ロッテン・トマト映画評価予測のデータサイエンスプロジェクト:最初のアプローチ
'Data Science Project Initial Approach for Rotten Tomatoes Movie Rating Prediction.'

映画産業において、映画の成功を予測することが会社の財政的な見通しを左右することは秘密ではありません。
正確な予測は、マーケティング、配給、コンテンツ作成など、さまざまな側面において会社がよく根拠に基づいた意思決定を行うことを可能にします。
そして何よりも、これらの予測はリソースの割り当てを最適化することで利益を最大化し、損失を最小化するのに役立ちます。
幸いにも、機械学習の技術はこの複雑な問題に取り組むための強力なツールを提供しています。データ駆動型の洞察を活用することで、会社は意思決定プロセスを大幅に改善することができます。
このデータサイエンスプロジェクトは、Meta(Facebook)の採用プロセスでのテイクホーム課題として使用されています。このテイクホーム課題では、Rotten Tomatoesが「Rotten」、「Fresh」、または「Certified Fresh」としてラベル付けを行っている方法について調査します。
そのために、2つの異なるアプローチを開発します。
私たちの探索の途中で、データの前処理、さまざまな分類器、およびモデルのパフォーマンスを向上させるための潜在的な改善策について議論します。
この記事の最後までに、映画の成功を予測するために機械学習がどのように活用されるか、そしてこの知識がエンターテイメント産業にどのように適用されるかを理解することができるでしょう。
しかし、より深く掘り下げる前に、私たちが取り組むデータを見てみましょう。
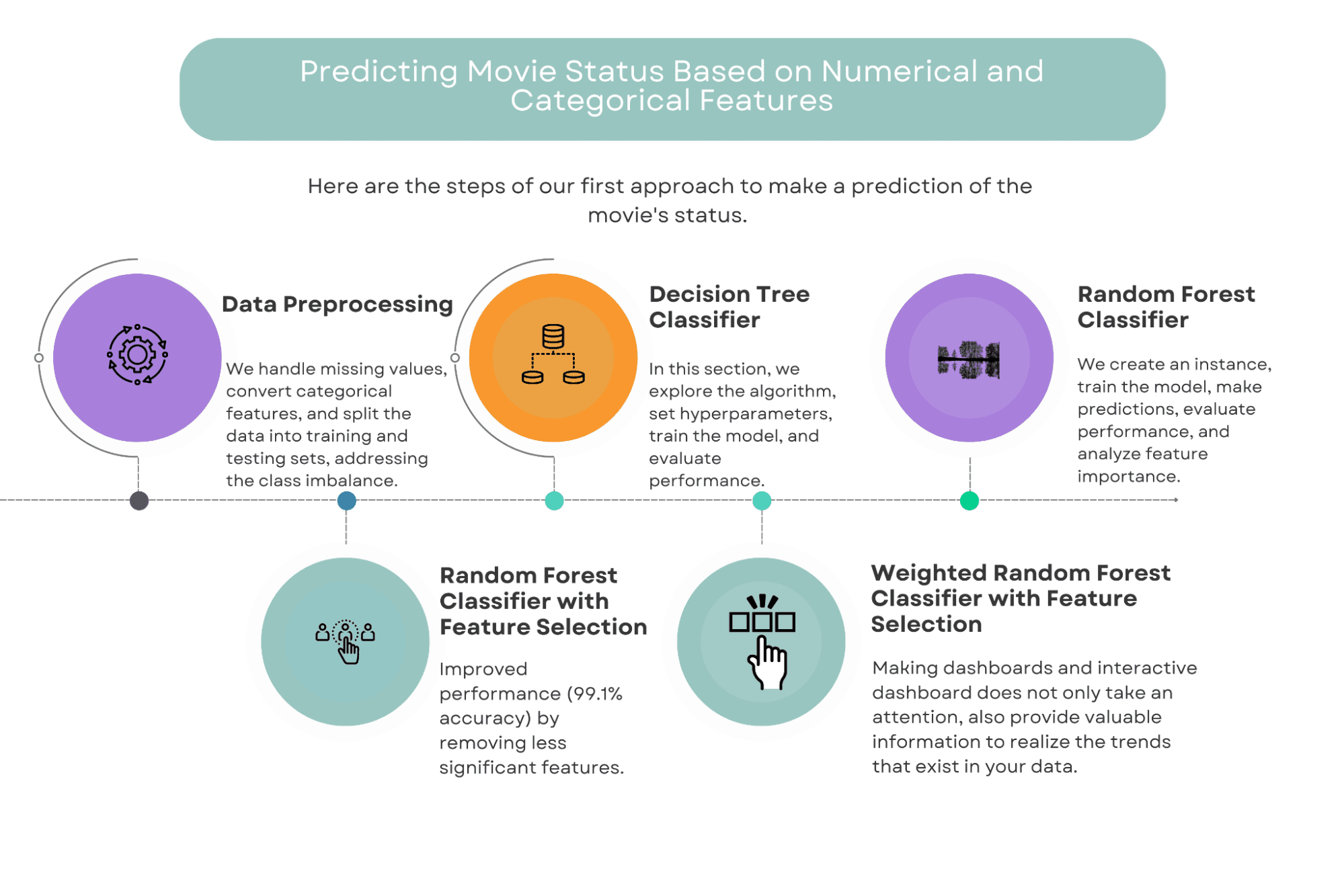
第1のアプローチ:数値とカテゴリカルな特徴に基づく映画のステータス予測
このアプローチでは、映画の成功を予測するために数値とカテゴリカルな特徴の組み合わせを使用します。
考慮する特徴には、予算、ジャンル、上映時間、監督などの要素が含まれます。
私たちは、決定木、ランダムフォレスト、特徴選択を行った重み付けランダムフォレストなど、いくつかの機械学習アルゴリズムを使用してモデルを構築する予定です。
データを読み込んで一部を確認しましょう。
以下がコードです。
df_movie = pd.read_csv('rotten_tomatoes_movies.csv')
df_movie.head()以下が出力です。
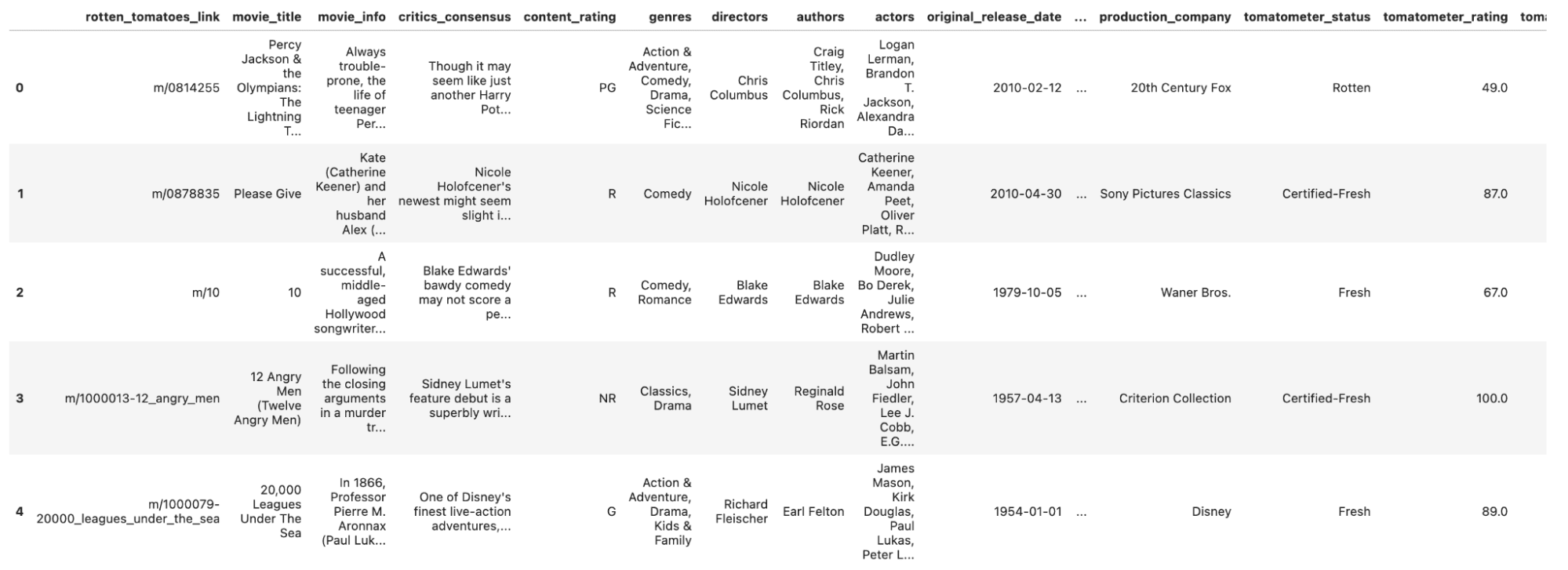
さて、データの概要がわかったので、前処理の段階に進みましょう。
データの前処理
モデルの構築を開始する前に、データを前処理することが重要です。
これには、カテゴリカルな特徴を処理し、数値表現に変換し、すべての特徴が同じ重要性を持つようにデータをスケーリングすることが含まれます。
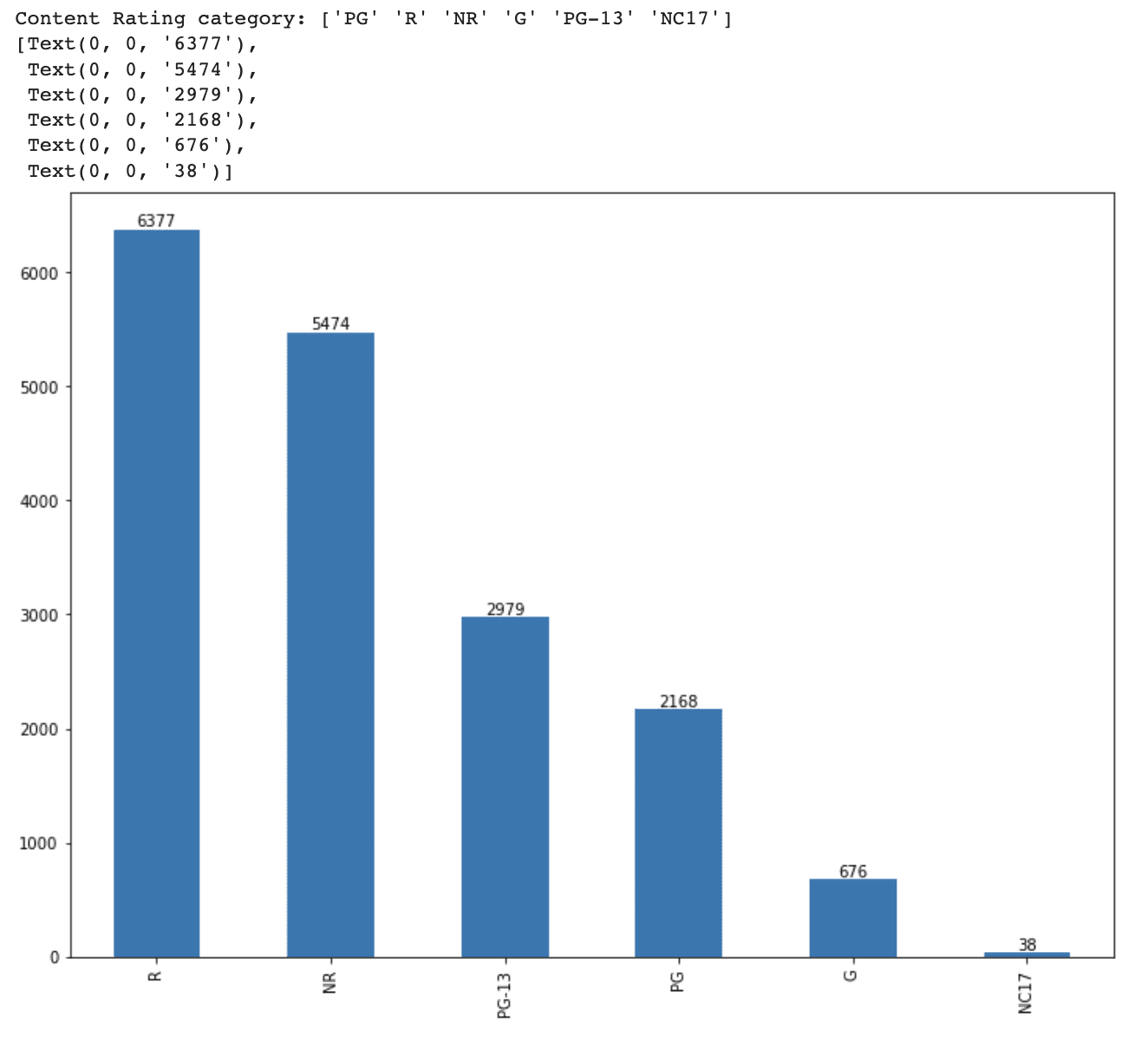
まず、content_rating列を調べて、データセット内のユニークなカテゴリとその分布を確認します。
print(f'Content Rating category: {df_movie.content_rating.unique()}')次に、各content_ratingカテゴリの分布を見るために棒グラフを作成します。
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])以下が完全なコードです。
