「Huggy Lingo:Hugging Face Hubで言語メタデータを改善するための機械学習の利用」
Huggy Lingo Using Machine Learning to Improve Language Metadata on Hugging Face Hub
Huggy Lingo: Hugging Face Hubで言語メタデータを改善するために機械学習を使用する
要約: 私たちは機械学習を使用して、言語メタデータのないHubデータセットの言語を検出し、このメタデータを追加するために司書ボットがプルリクエストを行っています。
Hugging Face Hubは、コミュニティが機械学習モデル、データセット、アプリケーションを共有するリポジトリとなっています。データセットの数が増えるにつれて、メタデータは自分のユースケースに適したリソースを見つけるための重要なツールとなっています。
このブログ投稿では、Hugging Face Hubでホストされるデータセットのメタデータを改善するために機械学習を使用したいくつかの初期実験を共有します。
Hub上のデータセットの言語メタデータ
Hugging Face Hubには現在約50,000の公開データセットがあります。データセットで使用される言語に関するメタデータは、データセットカードの先頭にあるYAMLフィールドを使用して指定することができます。
- 「ダウンストリームタスクのためのFine-tuningを通じたBERTの適応」
- 「Skill-it」とは、言語モデルの理解とトレーニングのためのデータ駆動型スキルフレームワークです
- 「標準偏差を超えた真のデータ分散を明らかにする2つの指標」
すべての公開データセットは、メタデータ内の言語タグを使用して1,716の一意の言語を指定しています。ただし、指定される言語のいくつかは、異なる方法で指定されることになります。たとえば、IMDBデータセットでは、YAMLメタデータにen(英語を示す)が指定されています。
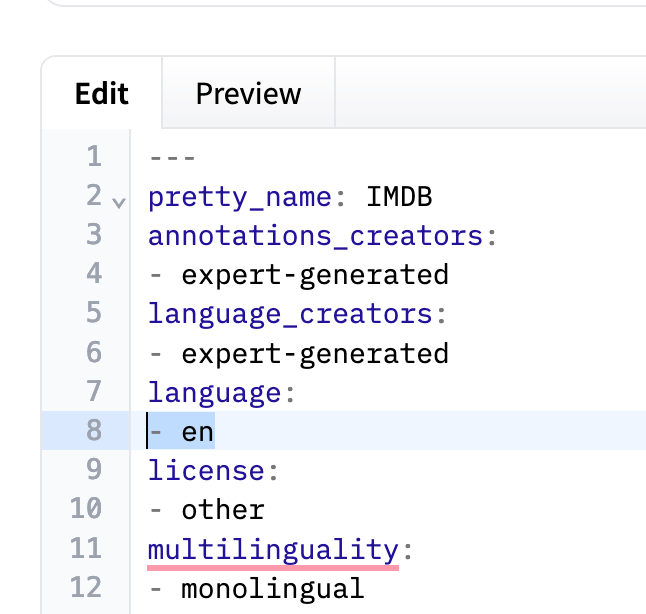 IMDBデータセットのYAMLメタデータのセクション
IMDBデータセットのYAMLメタデータのセクション
英語がHub上のデータセットで遥かに最も一般的な言語であることは驚くべきことではありません。Hub上のデータセットの約19%が言語をenとしてリストしています(enのバリエーションを含めない場合であり、実際の割合はおそらくはるかに高いでしょう)。
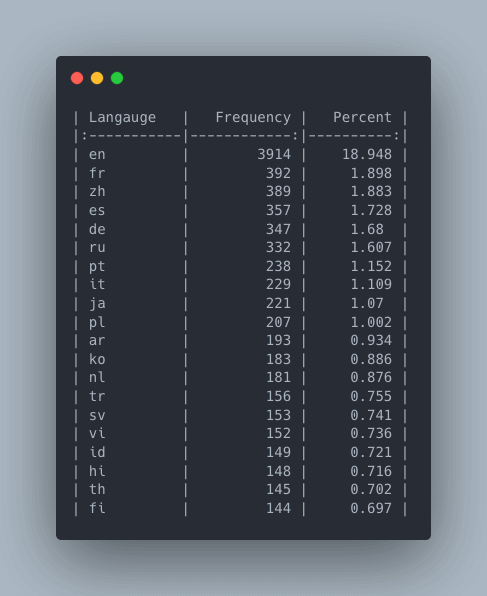 Hugging Face Hub上のデータセットの頻度とパーセンテージ頻度
Hugging Face Hub上のデータセットの頻度とパーセンテージ頻度
英語を除外した場合、言語の分布はどのようになりますか?いくつかの支配的な言語のグループがあり、その後は言語が出現する頻度が比較的滑らかに減少していることがわかります。
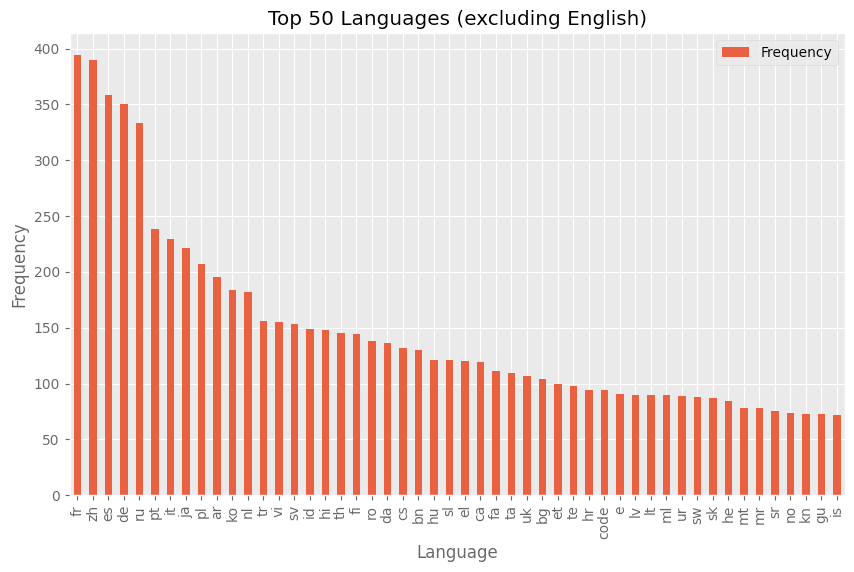 Hub上のデータセットの言語タグの分布(英語を除く)
Hub上のデータセットの言語タグの分布(英語を除く)
ただし、これには重要な注意点があります。ほとんどのデータセット(約87%)は使用される言語を指定していません。メタデータに言語情報が含まれているのはおおよそ13%のデータセットのみです。
