T5 テキストからテキストへのトランスフォーマー(パート2)
T5 Transformer for Text-to-Text (Part 2)
大規模言語モデルの最適な転移学習

BERT [5] の提案により、自然言語処理(NLP)のための転移学習手法が広まりました。インターネット上の無ラベルテキストの広範な利用可能性により、私たちは容易に(i)大量の生のテキストで大規模なトランスフォーマーモデルを事前学習し、(ii)これらのモデルを微調整してダウンストリームタスクを正確に解決することができました。この手法は非常に効果的でしたが、その新たな人気により、多くの代替手法や改良案が提案されました。これらの新しい手法が利用可能になると、自然に次のような疑問が湧いてくるでしょう。「NLPにおける転移学習のベストプラクティスは何でしょうか?」
この質問には、統一されたテキスト対テキストトランスフォーマー(T5)モデルによる分析で答えが出ました。T5は、すべてのタスク(事前学習および微調整の両方)をテキスト対テキストの形式で再定義するため、モデルはテキスト入力を受け取り、テキスト出力を生成します。この統一された形式を使用することで、T5はさまざまな転移学習設定を分析し、多くの手法を比較することができます。以前のニュースレターでは、T5モデルのフォーマット、アーキテクチャ、および全体的なアプローチについて学びました。
このニュースレターでは、T5による分析、つまり、NLPにおける転移学習のための事前学習目的、アーキテクチャ、モデル/データのスケール、およびトレーニングアプローチの異なる実証比較について概説します。[1]内では、これらのオプションのそれぞれが個別に研究され、T5のパフォーマンスへの影響が評価されます。この分析を研究することで、高い精度で言語理解タスクを解決できる最先端のT5フレームワークを生み出すための一連のベストプラクティスが導かれます。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*D-CX8NuHl2Uh_LK2.png)
準備
T5のアーキテクチャの動機と基礎については既にカバーしました。この記事のリンク先でその内容を確認してください 。ここでもこれらのアイデアを簡単に説明します。BERT [5] の提案により、NLPのための転移学習パラダイム(つまり、いくつかの別個のデータセットでモデルを事前学習し、その後ターゲットデータセットで微調整する)が広まりました。しかし、BERTの効果により、多くの研究者がこのトピックに注力し、さまざまな修正や改善を提案しました。T5のアイデアは、(i)すべての言語タスクを統一されたテキスト対テキスト形式に変換すること(下の図を参照)と、(ii)NLPの転移学習のさまざまな設定を研究し、最も効果的な技術を導き出すことです。
- この人工知能ベースのタンパク質言語モデルは、汎用のシーケンスモデリングを解除します
- DiffCompleteとは、不完全な形状から3Dオブジェクトを完成させることができる興味深いAIメソッドです
- ゼロから大規模言語モデルを構築するための初心者ガイド
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*4FVF24Tfus7f9nh1.png)
言語モデリング vs. ノイズ除去
NLPにおける初期の転移学習手法では、事前学習のための因果言語モデリング目的 [6] が利用されました。しかし、その後ノイズ除去(マスクされた言語モデリング、またはMLMとも呼ばれる)目的の方が優れたパフォーマンスを示すことが示されました [5]。あるモデルに入力するためのテキストトークンのセットが与えられた場合、MLMは以下の手順で動作します:
- トークンの15%をランダムに(一様に)選択する
- 選択されたトークンの90%を
[MASK]トークンで置き換える - 選択されたトークンの10%をランダムなトークンで置き換える
- モデルを訓練して各
[MASK]トークンを予測/分類する
一様に選択されるトークンの割合を「破損率」と呼びます。T5内では、このノイズ除去目的のいくつかの異なるバリアントを見ることができますが、基本的なアイデアは同じです。
「すべての目的は、ラベルのないテキストデータセットからトークン化されたテキストスパンに対応するトークンIDのシーケンスを受け取ります。トークンシーケンスは処理され、(破損された)入力シーケンスと対応するターゲットが生成されます。その後、モデルは通常の最尤法で訓練され、ターゲットシーケンスを予測します。」- [1]より引用-
ベンチマークと評価
