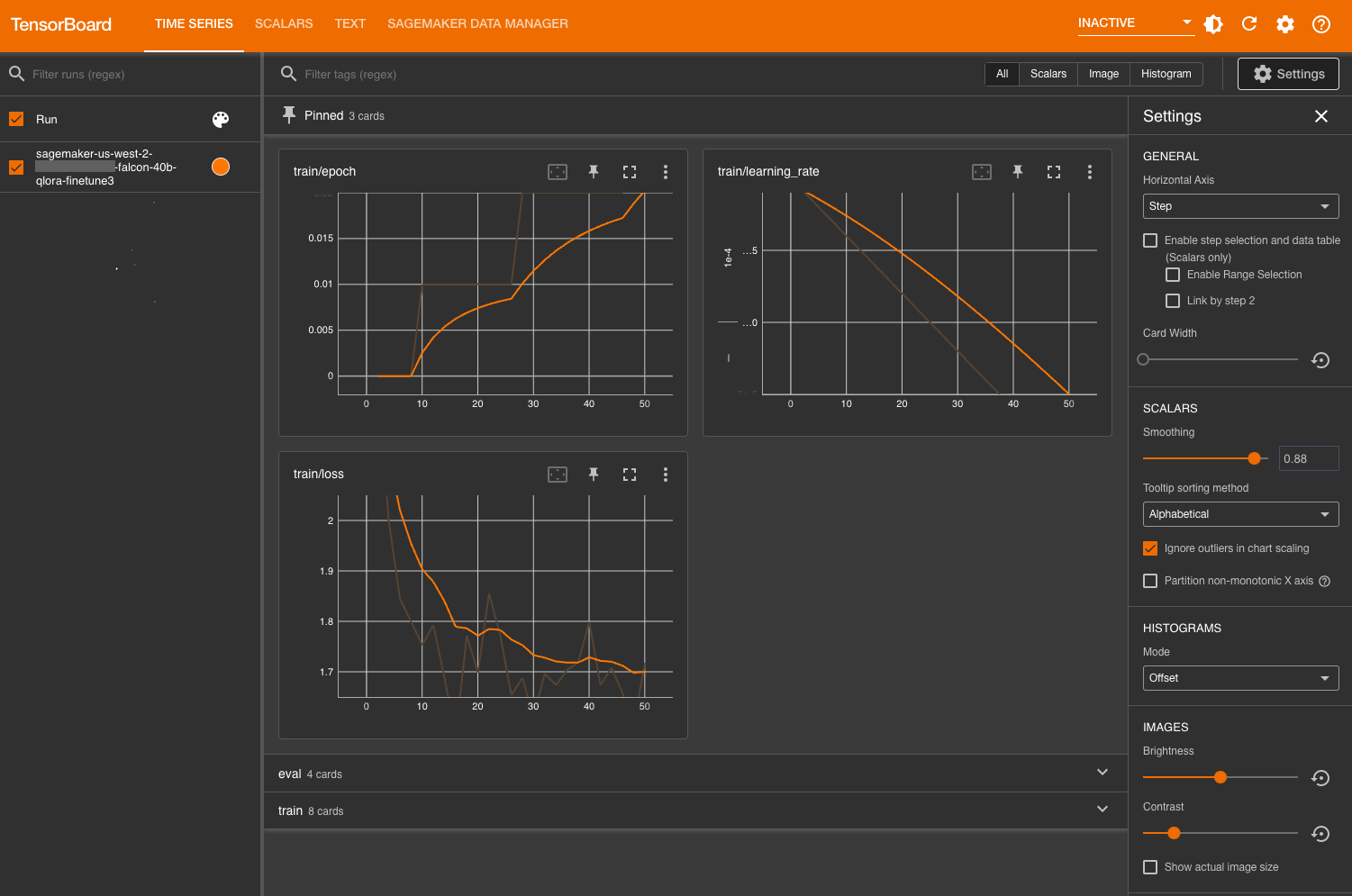
モデルの評価
モデルのトレーニングが完了した後、システム的な評価を実行したり、単に応答を生成することができます:
tokens_for_summary = 30
output_tokens = input_ids.shape[1] + tokens_for_summary
outputs = model.generate(inputs=input_ids, do_sample=True, max_length=output_tokens)
gen_text = tokenizer.batch_decode(outputs)[0]
print(gen_text)
# サンプル出力:
# チャットダイアログの要約:
# Richie:ポグバ
# Clay:ポグブーム
# Richie:すごいストライクだよね!
# Clay:ボールを右足に戻す瞬間から、私は席から離れました
# Richie:私もだね、友達
# Clay:彼の調子が長持ちすることを願ってるよ
# Richie:今シーズンはもっと成熟してるよ
# Clay:そうだね、ジョゼは彼を信頼してるんだ
# Richie:みんなもそう思ってるよ
# Clay:うん、初めての60分後に得点するのを本当に受けたよね
# Richie:報われたね
# Clay:そうだよね
# Richie:じゃあ、それじゃ
# Clay:それじゃ
# ---
# 要約:
# RichieとClayは、ポール・ポグバが決めたゴールについて話し合っています。彼の今シーズンの調子は良くなっており、彼らはこの調子が長く続くことを願っていますモデルのパフォーマンスに満足したら、モデルを保存することもできます:
trainer.save_model("path_to_save")また、専用のSageMakerエンドポイントにホストすることもできます。
クリーンアップ
リソースをクリーンアップするには、以下の手順を完了してください:
-
追加のコストを発生させないために、SageMaker Studioインスタンスをシャットダウンします。
-
TensorBoardアプリケーションをシャットダウンします。
-
Hugging Faceのキャッシュディレクトリをクリアするために、EFSディレクトリをクリーニングします:
rm -R ~/.cache/huggingface/hub
結論
SageMakerノートブックを使用すると、インタラクティブな環境で迅速かつ効率的にLLMを微調整することができます。この記事では、Hugging Face PEFTを使用して、QLoRAを使ってFalcon-40BモデルをSageMaker Studioノートブックで微調整する方法を紹介しました。ぜひ試してみて、コメントセクションでご意見をお聞かせください!
また、Amazonの生成AI機能については、SageMaker JumpStart、Amazon Titanモデル、Amazon Bedrockを探索してさらに学ぶことをお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 2023年に読むための自然言語処理に関する5冊の無料の書籍
- Wandaとは:大規模言語モデルに対するシンプルで効果的なプルーニング手法の紹介
- Google MusicLMを使用してテキストから音楽を生成する
- API管理を使用してAIパワードJavaアプリを管理する
- LangFlow | LLMを使用してアプリケーションを開発するためのLangChainのUI
- ProFusion における AI 非正則化フレームワーク テキストから画像合成における詳細保存に向けて
- Amazon SageMaker Canvasを使用して、ノーコードの機械学習を活用して、公衆衛生の洞察をより迅速にキャプチャーしましょう






