NLPの探求 – NLPのキックスタート(ステップ#3)
NLPの探求 - NLPのキックスタート(ステップ#3)
「Exploring NLP」シリーズに初めて参加される方は、こちらの紹介記事をご覧ください。
NLPの探求とマスタリング―深淵への旅
こんにちは、私はDeepthi Sudharsanです。人工知能の学士号を取得する3年生の大学生です。既に~
VoAGI.com
今週は、特に単語埋め込みについて学んだいくつかの概念を紹介します。シリーズの一環として、すぐに手を動かして実践したことも共有します!この学期、私にこの講座を受け持ってくださったアムリタ・コインバトール校のCENのSachin Kumar S氏に感謝申し上げます。ここに掲載されている情報と画像の一部は、彼から提供されたリソースや教材から収集または作成されたものです。
N-gram:
N-gramは、文章またはトークンのシーケンスに確率を割り当てる最も単純な言語モデルです(トークンのシーケンスに確率値を割り当てるモデルは言語モデルと呼ばれます)。
- NLPの探求- NLPのキックスタート(ステップ#4)
- Mentatと出会ってください:コマンドラインからのあらゆるコーディングタスクを支援するAIツールで、複数のファイルでの編集を調整することができます
- アンサンブル学習:決定木からランダムフォレストへ
n-gramは、n個のトークンからなるシーケンスです。n-gramのアイデアは、単語全体の履歴に基づいて単語の確率を計算する代わりに、数語を使用して履歴を近似することです。次の単語の確率は、前の単語のみに依存するという仮定はマルコフ仮定として知られています。N-gramモデルは、単語の確率を予測するために過去n-1個の単語を調べます。
単語埋め込み:
NLPのさまざまなタスクのために、単語をその意味を持つn次元のベクトル表現に変換することを単語埋め込みと呼びます。例:Word2Vec
英語のコーパスには1000万以上のトークンがあります。単語埋め込みは、各単語をベクトルにエンコードし、ベクトル空間内の点になるようにします。
このような単語ベクトル空間は、言語のすべての意味をエンコードするか、似たような文脈を持つ単語がベクトル空間内の近い点にマップされるという直感があります。
ワンホットエンコーディング:
特定の単語のインデックスにおいて、ベクトルの長さが語彙サイズと等しく、その単語の要素のみが1で、他の要素は0になるように、単語をベクトル形式で表現することです。
例えば、「I Love NLP」という文のワンホットエンコーディングは、以下のようになります。

このような表現は、単語間の意味や関連性(文脈的な近さ)についての直感を与えません。
ワンホットエンコーディングの欠点は、非常に大きなデータの場合、ワンホットエンコーディングベクトルが非常に大きく、疎な形になることです(多くのゼロが格納されます)。また、ワンホットエンコーディングは文脈を捉えることができません。
SVDベースのアプローチ:
巨大なコーパスの場合、共起行列に対してSVDを実行し、分解した後にベクトルU(固有ベクトル行列)、S(固有値行列)、およびV.T(Vの転置 – 固有ベクトル行列の逆行列)を取得します。
以下は、「Roses are red」と「Sky is Blue」という文に対する共起行列です。共起行列は、行の単語が文内の列の単語に囲まれている回数を示しています。
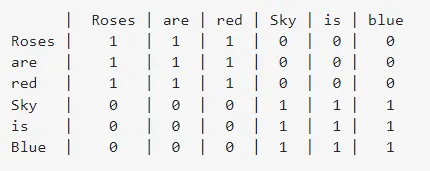
左特異ベクトルまたは左特異ベクトル行列である行列Uのベクトルは、単語のベクトル表現として考慮されます。
この記事は興味深く、このアプローチについて詳しく読むことができます: https://medium.com/analytics-vidhya/co-occurrence-matrix-singular-value-decomposition-svd-31b3d3deb305
上記のリンクから、この手法の利点と欠点を学びました。
- 共起行列における単語間の関係を知ることができます。
2. 一度計算されたら複数回参照できますが、新しい単語が頻繁にコーパスに追加され、行列の次元が連続的に変化する場合には欠点があります。
3. 一般的に、特に共起しない単語が多く、要素のほとんどがゼロの場合には多くのメモリを使用します。
用語文書行列 :
その名前が示すように、単語の語彙サイズ x ドキュメント数の行列表現を作成します。語彙からの単語について、各ドキュメントでの出現回数を表しています。
単語の順序/位置や意味を捉えることはできません。
単語ベクトルの分布的性質 :
単語の意味は、それが現れる文脈に基づいて推測できるという仮説に基づいています。
コーパスで非常に少数回しか出現しないレアな単語を表現するのには向いていません。曖昧さの問題に悩まされ、形態論を処理することができません(evaluateとevaluateは異なると見なされます)。
ワードエンベッディングは、頻度(例:カウントベクトル、TF-IDFベクトル、共起行列)と予測(Continuous Bag of Words(CBOW)、Skip-Gram)に基づく埋め込みの2つのカテゴリに大別されます。
Word2Vec :
Word2Vecは、言語の文脈を再構築するために訓練された浅い2層ニューラルネットワークです。Continuous Bag-of-WordsとSkip-gramの2つのアーキテクチャがあります。
Continuous Bag of Words :
