人間の注意力を予測するモデルを通じて、心地よいユーザーエクスペリエンスを実現する
Realize a pleasant user experience through a model that predicts human attention.
Google Researchのシニアリサーチサイエンティスト、Junfeng He氏とスタッフリサーチサイエンティスト、Kai Kohlhoff氏による記事です。
人間は、驚くほど多くの情報を取り入れる能力を持っています(網膜に入る情報は秒間約10 10ビット)。そして、タスクに関連し、興味深い領域に選択的に注目し、さらに処理する能力を持っています(例:記憶、理解、行動)。人間の注意(その結果として得られるものはしばしば注目モデルと呼ばれます)をモデル化することは、神経科学、心理学、人間コンピュータインタラクション(HCI)、コンピュータビジョンの分野で興味を持たれてきました。どの領域でも、どの領域でも、注目が集まる可能性が高い領域を予測する能力には、グラフィックス、写真、画像圧縮および処理、視覚品質の測定など、多数の重要な応用があります。
以前、機械学習とスマートフォンベースの注視推定を使用して、以前は1台あたり3万ドルにも及ぶ専門的なハードウェアが必要だった視線移動の研究を加速する可能性について説明しました。関連する研究には、「Look to Speak」というアクセシビリティニーズ(ALSのある人など)を持つユーザーが目でコミュニケーションするのを支援するものと、「Differentially private heatmaps」という、ユーザーのプライバシーを保護しながら注目のようなヒートマップを計算する技術が最近発表されました。
このブログでは、私たちはCVPR 2022からの1つの論文と、CVPR 2023での採用が決定したもう1つの論文、「Deep Saliency Prior for Reducing Visual Distraction」と「Learning from Unique Perspectives: User-aware Saliency Modeling」を紹介します。さらに、画像圧縮のための注目駆動型プログレッシブローディングに関する最近の研究(1,2)も紹介します。人間の注意の予測モデルが、画像編集による視覚的な混乱、気散らし、アーティファクトの最小化、Webページやアプリの高速ロードのための画像圧縮、およびより直感的な人間らしい解釈とモデルパフォーマンスへのMLモデルの誘導のような、素晴らしいユーザー体験を可能にする方法を紹介します。私たちは画像編集と画像圧縮に焦点を当て、これらのアプリケーションの文脈でのモデリングの最近の進歩について説明します。
- デジタルルネッサンス:NVIDIAのNeuralangelo研究が3Dシーンを再構築
- NYUとNVIDIAが協力して、患者の再入院を予測するための大規模言語モデルを開発する
- NVIDIAリサーチがCVPRで自律走行チャレンジとイノベーション賞を受賞
注目による画像編集
