TensorFlowを使用したGANの利用による画像生成
'TensorFlowを使用したGANによる画像生成'
イントロダクション
この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。
学習目標
- この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。
- このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。
- この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。
- 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。
- さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。
この記事は、データサイエンスブログマラソンの一環として公開されました。
何を構築するのか?
既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。
この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。
どのように設定しますか?
この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。
モデルの構築
構築するGANモデルは、2つの重要なコンポーネントで構成されています:
- ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。
- ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。
GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。
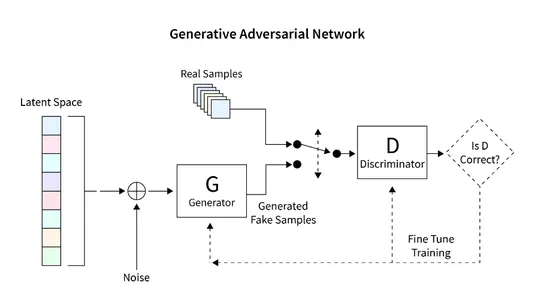
データセットの読み込み
MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。
次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。
各画像の形状は、28x28x1の行列と定義されており、最後の次元は画像のチャンネル数を表します。MNISTデータセットはグレースケール画像なので、チャンネルは1つだけです。
この特定の例では、潜在空間のサイズ(”zsize”と表示されています)を100に設定しています。この値は、特定の要件や好みに応じて調整することができます。
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np
num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100
(train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))ジェネレータの定義
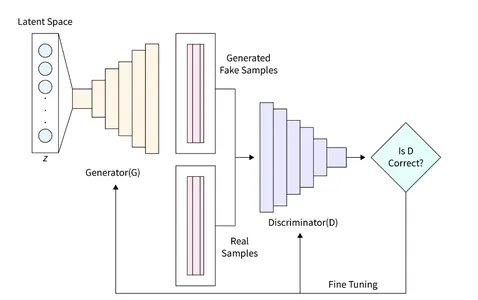
ジェネレータ(D)はGANにおいて重要な役割を果たし、ディスクリミネータを欺くことができるリアルな画像を生成する責任を負います。GANにおいて画像形成の主要な要素として機能します。この研究では、ジェネレータのために特定のアーキテクチャを使用し、完全連結(FC)層を組み込み、リークyReLU活性化関数を使用します。ただし、ジェネレータの最後の層ではLeakyReLUの代わりにTanH活性化関数を使用します。この調整は、生成された画像が元のMNISTデータベースと同じ区間(-1、1)に収まるようにするために行われました。
def build_generator():
gen_model = Sequential()
gen_model.add(Dense(256, input_dim=z_size))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(512))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(1024))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(np.prod(input_shape), activation='tanh'))
gen_model.add(Reshape(input_shape))
gen_noise = Input(shape=(z_size,))
gen_img = gen_model(gen_noise)
return Model(gen_noise, gen_img)ディスクリミネータの定義
生成敵対的ネットワーク(GAN)では、ディスクリミネータ(D)は真の画像と生成された画像の真正性と尤度を評価して区別する重要な役割を果たします。このコンポーネントはバイナリ分類問題と見なすことができます。このタスクに対処するために、完全連結層(FC)、リークyReLU活性化関数、ドロップアウト層を組み合わせた簡略化されたネットワークアーキテクチャを使用することができます。ディスクリミネータの最後の層には、FC層の後にSigmoid活性化関数が含まれていることを特に述べておきます。Sigmoid活性化関数は所望の分類確率を生成します。
def build_discriminator():
disc_model = Sequential()
disc_model.add(Flatten(input_shape=input_shape))
disc_model.add(Dense(512))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(256))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(1, activation='sigmoid'))
disc_img = Input(shape=input_shape)
validity = disc_model(disc_img)
return Model(disc_img, validity)損失関数の計算
GANにおいて良好な画像生成プロセスを確保するためには、そのパフォーマンスを評価するための適切なメトリックを決定することが重要です。このパラメータを損失関数によって定義します。
ディスクリミネータは、生成された画像を真の画像または偽の画像に分割し、その真正性の確率を与える責任があります。この違いを実現するために、ディスクリミネータは、実際の画像が与えられたときに関数D(x)を最大化し、偽の画像が与えられたときにD(G(z))を最小化することを目指します。
一方、ジェネレータの目的は、ディスクリミネータを欺くことで誤解を招くリアルな画像を生成することです。数学的には、これはD(G(z))をスケーリングすることを含みます。ただし、このコンポーネントのみを損失関数として依存すると、ネットワークが間違った結果に自信を持ちすぎる可能性があります。この問題を解決するために、損失関数の対数(D(G(z))を使用します。
GANの画像生成の総合的なコスト関数は、最小ゲームとして表現することができます:
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
このようなGANのトレーニングは、微妙なバランスが必要であり、二人の相手同士の対戦として行われます。各側はMinMaxゲームをプレイすることによって、相手に影響を与え、上回ろうとします。
GeneratorとDiscriminatorの実装には、Binary Cross Entropy Lossを使用することができます。
GeneratorとDiscriminatorの実装には、Binary Cross Entropy Lossを利用することができます。
# discriminator
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
z = Input(shape=(z_size,))
# generator
img = generator(z)
disc.trainable = False
validity = disc(img)
# combined model
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')損失の最適化
ネットワークのトレーニングを容易にするために、GANをMinMaxゲームに関与させることが目的です。この学習プロセスは、勾配降下法を用いてネットワークの重みを最適化することによって行われます。学習プロセスを加速し、局所的に収束するのを防ぐために、確率的勾配降下法(SGD)が用いられます。
DiscriminatorとGeneratorは異なる損失を持つため、単一の損失関数では両方のシステムを同時に最適化することはできません。したがって、各システムに対して別々の損失関数を利用します。
def intialize_model():
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(z_size,))
img = generator(z)
disc.trainable = False
validity = disc(img)
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
return disc, Generator, and combined必要なすべての機能を指定した後、システムをトレーニングし、損失を最適化することができます。画像を生成するためにGANをトレーニングする手順は次のとおりです:
- 画像をロードし、ロードされた画像と同じサイズのランダムな音を生成します。
- アップロードされた画像と生成された音の違いを区別し、本物または偽物の可能性を考慮します。
- 同じ大きさの別のランダムなノイズを生成し、ジェネレータに入力します。
- ジェネレータを特定の期間トレーニングします。
- 画像が満足できるまでこれらの手順を繰り返します。
def train(epochs, batch_size=128, sample_interval=50):
# 画像のロード
(train_ims, _), (_, _) = mnist.load_data()
# 前処理
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# トレーニングループ
for epoch in range(epochs):
batch_index = np.random.randint(0, train_ims.shape[0], batch_size)
imgs = train_ims[batch_index]
# ノイズの生成
noise = np.random.normal(0, 1, (batch_size, z_size))
# Generatorを使用して予測
gen_imgs = gen.predict(noise)
# 損失関数の計算
real_disc_loss = disc.train_on_batch(imgs, valid)
fake_disc_loss = disc.train_on_batch(gen_imgs, fake)
disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss)
noise = np.random.normal(0, 1, (batch_size, z_size))
g_loss = full_model.train_on_batch(noise, valid)
# 一定のエポックごとに出力を保存
if epoch % sample_interval == 0:
one_batch(epoch)手書き数字の生成
MNISTデータセットを使用して、Generatorを使用して一連の画像の予測を生成するユーティリティ関数を作成することができます。この関数はランダムな音を生成し、それをジェネレータに供給し、生成された画像を表示して特別なフォルダに保存します。ネットワークの進捗状況を監視するために、このユーティリティ関数を定期的に(例えば200サイクルごとに)実行することをお勧めします。以下に実装例を示します:
def one_batch(epoch):
r, c = 5, 5
noise_model = np.random.normal(0, 1, (r * c, z_size))
gen_images = gen.predict(noise_model)
# 画像を0〜1にスケーリング
gen_images = gen_images*(0.5) + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()実験では、バッチサイズ32を使用して、約10,000エポックでGANをトレーニングしました。トレーニングの進捗を追跡するために、200エポックごとに生成された画像を保存し、「images」という指定されたフォルダに保存しました。
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)さて、異なる段階でのGANシミュレーションの結果を見てみましょう:初期化、400エポック、5000エポック、そして最終結果の10000エポックです。
最初に、ジェネレータへのランダムノイズを入力として開始します。

