データ体験の再発明:生成的AIと現代的なデータアーキテクチャを使用して、洞察を解き放つ
Revolutionizing Data Experience Unleashing Insights with Generative AI and Modern Data Architecture.
現代的なデータアーキテクチャを実装することで、異なるソースからのデータを統合するためのスケーラブルな方法が提供されます。インフラストラクチャではなくビジネスドメインごとにデータを整理することにより、各ドメインは必要に応じたツールを選択できます。企業はジェネレーティブAIソリューションを活用することで、現代的なデータアーキテクチャの価値を最大限に引き出しながら、持続的なイノベーションを実現することができます。
自然言語の機能により、非技術的なユーザーでも複雑なSQLではなく会話英語を使用してデータをクエリできます。しかし、完全な利点を実現するにはいくつかの課題を克服する必要があります。AIと言語モデルは適切なデータソースを識別し、効果的なSQLクエリを生成し、スケーラブルな形で組み込まれた結果を含む整合的な応答を生成する必要があります。また、自然言語の質問に対するユーザーインターフェイスも必要です。
全体として、AWSを使用した現代的なデータアーキテクチャとジェネレーティブAI技術を実装することは、企業スケールで多様な膨大なデータから重要な洞察を得るための有望な手段です。AWSからの最新のジェネレーティブAIオファリングであるAmazon Bedrockは、完全に管理されたサービスであり、基盤モデルを使用してジェネレーティブAIアプリケーションを構築しスケールする最も簡単な方法です。AWSはAmazon SageMaker JumpStartを介して基盤モデルを提供し、Amazon SageMakerエンドポイントとしても使用できます。大規模な言語モデル(LLMs)の組み合わせ(Amazon Bedrockが提供する統合の容易さを含む)とスケーラブルなドメイン指向のデータインフラストラクチャは、さまざまな分析データベースやデータレイクに保持されている豊富な情報にアクセスするための知的な方法として位置付けられています。
この記事では、企業が複数のデータベースやAPIにデータがあり、Amazon Simple Storage Service(Amazon S3)で法的データ、Amazon Relational Database Service(Amazon RDS)で人事、Amazon Redshiftで販売とマーケティング、サードパーティのデータウェアハウスソリューションであるSnowflakeで金融市場データ、APIで製品データを利用しているシナリオを紹介しています。この実装は、ビジネスアナリティクス、製品所有者、ビジネスドメインエキスパートの生産性を向上させることを目的としています。これらすべては、このドメインメッシュアーキテクチャでジェネレーティブAIを使用することにより実現されます。これにより、企業はより効率的にビジネス目標を達成できます。このソリューションには、JumpStartからSageMakerエンドポイントとしてLLMsを含めるオプションがあり、サードパーティのモデルも使用できます。これにより、企業ユーザーは、単純な複雑なSQLクエリを書く複雑さを抽象化することなく、ファクトベースの質問をすることができます。
