複数の画像やテキストの解釈 機械学習 - Section 172
データから洞察を抽出し、予測を行う際の機械学習の力を発見してください

「TransformersとTokenizersを使用して、ゼロから新しい言語モデルを訓練する方法」
ここ数か月間で、私たちはtransformersとtokenizersライブラリにいくつかの改良を加え、新しい言語モデルをゼロからトレーニ...

「Microsoft Azureの新しいディープラーニングと自然言語処理のチュートリアルを発表します」
ODSCでは、Deep LearningとNLPに関するMicrosoft Azureのチュートリアルシリーズを発表できることを非常に喜んでいますこのコ...
テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
はじめに 近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページ...

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserら...

より小さく、より速い言語モデルのためのブロック疎行列
空間と時間を節約する、ゼロを一つずつ 以前のブログ投稿では、疎行列とそのニューラルネットワークへの改善効果について紹介...

エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Ra...

実践におけるFew-shot学習:GPT-Neoと🤗高速推論API
多くの機械学習のアプリケーションでは、利用可能なラベル付きデータの量が高性能なモデルの作成の障害となります。NLPの最新...

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必...
機械学習の時代がコードとして到来しました
2021年版のState of AIレポートが先週発表されました。そして、Kaggle State of Machine Learning and Data Science Surveyも...
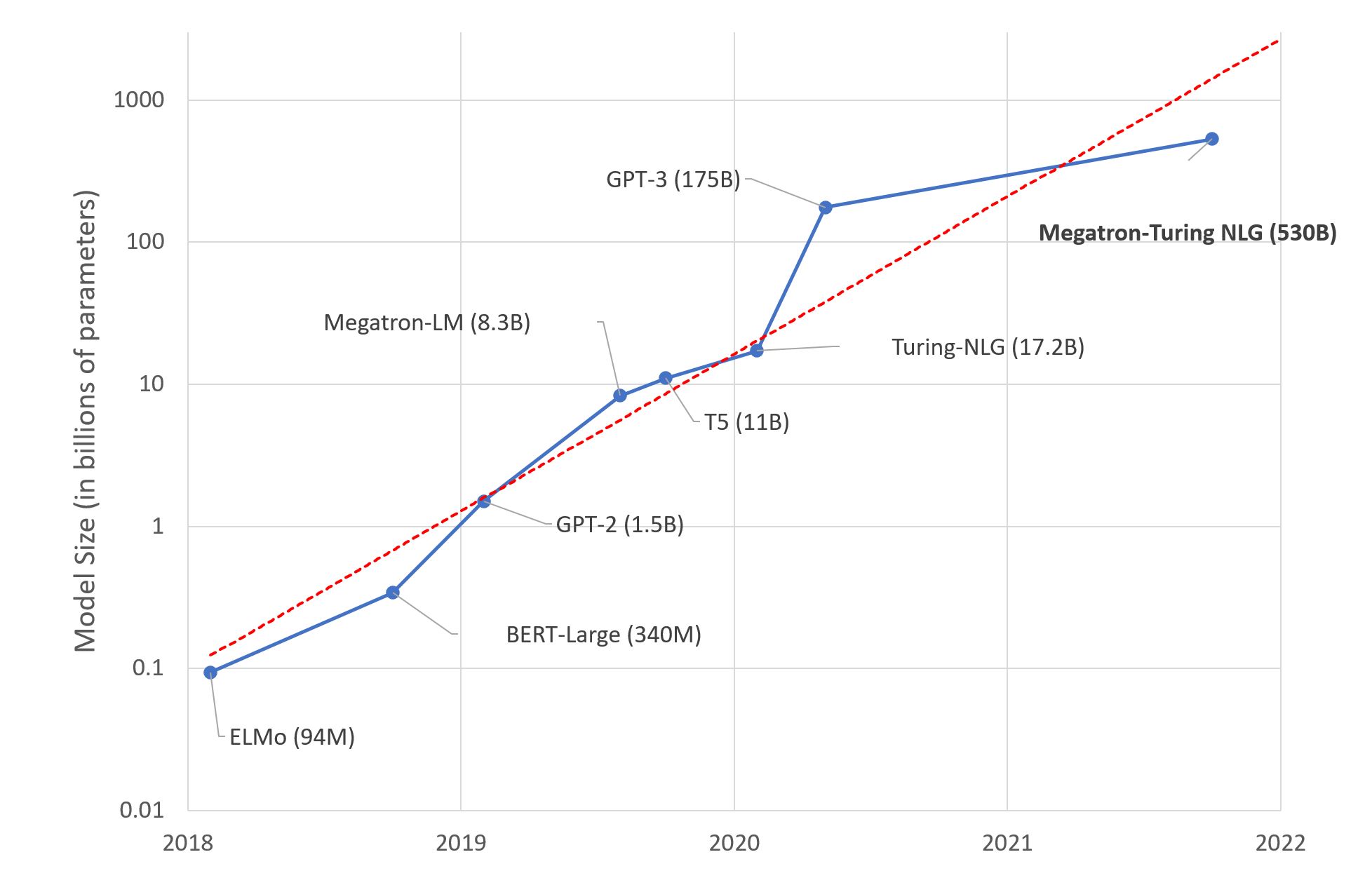
大規模言語モデル:新たなモーアの法則?
数日前、MicrosoftとNVIDIAは「世界最大かつ最もパワフルな生成言語モデル」と称される、Megatron-Turing NLG 530BというTran...

- You may be interested
- 不正行為はこれで終わり!Sapia.aiがAIに...
- 「合成キャプションはマルチモーダルトレ...
- 「RunPodを使用した生成的LLMsの実行 | サ...
- PoisonGPT ハギングフェイスのLLMがフェイ...
- 「インドが最新のAIを活用してペイメント...
- 「プロンプトエンジニアであるということ...
- Fast.AIディープラーニングコースからの7...
- 私の記事を読むと、あなた方は私がどれだ...
- 「FastEmbedをご紹介:高速かつ軽量なテキ...
- 「LangChain、Google Maps API、およびGra...
- ChatGPTはナップサック問題を解決できます...
- 国連事務総長、AIに関する高位諮問機関を発足
- 「このディスインフォメーションはあなた...
- 統計分析入門ガイド | 5つのステップと例
- GPT-4.5 本当か嘘か?私たちが知っていること
Find your business way
Globalization of Business, We can all achieve our own Success.