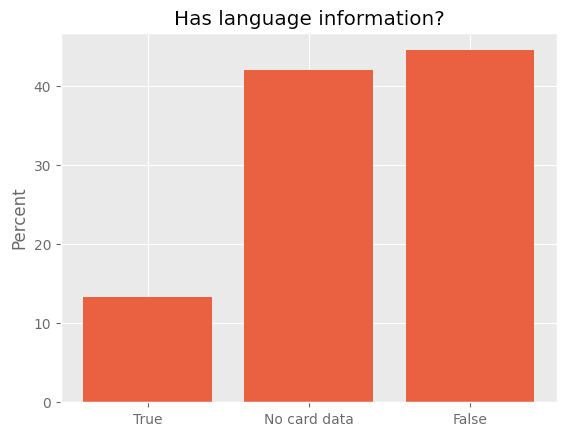 言語メタデータを持つデータセットの割合。Trueは言語メタデータが指定されていることを示し、Falseは言語データがリストされていないことを示します。カードデータがない場合は、メタデータが存在しないか、`huggingface_hub` Pythonライブラリで読み込むことができないことを意味します。
言語メタデータを持つデータセットの割合。Trueは言語メタデータが指定されていることを示し、Falseは言語データがリストされていないことを示します。カードデータがない場合は、メタデータが存在しないか、`huggingface_hub` Pythonライブラリで読み込むことができないことを意味します。
言語メタデータの重要性
言語メタデータは関連するデータセットを見つけるための重要なツールです。Hugging Face Hubでは、言語でデータセットをフィルタリングすることができます。たとえば、オランダ語のデータセットを見つけたい場合、Hub上のフィルターを使用してオランダ語のデータセットのみを含めることができます。
現在、このフィルターでは184のデータセットが返されます。ただし、メタデータにこれを指定していないがオランダ語を含んでいるデータセットもあります。データセットの数が増えるにつれて、これらのデータセットを見つけることはより困難になります。
多くの人々は特定の言語のデータセットを見つけることができるようにしたいと考えています。特定の言語の良質なトレーニングデータが不足しているため、特定の言語のための優れたオープンソースLLMのトレーニングは主要な障害の一つです。
また、関連する機械学習モデルを見つけるタスクに切り替えると、モデルのトレーニングデータに含まれている言語を知ることで、関心のある言語のモデルを見つけるのに役立ちます。これはデータセットがこの情報を指定していることに依存しています。
最後に、Hubで表現されている言語(およびそうでない言語)を知ることは、Hubの言語のバイアスを理解し、特定の言語のギャップを埋めるためのコミュニティの取り組みに役立ちます。
機械学習を使用してデータセットの言語を予測する
既に、Hugging Face Hubの多くのデータセットには使用される言語のメタデータが含まれていないことを見てきました。しかし、これらのデータセットは既にオープンに共有されているため、機械学習を使用してデータセットを見て、言語を識別することができるかもしれません。
データの取得
データセットからいくつかの例をアクセスする方法の一つは、データセットライブラリを使用してデータセットをダウンロードすることです。
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")ただし、Hub上のいくつかのデータセットでは、データセット全体をダウンロードしたくない場合もあります。その場合、データセットのサンプルを読み込んでみることもできます。ただし、データセットの作成方法によっては、作業しているマシンに必要以上のデータをダウンロードする可能性があります。
幸いなことに、Hub上の多くのデータセットはデータセットサーバーを介して利用可能です。データセットサーバーは、データセットをローカルにダウンロードせずにHubにホストされているデータセットにアクセスできるAPIです。データセットサーバーは、Hubにホストされている多くのデータセットのデータセットビューアープレビューに使用されています。