T5はNLP(自然言語処理)における転移学習のベストプラクティスを導き出す試みです。しかし、どの技術が最も効果的かを判断するために、T5はさまざまなタスクと自然言語のベンチマークで評価されます。これらのタスクはすべて、T5のテキストからテキストへの形式で解決されます。これらのタスクの詳細については、[1]のセクション2.3を参照してください。以下に簡単な概要を示します。
- GLUEとSuperGLUE [7, 8]:これらのベンチマークには、文の受容可能性判断、感情分析、言い換え、文の類似度、自然言語推論(NLI)、共参照解析、文の補完、単語の意味の曖昧さ解消、質問応答など、さまざまなタスクが含まれています。SuperGLUEは、GLUEと似た構造を持つ改良されたより困難なベンチマークです。
- CNN + Daily Mail要約 [9]:ニュース記事と、記事の主要なハイライトを捉えた短い要約テキストのペアです。
- SQuAD [10]:Wikipediaの記事に関する質問応答データセットで、各質問の回答は関連記事のテキストセグメントです。
- いくつかの翻訳データセット(例:英語からドイツ語、フランス語、ルーマニア語への翻訳)。
特に、GLUEとSuperGLUEベンチマークのすべてのタスクは、T5によって結合され、すべてのタスクに対して一度にファインチューニングが行われます。
その他の重要なアイデア
- 異なるタイプのトランスフォーマーアーキテクチャ[リンク]
- 言語モデリングの基礎[リンク]
- セルフアテンション[リンク]
T5から学ぶことは何ですか?
先に述べたように、T5の実験は、NLPにおける転移学習のベストプラクティスを見つけることを目指しています。これを行うために、まずベースラインアプローチが提案され、その後、このベースラインのさまざまな側面(モデルアーキテクチャ/サイズ、データセット、事前学習目的など)が一つずつ変更され、最も効果的なものを見つけます。このアプローチは、座標降下法の戦略を模倣しています。まず、ベースラインの手法を説明し、その後、さまざまな転移学習設定をテストした結果、T5の見つけた知見を説明します。
T5ベースラインモデル
![(from [11])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*Cn9aZgOSmcq8R70n.png)
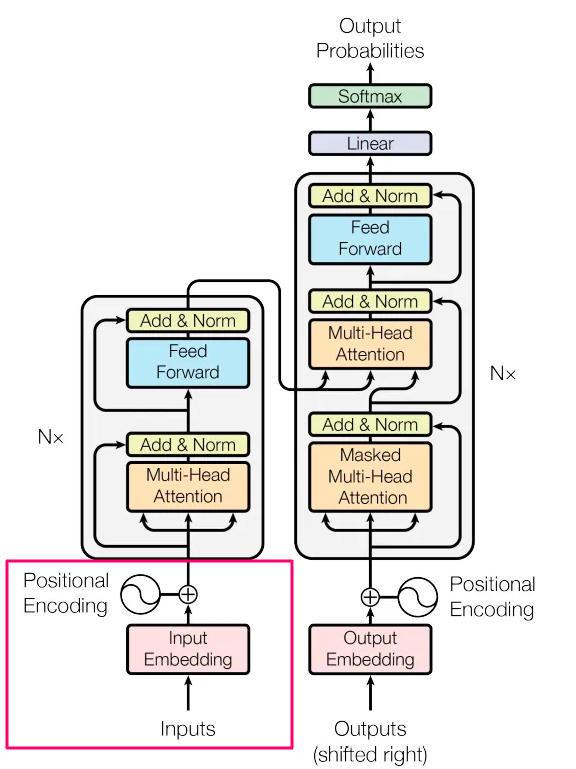
モデル。 T5のベースラインアーキテクチャは、標準のエンコーダーデコーダートランスフォーマーアーキテクチャを使用しています。エンコーダーとデコーダーは、BERTBaseと同様の構造になっています。多くの最新のNLPアプローチでは、「シングルスタック」トランスフォーマーアーキテクチャ(BERTの場合はエンコーダーのみのアーキテクチャ、ほとんどの言語モデルの場合はデコーダーのみのアーキテクチャ)を使用していますが、T5はこれらのアーキテクチャを避けることを選択しています。興味深いことに、[1]の著者は、エンコーダーデコーダーアーキテクチャが生成タスクと分類タスクの両方で印象的な結果を達成すると結論づけています。エンコーダーのみのモデルは、トークン/スパンの予測に特化しており、生成タスクをうまく解決することができないため、[1]では考慮されていません。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*543UQtSy3witRTTr.png)
エンコーダーデコーダーアーキテクチャと比較して、デコーダーのみのモデルは制約があります。デコーダーのみのモデルは、因果(またはマスクされた)セルフアテンションのみを使用します。マスクされたセルフアテンションは、あるトークンの表現を計算する際に、それに続くトークンのみを考慮します。しかし、特定の場合には、初期のスパンまたは接頭辞のテキストに対して完全に可視性のあるアテンションを実行し、この接頭辞に基づいて出力を生成したい場合があります(例:翻訳タスク)。デコーダーのみのモデルは、入力全体に対して因果的なセルフアテンションを実行するため、このような場合に対応することができません。
T5のトレーニング。 T5モデルは、C4コーパスから合計34Bトークンで事前学習されます。比較のため、BERTは137Bトークン、RoBERTaは2.2Tトークンでトレーニングされます[5, 12]。BERTからのMLM目的に着想を得て、T5はわずかに変更されたノイズ除去目的を使用して事前学習されます。これは次のような手順で行われます:
- 入力シーケンスの15%のトークンをランダムに選択します
- 選択されたトークンの連続したスパンを1つの「センチネル」トークンで置き換えます