人間の注意モデルは通常、画像を入力として受け取り(例:自然画像またはWebページのスクリーンショット)、出力としてヒートマップを予測します。画像上の予測されたヒートマップは、注目データのグラウンドトゥルースと評価されます。これらのデータは通常、アイ・トラッカーによって収集されるか、マウスのホバリング/クリックによって近似されます。以前のモデルでは、色/明度のコントラスト、エッジ、形状などの視覚的手がかりに手作りの特徴を活用し、より最近のアプローチでは、畳み込みニューラルネットワーク、再帰ニューラルネットワークから最近のビジョントランスフォーマーネットワークに基づく識別的特徴を自動的に学習します。
「Deep Saliency Prior for Reducing Visual Distraction」(このプロジェクトサイトでの詳細については、こちらをご覧ください)では、深い注目モデルを利用して、視覚的にリアルな編集を行い、観察者の異なる画像領域への注意を大幅に変更できます。たとえば、背景の邪魔なオブジェクトを削除することで、写真の混雑が減り、ユーザーの満足度が向上することがあります。同様に、ビデオ会議では、背景の混雑を減らすことで、主要なスピーカーに焦点が合うようになる場合があります(こちらのデモをご覧ください)。
どのような編集効果が実現できるか、およびこれらが視聴者の注意にどのように影響するかを探るために、異なる可能性を探るための最適化フレームワークを開発しました。これは、微分可能で予測可能な注目モデルを使用して画像の視覚的な注目を誘導するためのものです。当社の方法は、最新の深い注目モデルを利用しています。入力画像と、不要な領域を表すバイナリマスクが与えられた場合、マスク内のピクセルは、マスクされた領域内の注目度が低下するように、予測注目モデルのガイダンスの下で編集されます。編集された画像が自然でリアルであることを確認するために、4つの画像編集オペレータを慎重に選択しました。2つは標準的な画像編集操作で、再色付けと画像変形(シフト)です。残りの2つは学習されたオペレータで、多層畳み込みフィルターと生成モデル(GAN)です(編集操作を明示的に定義しません)。
これらのオペレータを使用することで、図に示すように、再色付け、インペインティング、カモフラージュ、オブジェクトの編集または挿入、および顔属性の編集など、多様な効果を生み出すことができます。重要なことは、これらすべての効果が、追加の監視またはトレーニングなしに、単一の事前トレーニングされた注目モデルだけで駆動されることです。これらすべての効果を生み出すための専用方法と競合することが目的ではなく、複数の編集操作が、深い注目モデルに埋め込まれた知識によってガイドされる方法を示すことが目的です。
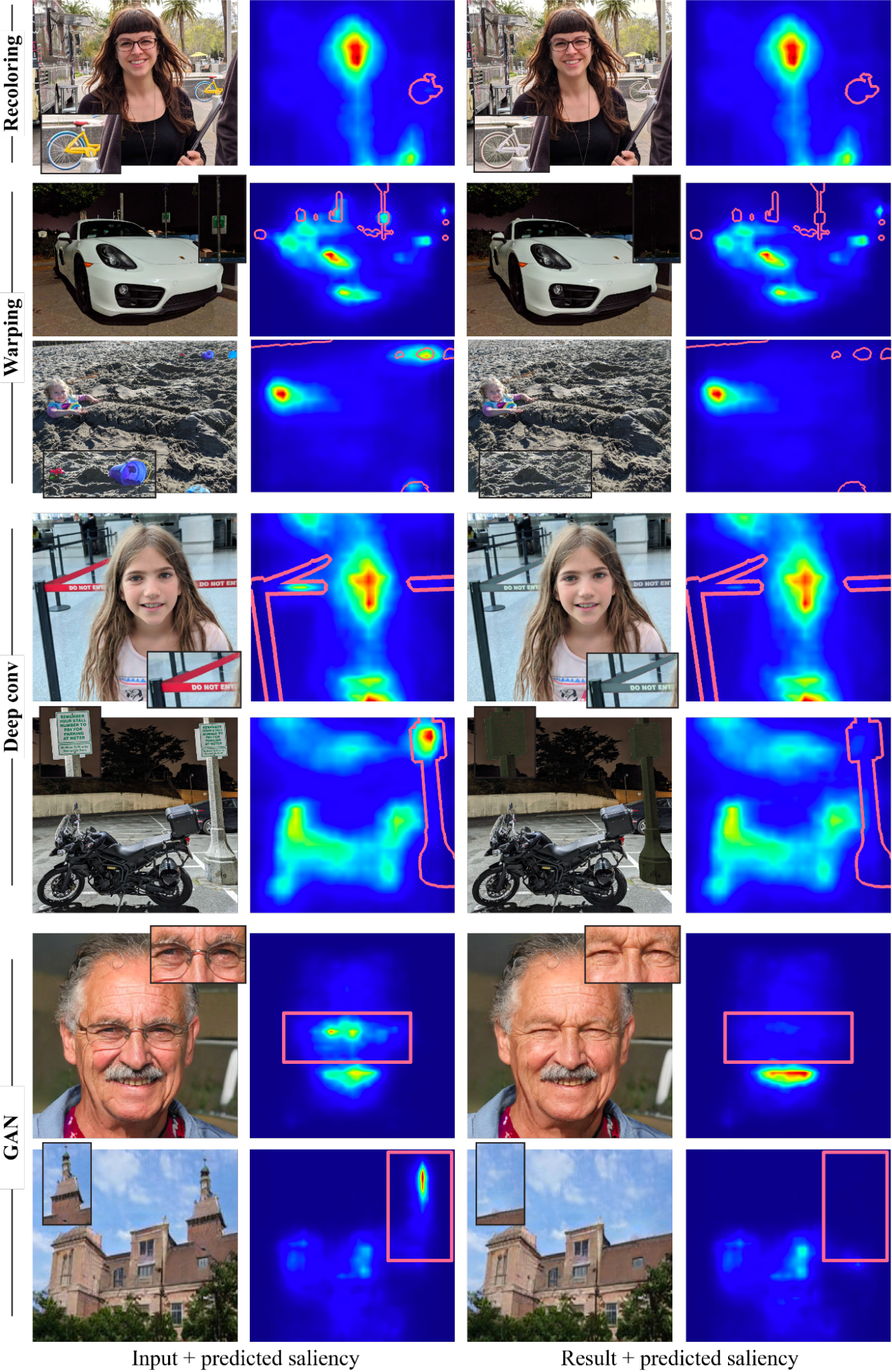 |
| 複数のオペレータによる注目の削減の例。各例では、注目マップ上の不要な領域(赤枠)がマークされています。 |
ユーザ意識型注目度モデルによる体験の豊かさ