print(f'Content Rating category: {df_movie.content_rating.unique()}')
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])以下が出力です。
機械学習モデルには数値入力が必要なので、カテゴリカルな特徴を数値形式に変換することが重要です。このデータサイエンスプロジェクトでは、2つの一般的に受け入れられている方法、序数エンコーディングとワンホットエンコーディングを適用します。カテゴリが強度の度合いを示す場合は序数エンコーディングが良いですが、大きさの表現が提供されていない場合はワンホットエンコーディングが理想的です。”content_rating”のアセットに対してはワンホットエンコーディングを使用します。
以下にコードを示します。
content_rating = pd.get_dummies(df_movie.content_rating)
content_rating.head()以下に出力結果を示します。
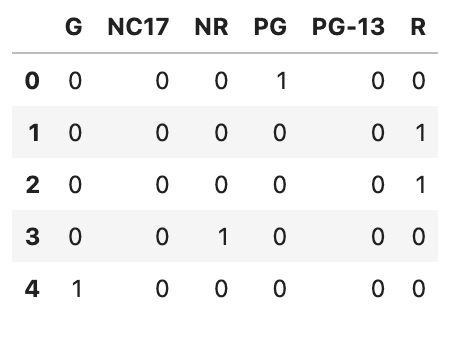
次に、別の特徴であるaudience_statusを処理していきましょう。
この変数には2つのオプションがあります: ‘Spilled’ と ‘Upright’。
既にワンホットエンコーディングを適用しているので、このカテゴリカル変数を序数エンコーディングを使用して数値形式に変換する時が来ました。
各カテゴリが大きさの順序を示しているため、序数エンコーディングを使用してこれらを数値に変換します。
最初に、ユニークなaudience statusを見つけましょう。
print(f'Audience status category: {df_movie.audience_status.unique()}')次に、棒グラフを作成し、棒の上に値を表示します。
# 各カテゴリの分布を可視化する
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])以下に完全なコードを示します。
print(f'Audience status category: {df_movie.audience_status.unique()}')
# 各カテゴリの分布を可視化する
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])以下に出力結果を示します。
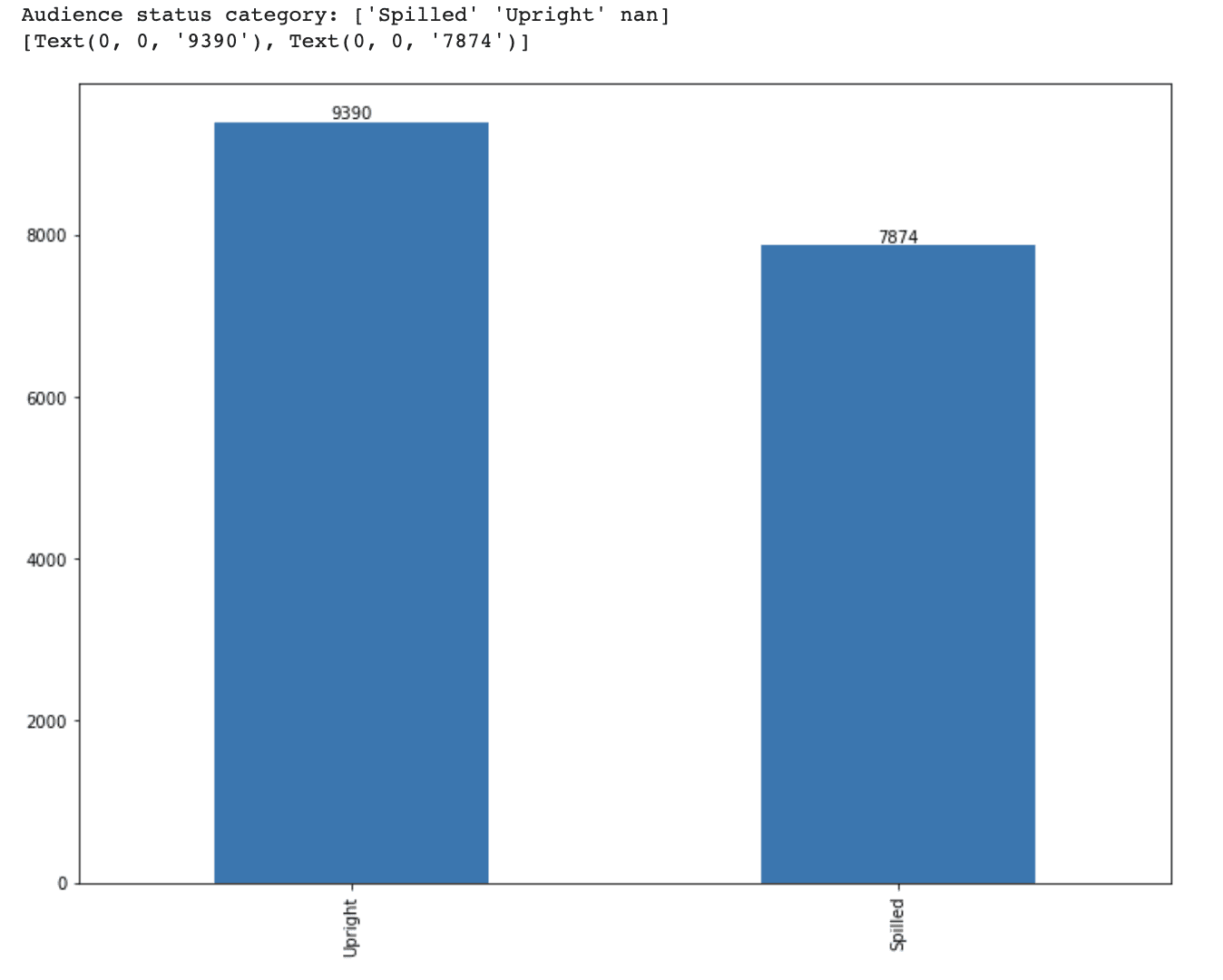
では、今度はreplaceメソッドを使用して序数エンコーディングを行いましょう。
次に、head()メソッドを使用して最初の5行を表示します。
以下にコードを示します。
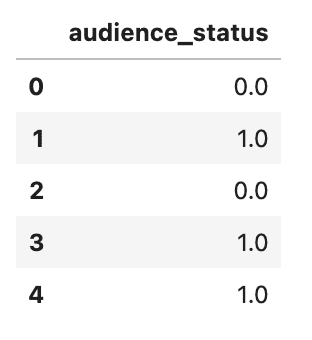
# audience status変数を序数エンコーディングでエンコードする
audience_status = pd.DataFrame(df_movie.audience_status.replace(['Spilled','Upright'],[0,1]))
audience_status.head()以下に出力結果を示します。
目標変数であるtomatometer_statusは、’Rotten’、’Fresh’、および’Certified-Fresh’の3つの異なるカテゴリを持っています。これらのカテゴリも順序を表しています。
そのため、これらのカテゴリ変数を数値変数に変換するために再び序数エンコーディングを行います。
以下にコードを示します。