データセットの言語を予測するための最初の実験では、テキストコンテンツを含むと思われる列名とデータ型のリストを定義します。つまり、textまたはpromptの列名とstringのフィーチャーが関連する可能性が高いです。これにより、言語情報があまり関係ないデータセット(例:画像分類のデータセット)の言語を予測する必要を避けることができます。データセットサーバーを使用して、テキストデータの最初の20行を機械学習モデルに渡すことで、データセットから20行のテキストデータを取得します(データセットからより多くまたは少ない例を取得するように変更することも可能です)。
このアプローチにより、Hub上の大半のデータセットについて、データセットの最初の20行のテキスト列の内容をすばやくリクエストすることができます。
データセットの言語の予測
データセットからテキストの例を取得したら、次に言語を予測する必要があります。ここではさまざまなオプションがありますが、この作業では、Metaによって作成されたfacebook/fasttext-language-identification fastTextモデルを使用しました。このモデルは217の言語を検出でき、これはおそらくHubにホストされているデータセットの大部分を表します。
データセットから20の例をモデルに渡すことで、各データセットの各行に対して20の個別の言語予測が得られます。
これらの予測を使用するかどうかを決定するために、いくつかの追加のフィルタリングを行います。これはおおよそ以下の手順で行われます:
- データセットごとの予測を言語でグループ化します。一部のデータセットでは複数の言語の予測が返されます。これらの予測を予測された言語ごとにグループ化します。例えば、データセットが英語とオランダ語の予測を返す場合、英語の予測とオランダ語の予測をグループ化します。
- 複数の言語が予測されたデータセットでは、各言語に対していくつの予測があるかを数えます。言語が80%以下の割合で予測された場合、この予測を破棄します。例えば、英語の予測が18回でオランダ語の予測が2回の場合、オランダ語の予測は破棄されます。
- 各言語のすべての予測に対する平均スコアを計算します。言語の予測に関連付けられた平均スコアが80%未満の場合、この予測を破棄します。
 予測の処理方法を示す図。
予測の処理方法を示す図。
このフィルタリングを行った後、これらの予測をどのように使用するかをさらに決定する必要があります。fastText言語予測モデルは、ISO 639-3コード(言語コードの国際規格)とスクリプトタイプとして予測を返します。つまり、kor_Hangは、韓国語(kor)+ハングル文字(Hang)のISO 693-3言語コードであり、言語のスクリプトを示すISO 15924コードです。
スクリプト情報は現在、Hubのメタデータとして一貫してキャプチャされていないため、スクリプト情報は破棄します。可能な場合、モデルによって返される言語予測をISO 639-3からISO 639-1言語コードに変換します。これは、HubのUIでデータセットをナビゲートするために、これらの言語コードがより良いサポートを提供しているためです。