- 各センチネルトークンには、現在の入力シーケンスに固有のIDが割り当てられます
- センチネルトークンで区切られたすべての選択されたトークンを使用してターゲットを構築します
このタスクは少し複雑に見えますが、以下の短い入力シーケンスのイラストを見ることで、その動作の概略を理解することができます。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*zKiC5FTXGOpXFbZT.png)
マスクされたトークンのスパン全体を単一のセンチネルトークンで置き換えることにより、事前学習の計算コストを削減し、より短い入力とターゲットのシーケンス上で操作する傾向があります。
ファインチューニング。事前学習が行われた後、T5は評価前に各ダウンストリームタスクごとに個別にファインチューニングされます。T5が使用するテキスト対テキスト形式のため、事前学習とファインチューニングは最大尤度目的関数を使用します!つまり、正しい答えをテキストのシーケンスとして定式化し(事前学習とファインチューニングの両方で)、モデルを正しいテキストのシーケンスを出力するように訓練します。
ベースラインのパフォーマンスはどうですか?下の表に示されるように、ベースラインのT5モデルはBERTなどの以前のモデルと同様のパフォーマンスを発揮しますが、これらのモデルとは直接比較できません(つまり、ベースラインのT5モデルはBERTBaseの計算量の25%を使用します)。さらに、事前学習はほとんどのタスクにおいて大きな利益をもたらします。唯一の例外は、翻訳タスクであり、事前学習の有無に関わらず性能が類似しています。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*C0tVp-xJo7K9zRQY.png)
より良いアプローチを探す…
ベースラインのアーキテクチャとトレーニングアプローチをテストした後、[1]の著者はアーキテクチャ、事前学習目的、およびファインチューニング戦略の一つを変更してテストします。これらの異なる転移学習のバリエーションをテストすることで、さまざまな言語理解タスクに対して最も効果的なアプローチを見つけることができます。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*-iNQByEMobccefG5.png)
アーキテクチャ。転移学習の結果に対するアーキテクチャの選択の影響を調査するために、トランスフォーマーアーキテクチャのさまざまなバリエーションをテストすることができます。[1]でテストされたアーキテクチャには、通常のエンコーダーデコーダーアーキテクチャ、デコーダーのみのアーキテクチャ、およびプレフィックス言語モデルが含まれます。プレフィックス言語モデルは、シーケンス内の固定されたプレフィックスに対して完全可視化アテンションを実行し、因果的なセルフアテンションを使用して出力を生成します。これらのアーキテクチャの主な違いは、セルフアテンションメカニズム内で使用されるマスキングのタイプです。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*NIWyAam57H1ytyVP.png)
さまざまなアーキテクチャをテストすると(因果的言語モデリングおよびノイズ除去目的を使用して)、エンコーダーデコーダートランスフォーマーアーキテクチャ(ノイズ除去目的を使用)が最も優れたパフォーマンスを発揮することがわかります。このエンコーダーデコーダーバリアントは、他のモデルに比べて合計2Pのパラメータを持ち、デコーダーのみのモデルと同じ計算コストです。パラメータの総数をPに減らすために、エンコーダーとデコーダー間でパラメータを共有することが、非常に良い結果をもたらすことがわかりました。
事前学習目的。最初に、T5は3種類の異なる事前学習目的を使用してトレーニングされます。最初の目的はBERTスタイルのMLM(Masked Language Modeling)です。他の目的は、デシャッフル[3]戦略(つまり、モデルがシャッフルされた文を正しい順序に戻すことを試みる)およびプレフィックスベースの言語モデリング目的[2]です。後者では、テキストは2つのスパンに分割され、最初のスパンはエンコーダーへの入力として渡され、2番目のスパンはデコーダーによって予測されます(つまり、エンコーダーデコーダートランスフォーマーを使用していることを思い出してください)。これらの目的でトレーニングされたモデルのパフォーマンスを以下で比較すると、ノイズ除去目的が他の戦略よりも明らかに優れていることがわかります。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*YK-9FeRObdXKtGv5.png)
