スターバックスの報酬プログラムの成功を予測する
Predicting the success of Starbucks' rewards program.
初心者向け – スタートからフィニッシュまでの完全なプロジェクトのステップバイステップの説明
プロジェクト概要
このプロジェクトは、Starbucksの現在の顧客を効果的に引き付け、新しい顧客を獲得するための報酬プログラムの提供を特定することに焦点を当てています。
スターバックスは、お客様情報、特別オファー、トランザクションデータを含むデータセットを利用して、お客様の完全な理解を得るために投資するデータ駆動型の企業です。
報酬プログラムの成功を判断するモデルを開発するために、私はプロジェクトを 3つの段階に分けました:
- Udacityが提供したデータを検査およびクリーニングする。
- すべての関連情報を結合するデータセットの作成。
- 3つの分類モデルを構築し、報酬プログラムの成功または失敗を予測するために
問題設定
マーケティングキャンペーンに大きな投資をすることは、さまざまなステークホルダー、財源、および時間から承認を得る複雑な決定です。したがって、特定のターゲットグループに特定のオファーを打ち出すことが有益かどうかを分類できる予測モデルを持つことは、どの企業にとっても戦略的な資産になります。
このモデルを作成するために、バイナリ分類のための教師あり学習技術を使用します。
モデルの結果は、オファーが有効かどうかを示します。
データセットの探索と整理
Udacityは、JSON形式の3つのデータセット、portfolio、profile、およびtranscriptを提供しています。各データセットは異なる目的を持ち、分析に貴重な情報を提供します。
ポートフォリオデータセット
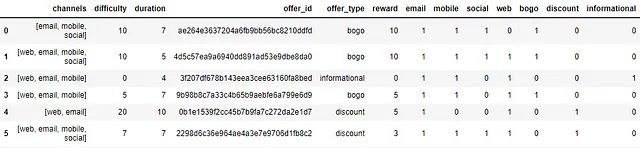
このデータセットは、Starbucksで利用可能なアクティブなオファーに関する情報を提供します。
- id(文字列) — オファーID
- offer_type(文字列) — BOGO、割引、情報などのオファータイプ
- difficulty(int) — オファーを完了するために必要な最小支出
- reward(int) — オファーを完了した場合の報酬
- duration(int) — オファーが開いている期間(日数)
- channels(文字列のリスト)

ポートフォリオデータセットには10行6列があります。欠損値、null、または重複値はありません。
’channels’、‘id’、‘offer_type’列はカテゴリカルであり、‘difficulty’、‘duration’、‘reward’は整数です。
以下は、データセットで行った変更の概要です:
- ’channels’と‘offer_type’をワンホットエンコードする
- ‘id’を‘offer_id’に変更する
プロフィールデータセット
プロフィールデータセットには、スターバックスの顧客に関する人口統計情報が含まれています。
- age(int) — 顧客の年齢
- became_member_on(int) — 顧客がアプリアカウントを作成した日付
- gender(str) — 顧客の性別(一部のエントリーには、MまたはFではなく「O」が含まれていることに注意してください)
- id(str) — 顧客ID
- income(float) — 顧客の収入
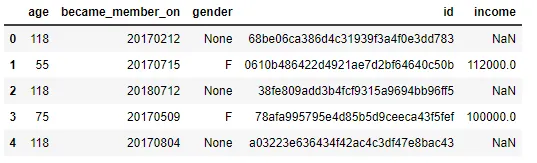
このデータセットには、2175のヌル項目(genderおよびincome列の両方に)が含まれ、このデータセットのユニークな人数は17000行、5列です。これらの行の年齢値も118であるため、私はデータセットから2175行すべてを削除しました。
以下に、データセットに行った変更内容を示します。
- 欠損値(118の年齢値を持つものも含む)を持つ2175行を削除
- ‘id’を‘customer_id’に変更
- ‘become_member_on’文字列から日付への変換
- ‘year_joined’および‘membership_days’列の作成
- ‘gender’のワンホットエンコーディング
- ‘age_group’の作成(teenager, young-adult, adult, elderlyの顧客を分類するため)
- ‘income_range’の作成(average, above-average, highの顧客を分類するため)
- ‘member_type’の作成(new, regular, loyalの顧客を分類するため)

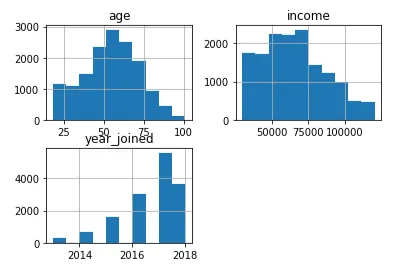
2013年から2017年の間に、プログラムに参加する人の数は増加傾向にあり、2017年が最高の年であることがわかります。メンバーの50%は42歳から66歳の間です。
下のグラフから、男性の人口が女性の人口を下回る低収入層と平均収入層では、男性の人口が女性の人口を上回っていることがわかります。一方、高収入層では女性の人口が男性の人口を上回っています。
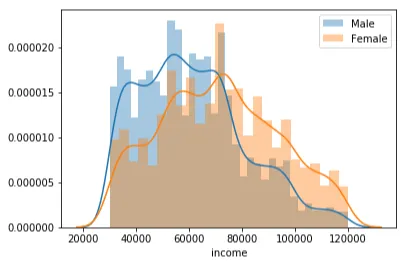
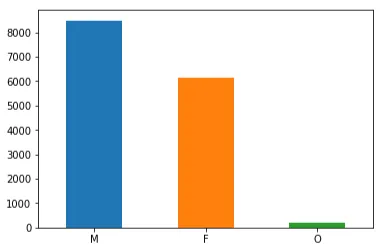
性別を考慮すると、データセットはやや偏っていると言えます。男性の人口が女性の人口を上回り、その他のカテゴリーの人口はわずかです。具体的には、データセットには8484人の男性、6129人の女性、212人のその他が含まれています。
トランスクリプトデータセット