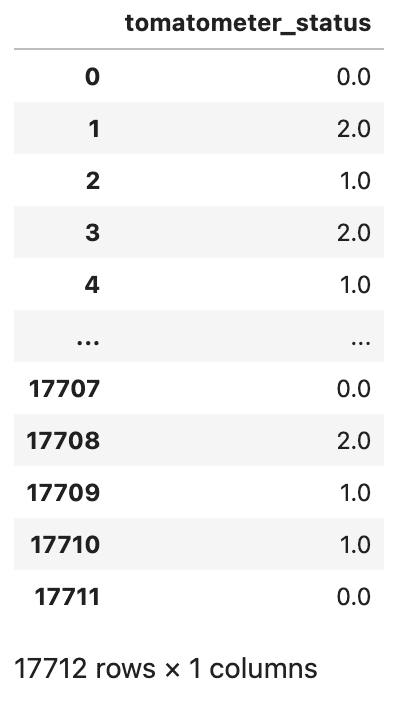
# tomatometer status変数を序数エンコーディングでエンコードする
tomatometer_status = pd.DataFrame(df_movie.tomatometer_status.replace(['Rotten','Fresh','Certified-Fresh'],[0,1,2]))
tomatometer_status以下に出力結果を示します。
カテゴリカルを数値に変換した後は、2つのデータフレームを結合する時が来ました。これにはPandasのpd.concat()関数を使用し、全ての列に欠損値がある行を削除するためにdropna()メソッドを使用します。
その後、head関数を使用して新しく形成されたデータフレームを確認します。
以下にコードを示します。
df_feature = pd.concat([df_movie[['runtime', 'tomatometer_rating', 'tomatometer_count', 'audience_rating', 'audience_count', 'tomatometer_top_critics_count', 'tomatometer_fresh_critics_count', 'tomatometer_rotten_critics_count']], content_rating, audience_status, tomatometer_status], axis=1).dropna()
df_feature.head()以下に出力結果を示します。

素晴らしいですね、describeメソッドを使用して数値変数を検査しましょう。
コードは以下の通りです。
df_feature.describe()出力結果は以下の通りです。

次に、lenメソッドを使用してDataFrameの長さをチェックしましょう。
コードは以下の通りです。
len(df)出力結果は以下の通りです。

欠損値のある行を削除し、機械学習のための変換を行った後、データフレームの行数は17017行になります。
次に、ターゲット変数の分布を分析しましょう。
一貫して行ってきたように、棒グラフを描画し、値を棒の上部に表示します。
コードは以下の通りです。
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])出力結果は以下の通りです。

データセットには、7375件の’Rotten’、6475件の’Fresh’、および3167件の’Certified-Fresh’の映画が含まれており、クラスのバランスの問題があります。
この問題は後で取り組まれます。
さしあたって、80%をトレーニングセット、20%をテストセットに分割しましょう。
コードは以下の通りです。
X_train、X_test、y_train、y_test = train_test_split(df_feature.drop(['tomatometer_status'], axis=1), df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'トレーニングデータのサイズは{len(X_train)}で、テストデータのサイズは{len(X_test)}です')出力結果は以下の通りです。

決定木分類器
このセクションでは、分類問題に一般的に使用され、時には回帰にも使用される機械学習手法である決定木分類器を見ていきます。
この分類器は、データポイントを分岐に分割し、各分岐には内部ノード(条件のセットを含む)とリーフノード(予測値を持つ)があります。