以前の研究では、人間の注目は一般的に同じモデルに基づいているとされてきました。しかし、人間の注目は個人によって異なり、注目すべき重要なポイントの検出は比較的一貫していますが、その順序、解釈、注目分布には大きな違いがあります。これにより、個人またはグループのためにパーソナライズされたユーザ体験を作成する機会が生まれます。「ユニークな視点から学ぶ:ユーザ意識型注目度モデリング」では、ユーザ意識型注目度モデルを紹介し、1つのモデルで1つのユーザ、複数のユーザ、および一般の人々の注目を予測する最初のモデルとなりました。
以下の図に示すように、モデルの中心には、それぞれの参加者のビジュアルの好みと、ユーザごとの注目度マップと適応的なユーザマスクの組み合わせがあります。これには、トレーニングデータでユーザごとの注目アノテーションが必要であり、例えば自然画像のOSIEモバイルゲイズデータセット、WebページのFiWIおよびWebSaliencyデータセットなどがあります。このモデルは、すべてのユーザの注目を表す単一の注目度マップを予測する代わりに、個々の注目パターンをエンコードするために、ユーザごとの注目度マップを予測します。さらに、モデルは、参加者の存在を示すユーザマスク(参加者の数と同じサイズのバイナリベクトル)を採用し、複数の参加者を選択して彼らの好みを単一のヒートマップに組み合わせることができます。
 |
| ユーザ意識型注目度モデルの概要図。例としてOSIE画像セットの画像が使用されています。 |
推論中、ユーザマスクにより、参加者の任意の組み合わせについて予測を行うことができます。以下の図では、最初の2行は画像の2つの異なるグループ(それぞれ3人のグループ)に対する注目予測です。従来の注目予測モデルは、同じ注目ヒートマップを予測します。しかし、私たちのモデルは、2つのグループを区別することができます(例えば、2つめのグループは、1つめのグループよりも顔に注目することが少なく、食べ物に注目することが多い)。同様に、最後の2行は、私たちのモデルが異なる嗜好を示す2人の異なる参加者に対するウェブページの予測です(例えば、2番目の参加者は、1番目の参加者よりも左側の領域に注目することが多い)。
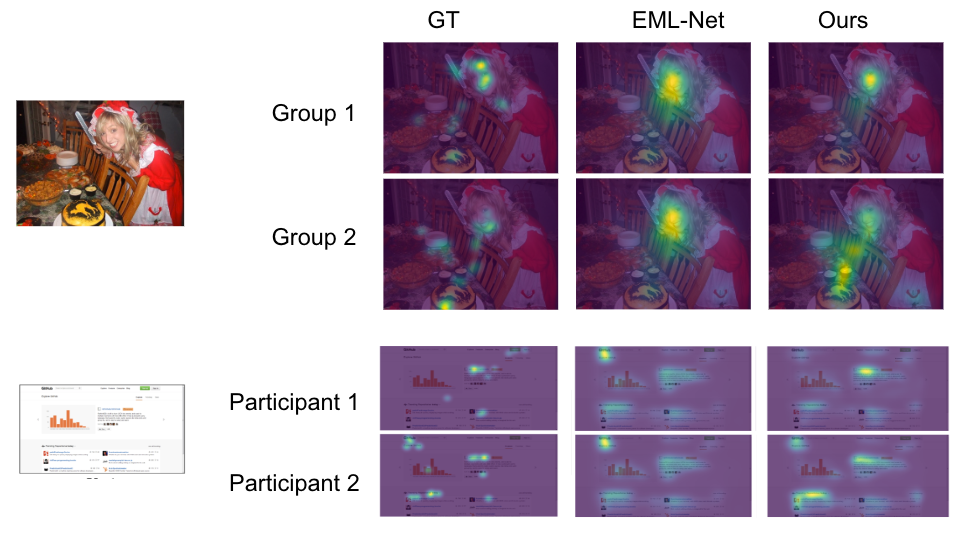 |
| 予測された注目度とグラウンドトゥルース(GT)の比較。EML-Net:最先端のモデルからの予測であり、2つの参加者/グループに対して同じ予測が行われます。Ours:私たちが提案するユーザ意識型注目度モデルからの予測であり、各参加者/グループの独自の嗜好を正確に予測することができます。1枚目の画像はOSIE画像セットから、2枚目の画像はFiWIからです。 |
注目度に基づくプログレッシブ画像デコーディング
画像編集に加えて、人間の注目モデルを使用することで、ユーザのブラウジング体験を改善することができます。画像を含むWebページの読み込みを待つことが最もイライラするユーザ体験の1つです。特に低速ネットワーク接続の場合は、ユーザ体験を改善する方法の1つは、画像のプログレッシブデコードです。データがダウンロードされるにつれて、徐々に高解像度の画像セクションをデコードして表示し、最終的にフル解像度の画像を表示します。プログレッシブデコードは通常、順次処理されます(例:左から右に、上から下に)。