ISO 639-3コードには、ISO 639-1との対応がない場合もあります。この場合、意味があると判断される場合には、マッピングを手動で指定します。たとえば、標準アラビア語(arb)はアラビア語(ar)にマップされます。明らかなマッピングが不可能な場合は、現時点ではこのデータセットのメタデータを提案しません。この作業の将来のイテレーションでは、異なるアプローチを取るかもしれません。このアプローチには欠点があることに注意することが重要です。言語の多様性が低下し、他の言語にマッピングできる言語についての主観的な判断に依存することがあるからです。
しかし、プロセスはここで終わりません。データセットの言語を予測することの意味は、それをコミュニティの他のメンバーと共有できなければ役に立ちません。
メタデータの更新にはLibrarian-Botを使用する
この貴重な言語メタデータをハブに組み込むために、Librarian-Botを利用します!Librarian-Botは、Metaのfacebook/fasttext-language-identification fastTextモデルによって生成された言語予測を取得し、各データセットのメタデータにこの情報を追加するためのプルリクエストを作成します。
このシステムは、データセットを言語情報で更新するだけでなく、人の手作業を必要とせずに迅速かつ効率的に行います。リポジトリの所有者がプルリクエストを承認してマージすることを決定した場合、言語メタデータはすべてのユーザーに利用可能になり、Hugging Face Hubの使いやすさが大幅に向上します。リブラリアンボットの動作状況は、こちらで確認することができます!
次のステップ
Hubにあるデータセットの数が増えるにつれて、メタデータはますます重要になります。特に言語メタデータは、使用目的に適した正しいデータセットを特定するために非常に有益です。
データセットサーバーとLibrarian-Botsの助けを借りて、手動では不可能なスケールでデータセットのメタデータを更新することができます。その結果、Hugging Face Hubは、世界中のデータサイエンティスト、言語学者、AI愛好家にとってより強力なツールになっています。
Hugging Faceの機械学習司書として、私はHubにホストされている機械学習アーティファクトの自動メタデータ付与の機会を引き続き探求しています。アイデアがある場合やこの取り組みに協力したい場合は、お気軽にご連絡ください(daniel at thiswebsite dot co)!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「トランスフォーマーを用いたジャズコードの解析」
- 「AWS上のPySparkを使用したビッグデータでの機械学習の活用」
- 『ゴミ科学者にならない方法』
- データセットの凝縮の潜在能力を解き放つ:SRe^2LがImageNet-1Kで記録的な精度を達成
- シンガポール国立大学の研究者が提案するMind-Video:脳のfMRIデータを使用してビデオイメージを再現する新しいAIツール
- UTオースティンとUCバークレーの研究者が、アンビエントディフュージョンを紹介します:入力としての破損したデータのみを使用してディフュージョンモデルをトレーニング/微調整するためのAIフレームワーク
- 「LLMsを使用したモバイルアプリの音声と自然言語の入力」