これらの分岐をたどり、条件(TrueまたはFalse)を考慮してデータポイントを適切なカテゴリに分けます。このプロセスは以下のようになります。
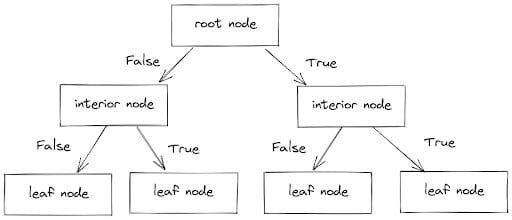 Image by Author
Image by Author
決定木分類器を適用すると、ツリーの最大深度や最大リーフノード数など、複数のハイパーパラメータを変更することができます。
最初の試みでは、ツリーのリーフノード数を3つに制限して、ツリーをシンプルで理解しやすくします。
まず、scikit-learnライブラリのDecisionTreeClassifier()関数を使用して、最大リーフノード数が3つの決定木分類器オブジェクトを定義します。
random_stateパラメータは、コードを実行するたびに同じ結果が得られるようにするために使用されます。
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)次に、.fit()メソッドを使用して、トレーニングデータ(X_trainおよびy_train)で決定木分類器をトレーニングします。
tree_3_leaf.fit(X_train, y_train)次に、訓練済みの分類器を使用してテストデータ(X_test)に対して予測を行います。予測にはpredictメソッドを使用します。
y_predict = tree_3_leaf.predict(X_test)ここでは、予測された値とテストデータの実際の目標値を比較して、正解率と分類レポートを表示します。scikit-learnライブラリのaccuracy_score()関数とclassification_report()関数を使用します。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))最後に、テストデータ上での決定木分類器のパフォーマンスを可視化するために混同行列をプロットします。scikit-learnライブラリのplot_confusion_matrix()関数を使用します。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap='cividis', ax=ax)以下にコードがあります。
# max_leaf_nodesが3のDecision Tree Classifierをインスタンス化する
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes=3, random_state=2)
# 訓練データで分類器をトレーニングする
tree_3_leaf.fit(X_train, y_train)
# トレーニング済みの決定木分類器でテストデータを予測する
y_predict = tree_3_leaf.predict(X_test)
# テストデータの正解率と分類レポートを表示する
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# テストデータ上の混同行列をプロットする
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap='cividis', ax=ax)以下が出力です。

出力から明らかにわかるように、決定木はうまく動作しています。特に、3つの葉ノードに制限したことを考慮すると、優れたパフォーマンスを示しています。シンプルな分類器を持つことの利点の1つは、決定木を視覚化して理解しやすいことです。