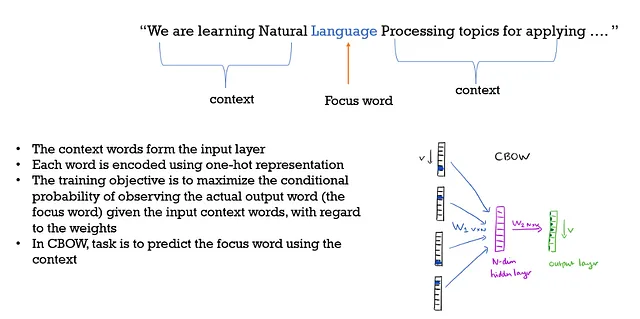
目的関数 :
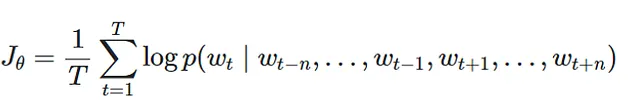
単語の埋め込みを作成するために、過去と未来のn単語が使用されます。
ウィンドウサイズを増やしても助けにならず、ノイズが増えます。
ここでは、単語の文脈と順序は重要ではないため、単語の袋を取るだけであり、そのため「BOW」がその名前の一部です。また、単語の意味的関係も示します。
CBOWはSkip-gramよりも優れた性能を発揮します。より効率的に単語ベクトルを捉えるために入力データをより良く活用することができるからです。
Skip Grams :

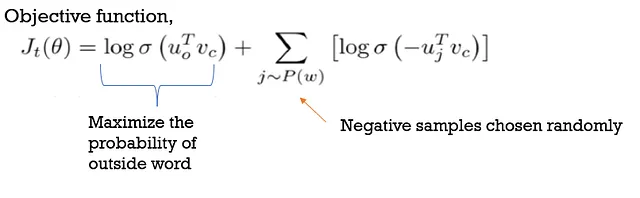
ここでは、ターゲットワードは入力され、コンテキストワードは出力されます。CBOWとは異なります。
これは教師なし学習アプローチであり、提供された任意の生のテキストから学習することができ、メモリを少なく使用します。隠れ層のニューロンの数の設定やコンテキストの位置の取得は難しく、トレーニングにかかる時間も長くなります。
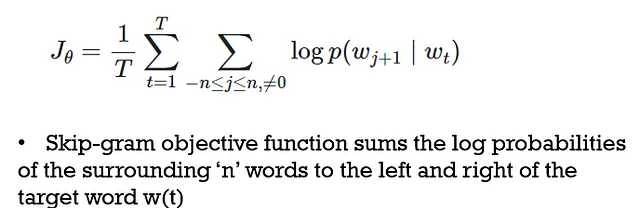
GLoVE(Global Vectors for Word Representations):
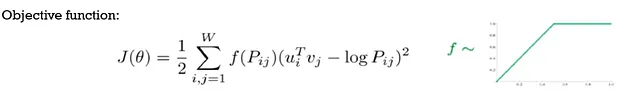
•Gloveモデルは、単語の共起数とウィンドウベースのアプローチを組み合わせます。
•非常に大きな共起行列を最初に計算する必要があり、’P’で示されます。
•共起する可能性のある単語のペアごとに、2つの単語の内積と2つの単語のログカウントの距離を最小化します。
•二乗距離値はf(Pij)を使用して重み付けされ、高いカウントを持つペアには低い重みが割り当てられます。
•ここでは、個々の単語の出現が考慮されます。
FastText:
効率的なテキスト分類と表現のために使用されるFastTextは、各単語を文字n-gramのバッグとして表現します。埋め込みはn-gramを使用して学習されるため、接尾辞と接頭辞に関する情報も含まれます。
単語の埋め込みと分類のためのFastTextライブラリは、教師なし学習または教師あり学習アルゴリズムの作成を可能にし、単語のベクトル表現を取得できます。
少なくとも1つの文字n-gramがトレーニングデータに存在する場合、FastTextは単語のベクトルを取得できます(未知語を含む)。
参考文献:
- 「Speech & language processing」、Daniel Jurafsky、James H Martin、preparation [引用日:2020年6月1日](利用元:https://web. Stanford. edu/~ jurafsky/slp3(2018))
- https://en.wikipedia.org/wiki/Word_embedding
- https://towardsdatascience.com/https-VoAGI-com-tanaygahlot-moving-beyond-the-distributional-model-for-word-representation-b0823f1769f8
- https://medium.com/analytics-vidhya/co-occurrence-matrix-singular-value-decomposition-svd-31b3d3deb305
- https://deepdatascience.wordpress.com/2017/04/25/word2vec-continous-bag-of-words/
- https://towardsdatascience.com/skip-gram-nlp-context-words-prediction-algorithm-5bbf34f84e0c
- https://www.kdnuggets.com/2016/05/amazing-power-word-vectors.html/2
このシリーズの前のパート:
パート#1:https://medium.com/@deepthi.sudharsan/exploring-nlp-kickstarting-nlp-step-1-e4ad0029694f
パート#2:https://medium.com/@deepthi.sudharsan/exploring-nlp-kickstarting-nlp-step-2-157a6c0b308b
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「GETMusicに会ってください:統一された表現と拡散フレームワークで、統一された表現と拡散フレームワークを使用して任意の音楽トラックを生成できます」
- 大規模言語モデルの挙動を監視する7つの方法
- 「5つのオンラインAI認定プログラム – 研究と登録」
- 「A.I.言語モデルの支援を受けて、Googleのロボットは賢くなっています」
- 「会話型AIのLLM:よりスマートなチャットボットとアシスタントの構築」
- ソースフリーのドメイン適応における壁の破壊:バイオアコースティクスとビジョン領域へのNOTELAの影響
- BTSの所属レーベルHYBEがAIを活用して複数言語でトラックをリリースすることを目指す






