PDFからのエンティティ抽出をLLMsを使用して自動化する方法
「PDFからのエンティティ抽出をLLMsで自動化する方法」
ゼロショットラベリングの活用

現代の機械学習アプリケーションにおいて、高品質なラベル付きデータの必要性は言い尽くせません。モデルの性能向上から公平性の確保まで、ラベル付きデータの力は莫大です。残念ながら、このようなデータセットを作成するために必要な時間と労力も同様に大きいものです。しかし、もし私たちがこの作業にかける時間を数日からわずか数時間に短縮でき、それでいてラベリングの品質を維持または向上させることができたらどうでしょうか?理想的な夢?もはやそうではありません。
ゼロショットラーニング、フューショットラーニング、モデル補助ラベリングといった機械学習の新しいパラダイムは、この重要なプロセスに革新的なアプローチを提供しています。これらの技術は、高度なアルゴリズムの力を借りて、大規模なラベル付きデータセットの必要性を軽減し、より迅速かつ効率的かつ効果的なデータ注釈を可能にします。
このチュートリアルでは、大規模言語モデル(LLM)の文脈学習能力を活用して、非構造化および半構造化ドキュメントの自動ラベリング手法を紹介します。
SDSからの情報抽出
特定のタスクを解決するために広範なラベル付きデータが必要な従来の教師ありモデルとは異なり、LLMは自身の大規模な知識ベースにアクセスすることで、わずかな例からも情報を一般化し推測する能力を持っています。このような文脈学習と呼ばれる新たな能力により、LLMはテキスト生成だけでなく、名前エンティティ認識などのデータ抽出のような多くのタスクに適した選択肢となります。
このチュートリアルでは、GPT 3.5(またはChatGPT)のゼロショットおよびフューショットラベリング機能を使用して、さまざまな企業の安全データシート(SDS)にラベルを付けます。SDSは、化学物質の効果的な管理を支援するために設計された、特定の物質または混合物に関する包括的な情報を提供します。これらのドキュメントは、環境リスクを含む危険に関する詳細な情報を提供し、安全対策に関する貴重なガイダンスを提供する重要な役割を果たします。SDSは、職場における化学物質の安全な取り扱いと利用に関する知識源として不可欠であり、PDF形式で提供されることが一般的ですが、レイアウトは異なる場合があります。このチュートリアルでは、自動的に以下のエンティティを識別するAIモデルをトレーニングすることに興味があります:
- 製品番号
- CAS番号
- 使用例
- 分類
- GHSラベル
- 化学式
- 分子量
- 類義語
- 緊急電話番号
- 応急処置措置
- 成分
- ブランド
この関連情報を抽出し、検索可能なデータベースに保存することは、多くの企業にとって非常に価値があります。これにより、危険成分の検索と回収が非常に迅速に行えるようになります。以下はSDSの例です:

ゼロショットラベリング
テキスト生成とは異なり、情報抽出はLLMにとってはより困難なタスクです。LLMはテキスト補完のために訓練されており、関連情報の抽出を促されると通常は幻覚を見たり、追加のコメントやテキストを生成します。
LLMの結果を正しく解析するためには、JSONなどの一貫した出力を持つ必要があります。これには、適切なプロンプトエンジニアリングが必要です。また、結果を解析した後は、元のトークンにマッピングする必要があります。
幸いなことに、これらの手順はすでに実行され、UBIAIの注釈ツールを使用して抽象化されています。内部では、UBIAIがプロンプトを行い、データをコンテキストの長さ制限以下にチャンク化し、推論のためにOpenAIのGPT3.5 Turbo APIに送信します。出力が返されると、データは解析され、処理され、ドキュメントに自動ラベリングされます。
始めるには、単純なPDFや画像、またはネイティブのDocx形式のドキュメントをアップロードし、注釈ページに移動して注釈インターフェースのFew-shotタブを選択します:
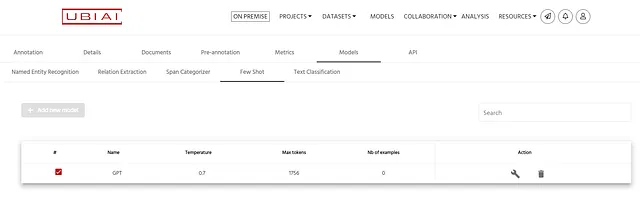
詳細については、こちらのドキュメントをご覧ください:https://ubiai.gitbook.io/ubiai-documentation/zero-shot-and-few-shot-labeling
UBIAIでは、モデルが次のドキュメントを自動的にラベル付けするために学習するための例の数を設定することができます。アプリは、既にラベル付けされたデータセットから最も情報量の多いドキュメントを自動的に選択し、プロンプトに連結します。このアプローチはFew-shotラベリングと呼ばれ、”Few”は0からnまでの範囲です。例の数を設定するには、構成ボタンをクリックし、以下に示すように例の数を入力してください。