次に、決定木がどのように意思決定を行うかを理解するために、sklearn.treeのplot_treeメソッドを使用して決定木分類器を視覚化しましょう。
以下がコードです。
fig, ax = plt.subplots(figsize=(12, 9))
plot_tree(tree_3_leaf, ax=ax)
plt.show()以下が出力です。
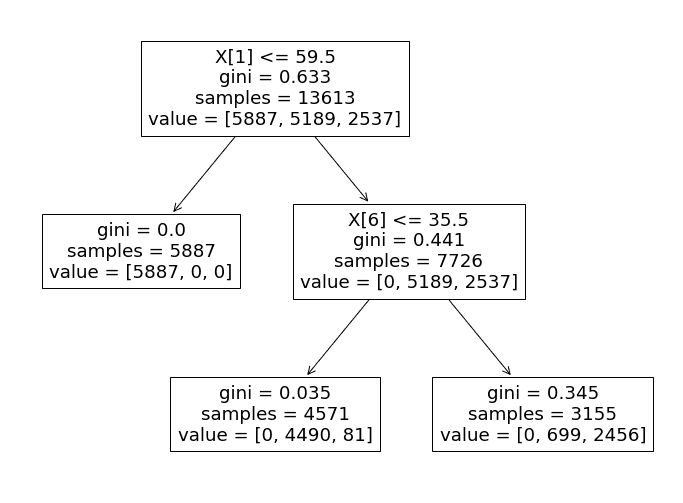
この決定木を分析し、どのように意思決定プロセスが行われるかを調べましょう。
具体的には、アルゴリズムは各テストデータポイントの分類において「tomatometer_rating」の特徴を主要な要素として使用します。
- 「tomatometer_rating」が59.5以下の場合、データポイントにはラベル0(「Rotten」)が割り当てられます。そうでない場合、分類器は次の枝に進みます。
- 次の枝では、「tomatometer_fresh_critics_count」の特徴を使用して残りのデータポイントを分類します。
- この特徴の値が35.5以下の場合、データポイントはラベル1(「Fresh」)としてラベル付けされます。
- そうでない場合、ラベル2(「Certified-Fresh」)としてラベル付けされます。
この意思決定プロセスは、Rotten Tomatoesが映画のステータスを割り当てる際に使用するルールや基準と非常に一致しています。
Rotten Tomatoesのウェブサイトによれば、映画は以下のように分類されます。
- 「tomatometer_rating」が60%以上の場合、「Fresh」と分類されます。
- 「tomatometer_rating」が60%未満の場合、「Rotten」と分類されます。
私たちの決定木分類器は、このロジックに従って映画を「Rotten」と分類します(「tomatometer_rating」が59.5未満の場合)。「Fresh」と「Certified-Fresh」の映画を区別する際には、分類器はさらにいくつかの特徴を考慮する必要があります。
Rotten Tomatoesによると、「Certified-Fresh」に分類されるためには、以下のような特定の基準を満たす必要があります。
- 少なくとも75%の一貫したTomatometerスコアを持つこと
- トップ評論家からの少なくとも5つのレビュー
- ワイドリリース映画の場合、少なくとも80のレビュー
私たちの限定的な決定木モデルは、上位の評論家からのレビューの数だけを考慮して、「新鮮」映画と「認定新鮮」映画を区別します。
さて、決定木の背後にあるロジックを理解しました。パフォーマンスを向上させるために、同じ手順に従ってみましょうが、今回は最大リーフノード引数を追加しません。
ここでは、コードのステップバイステップの説明を示します。前回と同様に、コードをあまり詳しく展開しません。
決定木分類器を定義します。
tree = DecisionTreeClassifier(random_state=2)トレーニングデータで分類器をトレーニングします。
tree.fit(X_train, y_train)トレーニングされた決定木分類器でテストデータを予測します。
y_predict = tree.predict(X_test)正確性と分類レポートを表示します。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))混同行列をプロットします。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)素晴らしい、ではそれらを一緒に見てみましょう。