予測注目度モデル(1、2)を使用すると、注目度に基づいて画像をデコードすることができるため、最も重要な領域の詳細を最初に表示するために必要なデータを送信することができます。たとえば、ポートレートでは、背景のぼやけた部分よりも顔のバイトが優先されます。その結果、ユーザはより早く高品質の画像を知覚し、待ち時間が大幅に短縮されます。詳細については、私たちのオープンソースのブログ記事(post 1、post 2)を参照してください。したがって、予測注目度モデルは、画像の圧縮や画像を含むWebページの高速な読み込み、大きな画像やストリーミング/VRアプリケーションのレンダリングの改善に役立ちます。
結論
私たちは、人間の注意力の予測モデルが、画像編集などのアプリケーションを通じて、ユーザーにとってスッキリしたユーザーエクスペリエンスを提供できることを示しました。これにより、ユーザーは画像や写真からの混乱、邪魔な要素、アーティファクトを減らすことができます。また、進行中の画像デコードにより、ユーザーが待ち時間を感じることなく、完全にレンダリングされた画像を楽しめるようになります。また、ユーザーに配慮した注目モデルにより、個人やグループに合わせた上記のアプリケーションのパーソナライズが可能になり、より豊かでユニークな体験ができます。
予測的な注意モデルのもう一つの興味深い方向性は、物体の分類や検出などのコンピュータビジョンモデルの堅牢性向上に役立つかどうかです。たとえば、「Teacher-generated spatial-attention labels boost robustness and accuracy of contrastive models」という論文では、予測的な人間の注意モデルが、コントラスト学習モデルを導くことで、イメージネットやイメージネットCなどの分類タスクの精度/堅牢性を向上させることができることを示しています。この方向性のさらなる研究により、放射線科医の医療画像での注目度を使用して健康スクリーニングや診断を改善する、複雑な運転シナリオでの人間の注目を使用して自動運転システムを誘導するなどのアプリケーションが可能になる可能性があります。
謝辞
この研究は、ソフトウェアエンジニア、研究者、クロスファンクショナルな貢献者からなる多様なチームの共同作業によって行われました。私たちは、論文/研究の共同著者であるKfir Aberman、Gamaleldin F. Elsayed、Moritz Firsching、Shi Chen、Nachiappan Valliappan、Yushi Yao、Chang Ye、Yossi Gandelsman、Inbar Mosseri、David E. Jacobes、Yael Pritch、Shaolei Shen、Xinyu Yeを含め、全員に感謝します。また、私たちは、Oscar Ramirez、Venky Ramachandran、Tim Fujitaなどのチームメンバーに感謝します。最後に、この研究の開始と監督における技術リーダーシップを発揮してくれた Vidhya Navalpakkam に感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