ここから、[1]の著者はBERTスタイルのMLM目的[4]に対して、以下の表に示すようないくつかの修正をテストしています。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*hj0-BVweyC4R2YgU.png)
これらのバリエーションのそれぞれは同様の結果を示す傾向があります。しかし、破損したトークンの一部全体を単一のセンチネルトークンで置き換え、対象内の破損したトークンの予測のみを試みるような事前トレーニング目的を選択することで、事前トレーニングの計算コストを最小化することができます。そのため、連続するトークンの範囲全体をマスキングするベースライン戦略は、短いターゲットシーケンスを生成するため効率的です。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*0UbFcovLMq8YOelq.png)
[1]の著者は異なる破損率をテストし、破損率が結果にほとんど影響を与えず、15%の設定がうまく機能することを発見しました。トークンの範囲を明示的に選択して破損させる代替事前トレーニング目的(すなわち、ベースライン手法は一様にトークンを選択する代わりに範囲として選択し、連続するトークンを結合する)も、ベースラインと同様の結果を示しました。[1]でテストされた異なる事前トレーニング目的の概要は、以下に示されています。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*Ru7uGuqpgWJpY3Nr.png)
さまざまな戦略が研究されましたが、主なポイントは次のとおりです:(i) ノイズ除去目的が最も優れている、(ii) ノイズ除去目的のバリエーションは同様の結果を示す、および (iii) ターゲットの長さを最小化する戦略が最も計算効率が高いです。
データとモデルのサイズ。最後に、T5の品質に与えるスケールの影響が研究されます。まず、T5は異なるデータセットで事前トレーニングされます。これには、フィルタリングされていないデータセット、ニュース特化のデータセット、GPT-2のWebTextコーパスを模倣したデータセット、およびWikipediaコーパスのいくつかのバリエーションが含まれます。これらのデータセットの各々で事前トレーニング後のT5のパフォーマンスが以下に示されています。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*qezeuqI77yCJjfUb.png)
ここでは、(i) 事前トレーニングコーパスをフィルタリングしないことが非常に損なわれること、および (ii) ニュースベースのコーパスでの事前トレーニングが、ニュース記事に基づいた読解データセットで最も良いパフォーマンスを発揮することがわかります。
「これらの結果の背後にある主な教訓は、ドメイン内の未ラベルデータでの事前トレーニングは、ダウンストリームのタスクのパフォーマンスを向上させることができるということです。これは予想されることですが、任意のドメインの言語タスクに迅速に適応できるモデルを事前トレーニングすることを目指す場合には満足のいく結果ではありません。」- [1]より
さらに、T5はC4コーパスの切り詰められたバージョンを使用して事前トレーニングされます。これらの実験から、データが多いほど良いことがわかります。事前トレーニング中にデータセットの小さなバージョンを複数回ループさせると、過学習が引き起こされ、ダウンストリームのパフォーマンスに悪影響を与えます;以下を参照してください。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*O31hxA170fVHZ1Uo.png)
T5モデルをスケールアップするために、著者らは以下の修正をテストしています:
4Xより多いトレーニングイテレーション(または4Xより大きなバッチサイズ)2Xより多いトレーニングイテレーションと2Xより大きなモデル4Xより大きなモデル- エンコーダデコーダトランスフォーマーのアンサンブルをトレーニングする
ここでは、簡単のために事前トレーニングとファインチューニングのステップを増やしています。これらの実験の結果は以下に示されています。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*KhbKImG2TLomLHgW.png)