以下が完全なコードです。
fig, ax = plt.subplots(figsize=(12, 9))
# デフォルトのハイパーパラメータ設定で決定木分類器をインスタンス化する
tree = DecisionTreeClassifier(random_state=2)
# トレーニングデータで分類器を訓練する
tree.fit(X_train, y_train)
# トレーニングされた決定木分類器でテストデータを予測する
y_predict = tree.predict(X_test)
# テストデータの正確性と分類レポートを表示する
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# テストデータの混同行列をプロットする
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)以下が出力です。
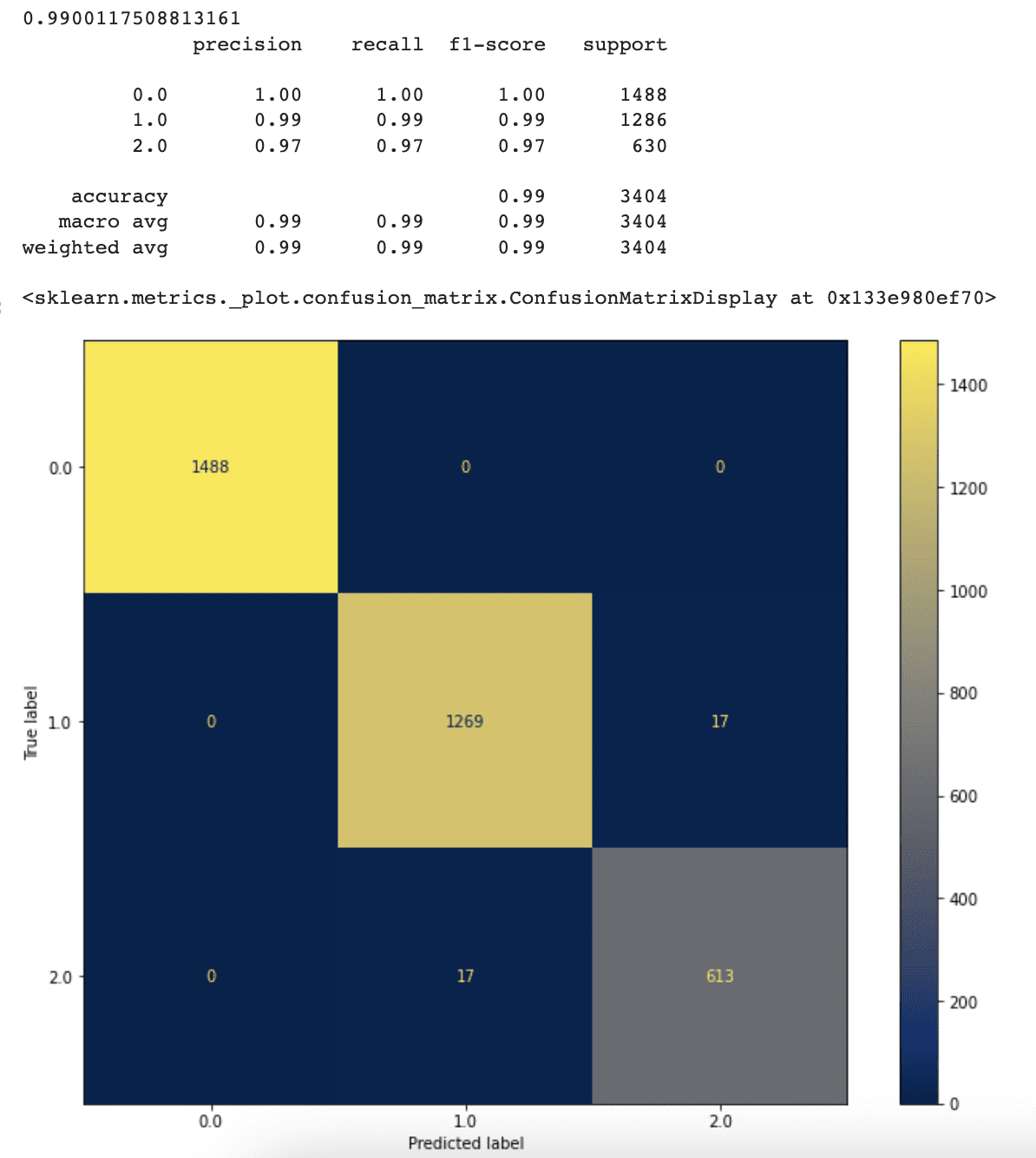
最大リーフノードの制限を取り除いた結果、分類器の正確性、適合率、再現率の値が向上しました。分類器の正確性は、以前の94%から99%に向上しました。
これは、分類器に最適なリーフノードの数を自動的に選ばせることで、性能が向上することを示しています。
現在の結果は優れているように見えますが、さらなるチューニングによってさらに優れた正確性を達成することも可能です。次のパートでは、このオプションについて見ていきます。
ランダムフォレスト分類器
ランダムフォレストは、複数の決定木分類器を組み合わせたアンサンブルです。各決定木をトレーニングするために、トレーニングデータポイントをランダムに選択するバギング戦略を使用します。このテクニックにより、各木は別々のトレーニングデータのサブセットでトレーニングされます。
バギング手法は、ブートストラップ手法を使用してデータポイントをサンプリングするために知られており、同じデータポイントが複数の決定木で選択されることがあります。
 画像提供: 著者
画像提供: 著者
scikit-learnを使用することで、ランダムフォレスト分類器を適用することは非常に簡単です。
ランダムフォレストアルゴリズムを設定するためにScikit-learnを使用することは簡単なプロセスです。
決定木分類器のパフォーマンスと同様に、ランダムフォレスト分類器のパフォーマンスは、決定木分類器の数、最大リーフノード、最大ツリーの深さなどのハイパーパラメータ値の変更によって向上する可能性があります。
まずはデフォルトのオプションを使用します。
以下は、コードのステップバイステップです。
まず、scikit-learnライブラリのRandomForestClassifier()関数を使用して、ランダムフォレスト分類器オブジェクトをインスタンス化します。random_stateパラメータは再現性のために2に設定されています。
rf = RandomForestClassifier(random_state=2)次に、トレーニングデータ(X_trainとy_train)でランダムフォレスト分類器をトレーニングします。.fit()メソッドを使用します。
rf.fit(X_train, y_train)次に、トレーニングされた分類器を使用してテストデータ(X_test)に対して予測を行います。.predict()メソッドを使用します。
y_predict = rf.predict(X_test)そして、テストデータの実際のターゲット値と予測値を比較して、予測の正確性スコアと分類レポートを表示します。