トレーニングの400エポック後、いくつかの進捗が見られますが、生成された画像はまだ実際の数字とはかなり異なります。

5000エポックのトレーニング後、生成された図形がMNISTデータセットに似ていることがわかります。

トレーニングの10000エポックを完了すると、以下の出力が得られます。

これらの生成された画像は、ネットワークのトレーニングに使用する手書き数字データに非常に近いものです。これらの画像はトレーニングセットの一部ではなく、完全にネットワークによって生成されます。
次のステップ
GANの画像生成で良い結果を得たので、さらに改善する方法はいくつかあります。このディスカッションの範囲内で、以下のいくつかの提案を検討することができます:
- 潜在空間変数z_sizeの異なる値を試して、効率を向上させるかどうかを確認します。
- トレーニングエポックの数を10,000以上に増やします。トレーニングの期間を2倍または3倍にすることで、改善または劣化した結果が明らかになるかもしれません。
- ファッションMNISTや動くMNISTなど、異なるデータセットを使用してみてください。これらのデータセットはMNISTと同じ構造を持っているため、既存のコードを適応させます。
- CycleGun、DCGANなどの代替アーキテクチャを試してみてください。ジェネレータとディスクリミネータの関数を変更するだけで、これらのモデルを試すことができます。
これらの変更を実装することで、GANの機能をさらに向上させ、画像生成の新たな可能性を探求することができます。
これらの生成された画像は、ネットワークのトレーニングに使用される手書き数字データに非常に近いものです。これらの画像はトレーニングセットの一部ではなく、完全にネットワークによって生成されます。
結論
要約すると、GANは既存のデータベースを基に新しい画像を生成することができる強力な機械学習モデルです。このチュートリアルでは、Tensorflowライブラリを例として、MNISTデータベースを使用してシンプルなGANを設計してトレーニングする方法を示しました。
重要ポイント
- GANは、ランダムな入力から新しい画像を生成するジェネレータと、実際の画像と偽の画像を区別することを目指すディスクリミネータという2つの重要なコンポーネントで構成されています。
- 学習のプロセスを通じて、手書き数字に非常に似た画像のセットを作成することに成功しました。
- GANのパフォーマンスを最適化するために、実際の画像と偽の画像を区別するのに役立つ一致メトリックと損失関数を提供しています。未知のデータでGANを評価し、ジェネレータを使用することで、新しい未知の画像を生成することができます。
- 全体として、GANは画像生成において興味深い可能性を提供し、機械学習やコンピュータビジョンなどのさまざまなアプリケーションに大きなポテンシャルを持っています。
よくある質問
この記事で表示されているメディアはAnalytics Vidhyaの所有ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