これらの結果はおおよそ予想通りです。トレーニング時間(またはバッチサイズ)を増やすと性能が向上します。さらに、これを大きなモデルと組み合わせることは、トレーニングイテレーションまたはバッチサイズを単独で増やすよりもさらなる利益をもたらします。言い換えれば、事前トレーニングデータの量とモデルサイズを増やすことは、性能向上の観点で補完的です。
「機械学習の研究の苦い教訓は、追加の計算を活用できる一般的な方法が、人間の専門知識に頼る方法に対して最終的に勝利する」と[1]から引用
その他の内容。 T5は、異なるマルチタスクトレーニング戦略を使用してファインチューニングされています。全体的には、これらのモデルは、各タスクごとに個別にファインチューニングされたモデルよりもわずかに性能が劣ることがわかっています。ただし、タスク固有のファインチューニングとマルチタスク学習のパフォーマンス差を最小化するための戦略は存在します。詳細については、こちらの概要をご覧ください。
ディープニューラルネットのファインチューニング手法の多くは、モデルの一部のパラメータのみをトレーニングします(例:モデルの初期レイヤーを「凍結」し、モデルの最後の数層のみをファインチューニングします)。[1]の著者たちは、このような方法でT5をファインチューニングするためのいくつかの技術を試しています(例:アダプターレイヤーや段階的なアンフリージング[6]を使用)。しかし、これらの方法は、モデル全体を終端から終端までファインチューニングする方法によって上回られます。以下を参照してください。
![(from [1])](https://miro.medium.com/v2/resize:fit:640/format:webp/0*x4PEONPjx2mqbb9h.png)
T5:すべてをまとめる!
[1]の実験的分析全体を見てきたので、NLPにおける転移学習のさまざまなオプションと、最も効果的な方法についてより良い理解ができました!以下では、T5が使用する公式の転移学習フレームワークを構成するこの分析からの主なポイントを見ていきます。このアプローチは、さまざまな代替手法と比較してかなり良いパフォーマンスを発揮することがわかりました。
ベースライン設定。まず、T5のベースラインアーキテクチャを思い出しましょう。これは、統一されたテキスト対テキスト形式を使用してトレーニングされるエンコーダーデコーダートランスフォーマーです。ノイズ除去の目的で事前トレーニングを行った後、モデルは各ダウンストリームタスクごとに個別にファインチューニングされ、評価されます。特に、GLUEおよびSuperGLUEベンチマークの各タスクについて、最終的なT5モデルは個別にファインチューニングされます(過学習を回避するために必要な手順を踏むと仮定)。
事前トレーニング。均一にトークンを選択する代わりに、最終的なT5の手法ではスパンの破損(つまり、一度に複数のトークンのスパンを破損する)が行われます。平均的な長さは3です。それにもかかわらず、15%のトークンが破損の対象となります。この目標は、ベースラインよりもわずかに優れた性能を発揮し、より短いターゲットシーケンスの長さを提供します。さらに、T5は非監督事前トレーニングの更新とマルチタスク監督トレーニングの更新を混在させます。非監督トレーニングと監督トレーニングの更新の数の比率は、使用されるモデルのサイズに依存します(つまり、より大きなモデルでは、過学習を避けるためにより多くの非監督トレーニングが必要です)。
トレーニング量。追加の事前トレーニングはT5のパフォーマンスに役立ちます。具体的には、バッチサイズとトレーニングイテレーションの数を増やすことはT5のパフォーマンスに有益です。したがって、最終的なT5モデルは合計1Tのトークンで事前トレーニングされます。これは、ベースラインの34Bのトークンに比べてはるかに大きいですが、RoBERTa [12]に比べると遥かに少なく、RoBERTaは2.2Tのトークン以上で事前トレーニングされています。タスク固有の事前トレーニングは、異なるタスク間で一貫した利益をもたらしません。
モデルスケール。より大きなモデルを使用することは有益ですが、時にはより小さなモデルの方が適している場合もあります(例:推論用の利用可能な計算リソースが限られている場合)。そのため、T5モデルは220Mから11Bのパラメータを持つ5つの異なるサイズでリリースされています。したがって、T5は実際にはさまざまなモデルのスイートです!こちらのリンクからこれらのモデルにアクセスできます。
締めの言葉
この記事をお読みいただきありがとうございます。私はRebuyのAIディレクターであるCameron R. Wolfeです。私はディープラーニングの実証的および理論的な基盤を研究しています。VoAGIでも他の記事をご覧いただけます!気に入っていただけた場合は、Twitterでフォローするか、Deep (Learning) Focus ニュースレターに登録してください。ここでは、人気のある論文のわかりやすい概要を通じて、読者がAI研究のトピックをより深く理解できるようお手伝いします。