再びscikit-learnライブラリのaccuracy_score()関数とclassification_report()関数を使用します。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))最後に、テストデータ上でランダムフォレスト分類器のパフォーマンスを可視化するために混同行列をプロットします。scikit-learnライブラリのplot_confusion_matrix()関数を使用します。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)以下に、全体のコードを示します。
# ランダムフォレスト分類器のインスタンス化
rf = RandomForestClassifier(random_state=2)
# 訓練データでランダムフォレスト分類器を訓練する
rf.fit(X_train, y_train)
# 訓練済みモデルを使用してテストデータを予測する
y_predict = rf.predict(X_test)
# 正確性スコアと分類レポートを表示する
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# 混同行列をプロットする
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)以下に、出力結果を示します。
正確性スコアと混同行列の結果から、ランダムフォレストアルゴリズムは決定木分類器よりも優れたパフォーマンスを発揮していることがわかります。これは、個々の分類アルゴリズムよりもランダムフォレストのようなアンサンブル手法の利点を示しています。
さらに、木ベースの機械学習手法を使用すると、モデルが訓練された後に各特徴量の重要性を特定することができます。そのため、Scikit-learnはfeature_importances_関数を提供しています。
素晴らしいですね、もう一度コードをステップバイステップで理解しましょう。
まず、Random Forest Classifierオブジェクトのfeature_importances_属性を使用して、データセットの各特徴量の重要性スコアを取得します。
重要性スコアは、各特徴量がモデルの予測性能にどれだけ貢献しているかを示します。
# 特徴量の重要性を取得する
feature_importance = rf.feature_importances_次に、重要性の降順で特徴量の重要性と対応する特徴名を出力します。
# 特徴量の重要性を出力する
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')次に、最も重要な特徴から最も重要でない特徴までの順に特徴を可視化するために、numpyのargsort()メソッドを使用します。
# 最も重要な特徴から最も重要でない特徴を可視化する
indices = np.argsort(feature_importance)最後に、特徴の重要性を可視化するために、水平棒グラフを作成します。特徴は最も重要なものから最も重要でないものまでの順にy軸に、対応する重要性スコアをx軸に表示します。
このグラフにより、データセットの中で最も重要な特徴を簡単に特定し、モデルのパフォーマンスに最も大きな影響を与える特徴を特定することができます。
plt.figure(figsize=(12,9))
plt.title('特徴量の重要度')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('相対的な重要度')