ソリューション概要
AWS上の現代的なデータアーキテクチャは、人工知能と自然言語処理を用いて複数のアナリティクスデータベースをクエリします。Amazon Redshift、Amazon RDS、Snowflake、Amazon Athena、AWS Glueなどのサービスを使用することで、異なるソースからのデータを統合するスケーラブルなソリューションが作成されます。LangChainを使用することで、Amazon BedrockやJumpStartからの基盤モデルを含むLLMsを扱う強力なライブラリを使用して、ユーザーは自然な英語でビジネスの質問をすることができ、関連するデータからデータを引き出して回答を受け取ることができます。
次の図は、アーキテクチャを示しています。
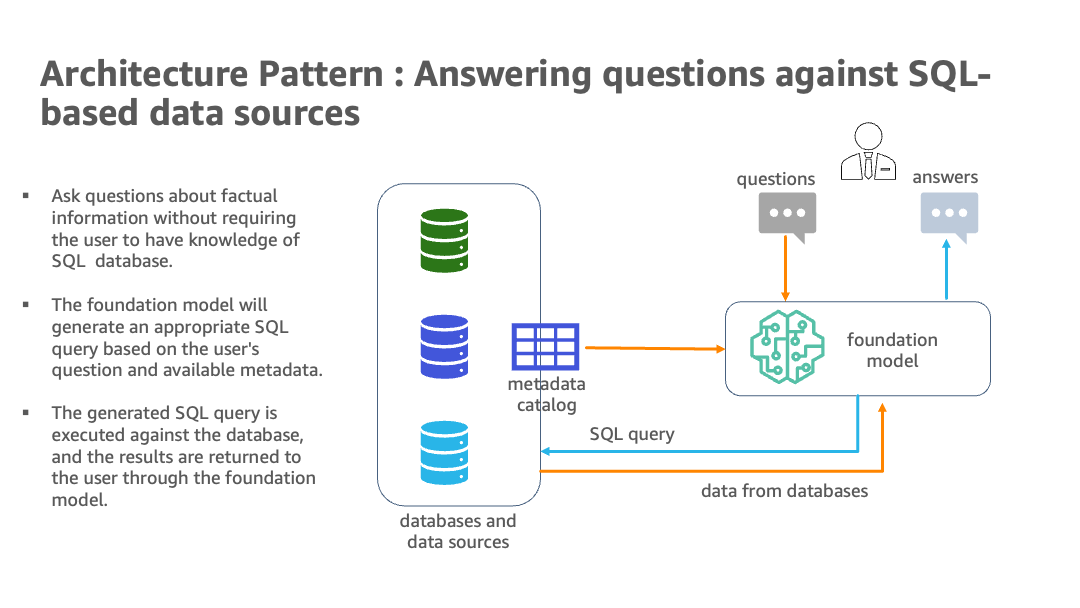
ハイブリッドアーキテクチャは、複数のデータベースとLLMsを使用し、Amazon BedrockやJumpStartからの基盤モデルを使用して、データソースの識別、SQL生成、結果を含むテキスト生成を行います。
次の図は、当社のソリューションの具体的なワークフロー手順を示しています。
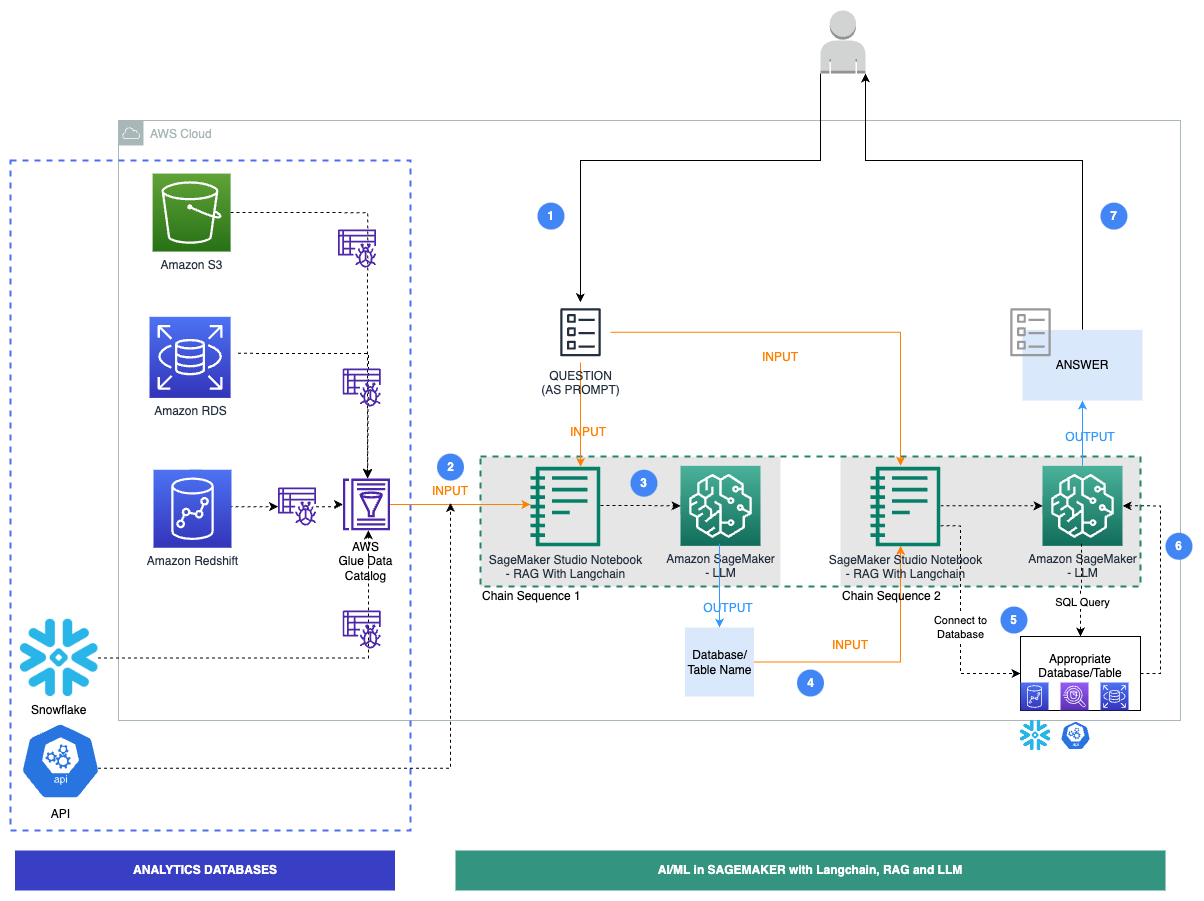
手順は以下のとおりです:
- ビジネスユーザーが英語の質問プロンプトを提供します。
- AWS Glueクローラは頻繁な間隔で実行され、データベースからメタデータを抽出してAWS Glue Data Catalogのテーブル定義を作成します。Data CatalogはChain Sequence 1の入力となります(前の図を参照)。
- StudioノートブックでLLMsとプロンプトを扱うLangChainを使用します。LangChainでは、LLMを定義する必要があります。Chain Sequence 1の一部として、プロンプトとData CatalogメタデータがLLMに渡され、LangChainを使用して関連するデータベースとテーブルを識別します。
- プロンプトと識別されたデータベースとテーブルがChain Sequence 2に渡されます。
- LangChainはデータベースに接続し、SQLクエリを実行して結果を取得します。
- 結果はLLMに渡され、データを含む英語の回答が生成されます。
- ユーザーは、異なるデータベースからのデータをクエリして英語の回答を受け取ります。
以下のセクションでは、関連するコードとともに主要なステップの説明を行います。ここで示されるすべてのステップの解決策とコードについて深く掘り下げるには、GitHubリポジトリを参照してください。以下の図は、実行されたステップのシーケンスを示しています。

前提条件
LLMsとLangChainによるレスポンスの生成に互換性のあるSQLAlchemyに準拠したいかなるデータベースを使用することができます。ただし、これらのデータベースはAWS Glue Data Catalogにメタデータが登録されている必要があります。また、JumpStartまたはAPIキーを使用してLLMsにアクセスする必要があります。