参考文献
[1] Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” The Journal of Machine Learning Research 21.1 (2020): 5485–5551.
[2] Liu, Peter J., et al. “Generating wikipedia by summarizing long sequences.” arXiv preprint arXiv:1801.10198 (2018).
[3] Liu, Peter J., Yu-An Chung, and Jie Ren. “Summae: Zero-shot abstractive text summarization using length-agnostic auto-encoders.” arXiv preprint arXiv:1910.00998 (2019).
[4] Song, Kaitao, et al. “Mass: Masked sequence to sequence pre-training for language generation.” arXiv preprint arXiv:1905.02450 (2019).
[5] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[6] Howard, Jeremy, and Sebastian Ruder. “Universal language model fine-tuning for text classification.” arXiv preprint arXiv:1801.06146 (2018).
[7] Wang, Alex, et al. “GLUE: A multi-task benchmark and analysis platform for natural language understanding.” arXiv preprint arXiv:1804.07461 (2018).
[8] Wang, Alex, et al. “Superglue: A stickier benchmark for general-purpose language understanding systems.” Advances in neural information processing systems 32 (2019).
[9] Hermann, Karl Moritz, et al. “Teaching machines to read and comprehend.” Advances in neural information processing systems 28 (2015).
[10] Rajpurkar, Pranav, et al. “Squad: 100,000+ questions for machine comprehension of text.” arXiv preprint arXiv:1606.05250 (2016).
[11] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[12] Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” arXiv preprint arXiv:1907.11692 (2019).
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Magic123とは、高品質で高解像度の3Dジオメトリとテクスチャを生成するために、二段階の粗-細最適化プロセスを使用する新しい画像から3Dへのパイプラインです
- スキル開発のための集中的な機械学習ブートキャンプ
- Google AIがFlan-T5をオープンソース化 NLPタスクにおいてテキスト対テキストアプローチを使用するトランスフォーマーベースの言語モデル
- 次元をパンプアップせよ:DreamEditorは、テキストプロンプトを使って3Dシーンを編集するAIモデルです
- NODE:表形式に特化したニューラルツリー
- 小さな言語モデルでも高い性能を発揮できるのか?StableLMに会ってみてください:適切なトレーニングで高性能なテキストとコードを生成できるオープンソースの言語モデル
- 大規模言語モデル(LLM)とは何ですか?LLMの応用と種類