「プラットプス:データセットのキュレーションとアダプターによる大規模言語モデルの向上」
Platypus Improving Large-scale Language Models through Dataset Curation and Adapters
目標のタスクで低コストの最先端技術を実現する
MetaのLlama 2は1か月前にリリースされ、多くの人々が特定のタスクに合わせて微調整を行っています。同様のトレンドで、ボストン大学はPlatypus(Lee et al.、2023)を提案しています。これは、アダプタと厳選されたデータセットを用いて微調整されたLlama 2です。
Platypusは現在(8月16日)OpenLLMランキングで第1位です。
この研究で提案された手法はあまり新しいものではありません。LoRaアダプタと注意深いデータセットの選別に依存しています。それでも、特化されたアダプタのおかげで、特定のタスクに対してよく整理されたドメイン内データセットを使用することで、(ほぼ)無料で新たな最先端の性能を実現できることは印象的です。
この記事では、Platypusをレビューし、説明します。また、消費者向けハードウェアを使用して同様の結果を実現する方法も紹介します。
- 「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
- 「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
- 「正しい方法で新しいデータサイエンスのスキルを学ぶ」
注:このプロジェクトに取り組んだ当時、QLoRaはまだリリースされていませんでした(論文で著者によって言及されています)。彼らの論文で報告された計算コストは、QLoRaを使用することで大幅に低減できます。この記事の終わりに向けて、具体的な方法を紹介します。
LLMの微調整のためにデータセットを厳選する
この研究の主な目標は、特定のドメイン/タスクに対して正確なLLMを作成することです。
著者の最初の優先事項は、既存のデータセットを厳選して、目標のドメインで適合するようにすることでした。対象ドメインに関係のないトレーニング例や、ほぼ重複している例を取り除くことで、モデルの精度を向上させることを仮定しています。また、微調整に使用されるトレーニングデータのサイズを大幅に減らし、結果として微調整を効率化することも期待されています。
Platypusはチャットモデルの一群としてリリースされています。著者はまた、オープンソースのインストラクションデータセットの収集とフィルタリングも行いました。
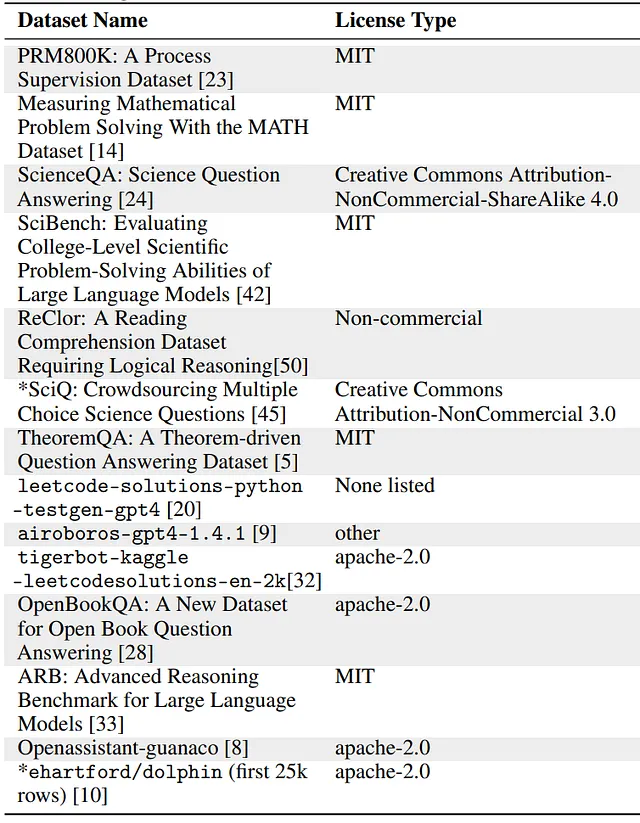
重複排除とトレーニング例の多様性を促進するために、以下の手順を実行しました:
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
- 「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
- 「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
- 「データ主導的なアプローチを取るべきか?時にはそうである」
- 「Azure Data Factory(ADF)とは何ですか?特徴とアプリケーション」
- 「pandasのCopy-on-Writeモードの深い探求-パートII」
- 「データサイエンス(2023年)で学ぶべきこと」