トランスクリプトデータセットは、顧客がオファーとの相互作用を捉えています。
- event (str) — レコードの説明(トランザクション、オファーの受信、オファーの閲覧など)
- person (str) — 顧客ID
- time (int) — テスト開始からの時間(時間単位)。データはt=0で開始します。
- value — (dict of strings) — レコードに応じてオファーIDまたはトランザクション金額が含まれます
トランスクリプトデータセットのイベントが、3つの可能なオファーステータス(閲覧、受信、完了)のいずれかに対応する場合、value列にはオファーのidが含まれます。オファーIDに加えて、イベントが‘オファー完了’ステータスの場合は報酬値も含まれます。
ただし、イベントがトランザクションの場合、value列にはトランザクション金額のみが表示されます。
以下は、データセットに対して行った変更の概要です:
- ‘value’ を ‘offer_id’ 、 ‘amount’ 、 ‘rewards’ の新しい列に展開する
- ‘time’ (時間)を日にちに変換して‘time_in_days’を作成する
- ‘person’ を ‘customer_id’に変更する
- transcript データセットを offer_tr(オファーデータ)と transaction_tr(トランザクションデータ)の2つのサブデータセットに分割する
モデルの構築
データセットをクリーンアップし、必要な変更を行った後、2つのデータセットを組み合わせて1つのデータセットにする必要があります。その後、offer_successfulという新しい列を作成します。この列は、特定の顧客にとってオファーが成功したかどうかを示します。これにより、特定タイプの顧客に対して、特定のオファーが成功するかどうかを予測するモデルを構築できるようになります。
オファーが成功するには、顧客が許容時間内にオファーを閲覧し、完了する必要があります。私は、完了して閲覧されたオファーデータと、それらのイベント間の時間範囲を考慮して、目標値を計算するサポート関数を開発しました。
オファーが成功するかどうかを予測できるモデルを作成するには、最終的なデータセットでモデルをトレーニングする必要があります。
成功したオファーと失敗したオファーの数は、それぞれ35136と31365です。ターゲットを考慮したバランスのとれたデータセットを持っているため、モデルの選択に関する制限はありません。
これは、バイナリ分類問題であるため、3つの異なる教師あり学習アルゴリズムを使用します。
- ロジスティック回帰
- ランダムフォレスト
- グラディエントブースティング
計算量が大幅に少ないRandomizedSearchCVを使用して、モデルのハイパーパラメータを最適化するために12回の繰り返しを行います。RandomizedSearchCVは、指定された分布からハイパーパラメータ値をランダムにサンプリングすることによって機能します。
メトリックスと結果
私は以下のメトリックスと混同行列を使用して、モデルのパフォーマンスを評価します。
研究の主目的がポジティブなクラスをできるだけ定義することであるため、精度に特に焦点を当てます。
- 正解率:正解率は、分類モデルの正確さを評価するために最も一般的に使用されるメトリックスです。正しい予測数を総予測数で割って計算されます。
- 適合率:適合率は、モデルがポジティブクラスを予測した場合の正確さを測定するメトリックスです。真陽性数を真陽性数と偽陽性数の合計で割って計算されます。
- 再現率:再現率は、モデルがポジティブクラスを予測した場合の完全性を測定するメトリックスです。真陽性数を真陽性数と偽陰性数の合計で割って計算されます。
- F1値: F1値は、適合率と再現率の加重平均です。2 *(適合率* 再現率)/(適合率+再現率)で計算されます。
結果:
- ロジスティック回帰 ……. → 正解率:0.69、適合率:0.66
- ランダムフォレスト …………. → 正解率:0.70、適合率:0.66
- 勾配ブースティング ……… → 正解率:0.69、適合率:0.66
すべてのモデルが似たようなパフォーマンスメトリックスを提供していますが、ランダムフォレストはわずかに正解率が良くなっています。
結論と改善点
モデルは良好なスタート地点を提供していますが、66%の精度では改善の余地があります。
このプロジェクトの興味深い改善点の1つは、複数の教師あり学習モデルを作成し、カスタムアンサンブルモデルに組み合わせることです。複数の教師あり学習モデルを組み合わせてアンサンブルモデルを作成することで、エラー補償の利点が得られます。異なるモデルの強みを生かし、弱点を補償することにより、アンサンブルモデルはより良い一般化性能を発揮し、精度と堅牢性が向上します。
報酬プログラムの予測精度を高めるために、報酬の種類を分けて、各プログラムごとに個別のモデルを開発することを検討することもできます。これにより、モデリング技術を各報酬プログラムの特性と目標に合わせることができ、より正確な予測とより良い結果につながります。この方法は、各報酬プログラム内のユニークな傾向やパターンを特定するのにも役立ち、より効果的なプログラムの設計と実施につながることができます。
報酬プログラムの効果を最適化する別の方法は、報酬プログラムにかかわらず購入する個人を特定して除外することです。これにより、プログラムの成果に積極的に影響する可能性のある人々にリソースを集中することができ、プログラムから得られる利益を最大化することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