SQLAlchemyを使用してデータベースに接続する
LangChainはSQLAlchemyを使用してSQLデータベースに接続します。LangChainのSQLDatabase関数を初期化するために、各データソースに対してエンジンを作成し、接続を確立します。以下は、Amazon Aurora MySQL互換のサーバーレスデータベースに接続し、従業員テーブルのみを含める方法のサンプルです。
#connect to AWS Aurora MySQL
cluster_arn = <cluster_arn>
secret_arn = <secret_arn>
engine_rds=create_engine('mysql+auroradataapi://:@/employees',echo=True,
connect_args=dict(aurora_cluster_arn=cluster_arn, secret_arn=secret_arn))
dbrds = SQLDatabase(engine_rds, include_tables=['employees'])次に、Chain Sequence 1で使用されるプロンプトを構築し、ユーザーの質問に基づいてデータベースとテーブル名を識別します。
動的プロンプトテンプレートの生成
メタデータ情報を保存および管理するために設計されたAWS Glue Data Catalogを使用して、ユーザークエリのデータソースを特定し、Chain Sequence 1のプロンプトを構築します。以下の手順で詳細に説明します。
- JDBC接続を使用して、複数のデータソースのメタデータをクロールしてデータカタログを構築します。
- Boto3ライブラリを使用して、複数のデータソースからデータカタログの総合ビューを作成します。次は、Aurora MySQLデータベースのemployeesテーブルのメタデータをデータカタログから取得する方法のサンプルです。
#retrieve metadata from glue data catalog
glue_tables_rds = glue_client.get_tables(DatabaseName=<database_name>, MaxResults=1000)
for table in glue_tables_rds['TableList']:
for column in table['StorageDescriptor']['Columns']:
columns_str=columns_str+'\n'+('rdsmysql|employees|'+table['Name']+"|"+column['Name'])総合データカタログには、スキーマ、テーブル名、列名などのデータソースの詳細が含まれています。以下は、総合データカタログの出力のサンプルです。
database|schema|table|column_names
redshift|tickit|tickit_sales|listid
rdsmysql|employees|employees|emp_no
....