このチュートリアルでは、LLMに学習するための例をゼロとして提供し、エンティティの説明に基づいてデータにラベルを付けるように要求します。驚くべきことに、LLMは私たちのドキュメントを非常によく理解し、ほとんどのラベル付けを正しく行います!
以下は、ゼロショットラベリングの結果であり、SDS PDFに対して例なしで行われていますが、非常に印象的です!
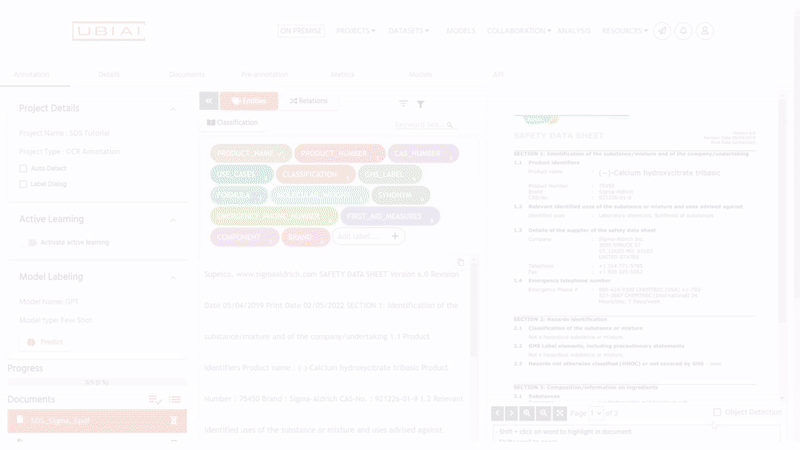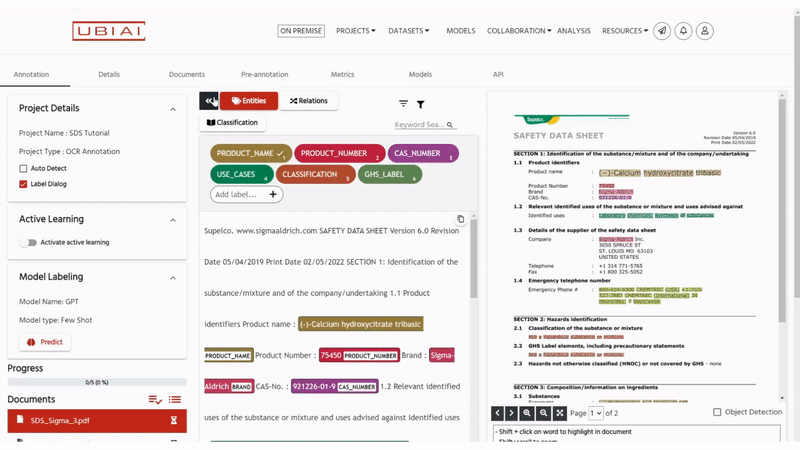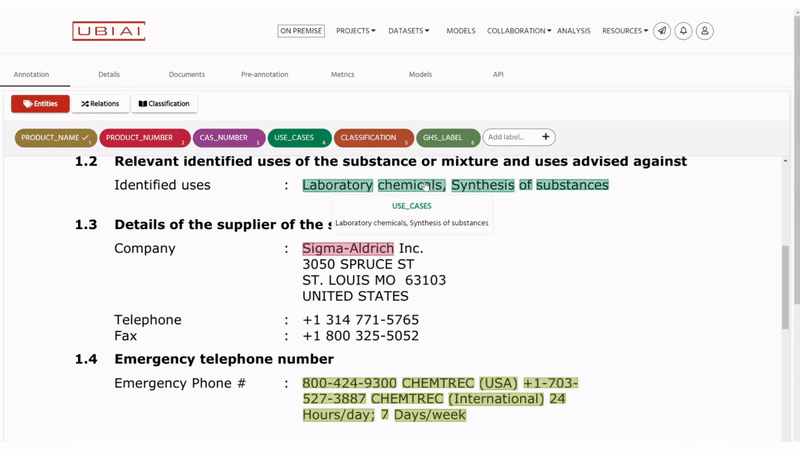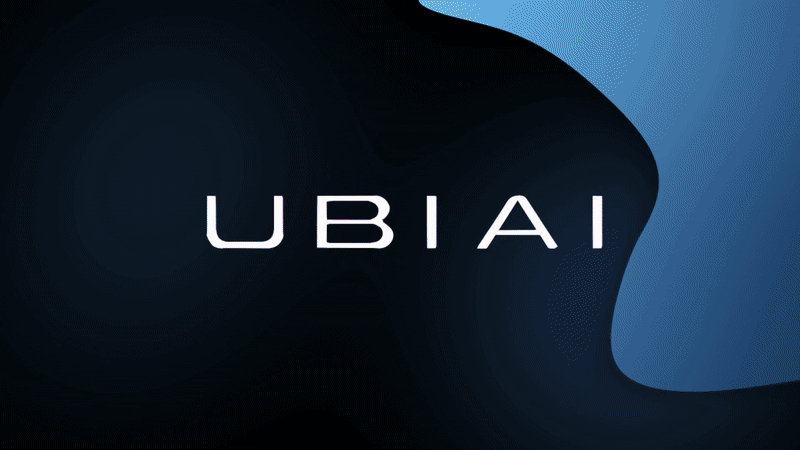
結論
大規模言語モデル(LLM)を使用したPDFからのエンティティ抽出の自動化は、ゼロショットラーニングやフューショットラーニングなどのLLMのインコンテキスト学習能力の登場により現実のものとなりました。これらの技術は、広範なラベル付きデータセットへの依存を減らし、より迅速かつ効果的なデータ注釈を可能にするために、LLMの潜在的な知識の力を利用しています。
このチュートリアルでは、セーフティデータシート(SDS)における半構造化ドキュメントの自動ラベリングの方法を紹介しましたが、非構造化テキストにも適用可能です。特にGPT 3.5(chatGPT)のインコンテキスト学習能力を活用することで、チュートリアルでは、SDS内の重要なエンティティ(製品番号、CAS番号、用途、分類、GHSラベルなど)を自動的に特定する能力を示しました。
検索可能なデータベースに保存された抽出情報は、危険成分の迅速な検索と取得を可能にし、企業にとって重要な価値を提供します。このチュートリアルでは、LLMが明示的な例なしでSDSから情報を理解し抽出するゼロショットラベリングの可能性を示しました。これは、テキスト生成タスクを超えたLLMの柔軟性と汎用性の能力を示しています。
LLMのゼロショット能力を使用して独自のトレーニングデータセットを作成することに興味がある場合は、ここでデモを予約してください。
Twitterで@UBIAI5をフォローしてください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