s3|none|claims|policy_id- 総合データカタログをプロンプトテンプレートに渡し、LangChainで使用されるプロンプトを定義します。
prompt_template = """
From the table below, find the database (in column database) which will contain the data (in corresponding column_names) to answer the question {query} \n
"""+glue_catalog +""" Give your answer as database == \n Also,give your answer as database.table =="""Chain Sequence 1: LangChainとLLMを使用してユーザークエリのソースメタデータを検出する
前のステップで生成されたプロンプトテンプレートとユーザークエリをLangChainモデルに渡し、最適なデータソースを見つけるためにLangChainがLLMモデルを使用してソースメタデータを検出します。
JumpStartまたはサードパーティのモデルからLLMを使用するには、以下のコードを使用してください。
#define your LLM model here
llm = <LLM>
#pass prompt template and user query to the prompt
PROMPT = PromptTemplate(template=prompt_template, input_variables=["query"])
# define llm chain
llm_chain = LLMChain(prompt=PROMPT, llm=llm)
#run the query and save to generated texts
generated_texts = llm_chain.run(query)生成されたテキストには、ユーザーのクエリが実行されるデータベースやテーブル名などの情報が含まれています。たとえば、「今月生年月日を持つすべての従業員の名前を挙げる」というユーザークエリの場合、generated_text には database == rdsmysql および database.table == rdsmysql.employees の情報が含まれています。
次に、人事領域、Aurora MySQLデータベース、および従業員テーブルの詳細を Chain Sequence 2 に渡します。
Chain Sequence 2: データソースからユーザークエリに回答するためのレスポンスを取得する
次に、LangChain のSQLデータベースチェーンを実行して、テキストをSQLに変換し、暗黙的に生成されたSQLをデータベースに実行して、シンプルで読みやすい言語でデータベースの結果を取得します。
まず、LLM に SQL を生成するための構文的に正しいダイアレクトを指示し、その後、データベースに対して実行する問い合わせの結果を確認して回答を返すためのプロンプトテンプレートを定義します。
_DEFAULT_TEMPLATE = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Only use the following tables:
{table_info}
If someone asks for the sales, they really mean the tickit.sales table.
Question: {input}"""
#define the prompt
PROMPT = PromptTemplate( input_variables=["input", "table_info", "dialect"], template=_DEFAULT_TEMPLATE)最後に、LLM、データベース接続、およびプロンプトを SQL データベースチェーンに渡して SQL クエリを実行します。
db_chain = SQLDatabaseChain.from_llm(llm, db, prompt=PROMPT)
response=db_chain.run(query)たとえば、「今月生年月日を持つすべての従業員の名前を挙げる」というユーザークエリの場合、回答は次のようになります。
Question: Name all employees with birth date this month
SELECT * FROM employees WHERE MONTH(birth_date) = MONTH(CURRENT_DATE());
User Response:
The employees with birthdays this month are:
Christian Koblick
Tzvetan Zielinskiクリーンアップ
ジェネラティブAIを利用したモダンなデータアーキテクチャを実行した後は、使用しないリソースをクリーンアップしてください。使用したデータベース(Amazon Redshift、Amazon RDS、Snowflake)をシャットダウンして削除し、Amazon S3のデータを削除し、Studioノートブックインスタンスを停止して追加料金が発生しないようにしてください。SageMakerリアルタイムエンドポイントとしてLLMを展開するためにJumpStartを使用した場合は、SageMakerコンソールまたはStudioを介してエンドポイントを削除してください。
結論
この記事では、SageMaker内でモダンなデータアーキテクチャとジェネラティブAI、LLMを統合しました。このソリューションは、JumpStartからのさまざまなテキスト-テキストファンデーションモデルとサードパーティモデルを使用しています。このハイブリッドアプローチは、データソースを特定し、SQLクエリを書き込み、クエリ結果で回答を生成します。Amazon Redshift、Amazon RDS、Snowflake、LLMを使用しています。このソリューションを改善するには、より多くのデータベース、英語クエリ用のUI、プロンプトエンジニアリング、およびデータツールを追加することができます。これにより、複数のデータストアからの洞察を取得するための知的で統一された方法となります。この記事で示されたソリューションとコードについて詳しくは、GitHubリポジトリをチェックしてください。また、ジェネラティブAI、ファンデーションモデル、および大規模言語モデルに関するユースケースについては、Amazon Bedrockを参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