plt.show()以下に、全体のコードを示します。
# 特徴量の重要性を取得する
feature_importance = rf.feature_importances_
# 特徴量の重要性を出力する
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')
# 最も重要な特徴から最も重要でない特徴を可視化する
indices = np.argsort(feature_importance)
plt.figure(figsize=(12,9))
plt.title('特徴量の重要度')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('相対的な重要度')
plt.show()以下に、出力結果を示します。
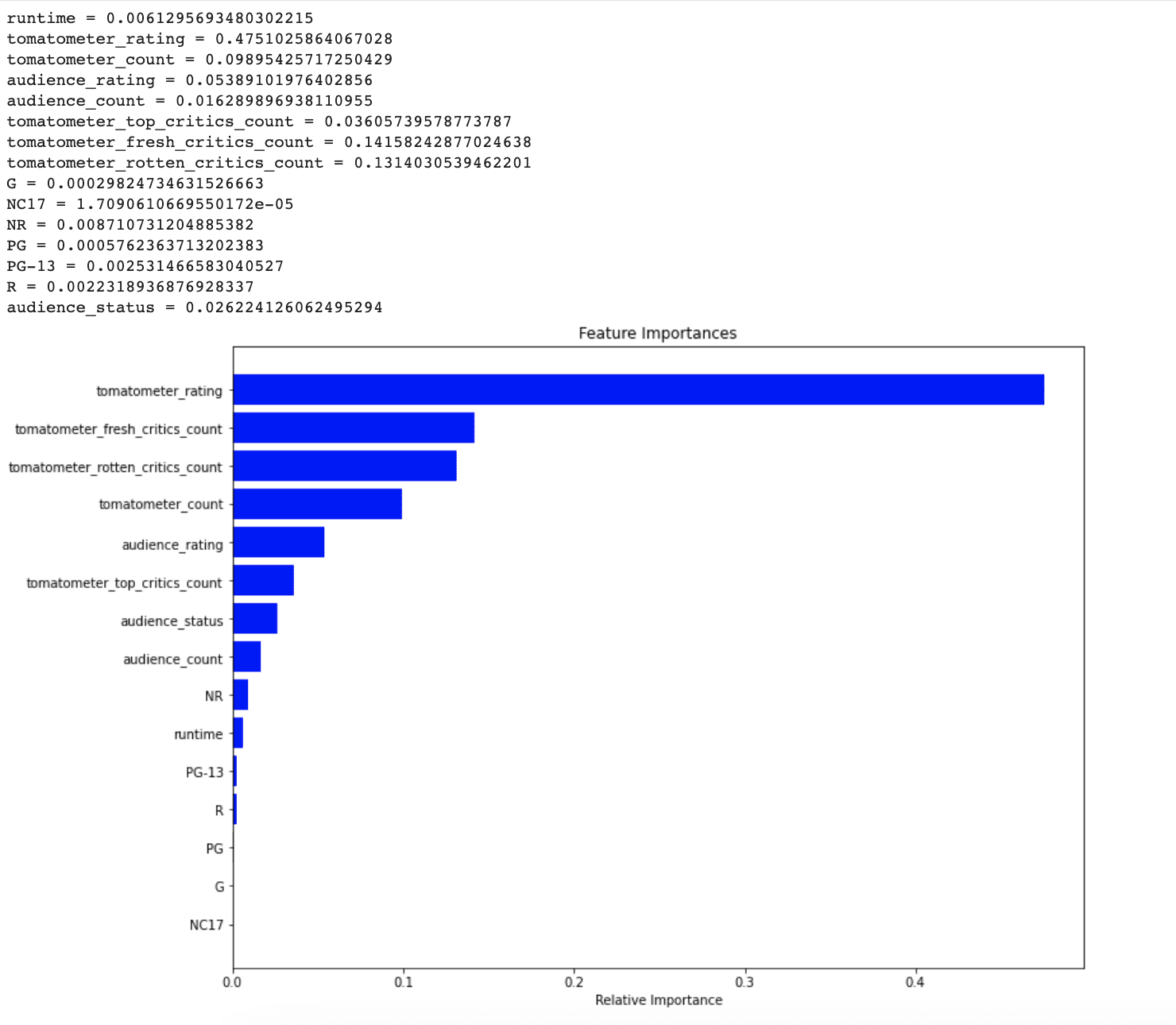
このグラフから、NR、PG-13、R、およびランタイムは、モデルにとって予測のために重要ではないと判断されたことが明確です。次のセクションでは、この問題に対処することでモデルのパフォーマンスを向上させることができるかどうかを見ていきましょう。
特徴選択を行ったランダムフォレスト分類器
以下にコードを示します。
前のセクションで、ランダムフォレストモデルによって一部の特徴が予測において重要ではないと判断されたことがわかりました。
その結果、モデルの性能を向上させるために、NR、runtime、PG-13、R、PG、G、およびNC17などの関係のない特徴を除外しましょう。
以下のコードでは、まず特徴の重要度を取得し、次にトレーニングセットとテストセットに分割しますが、コードブロック内でこれらの関係のない特徴を削除します。その後、トレーニングセットとテストセットのサイズを表示します。
以下にコードを示します。
# 特徴の重要度を取得する
feature_importance = rf.feature_importances_
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status', 'NR', 'runtime', 'PG-13', 'R', 'PG','G', 'NC17'], axis=1),df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'トレーニングデータのサイズは{len(X_train)}で、テストデータのサイズは{len(X_test)}です。')以下に出力結果があります。
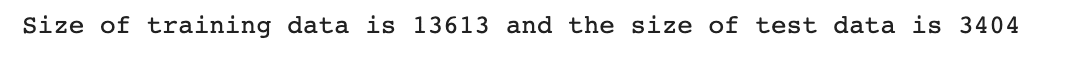
素晴らしいですね。関係のない特徴を除外したので、パフォーマンスが向上したかどうか確認しましょう。
これを何度も行ったため、以下のコードを簡単に説明します。
以下のコードでは、まずランダムフォレスト分類器を初期化し、その後トレーニングデータでランダムフォレストを訓練します。
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train, y_train)次に、テストデータを使用して正解率と分類レポートを計算し、それらを出力します。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))最後に、混同行列をプロットします。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)以下にコード全体があります。
# ランダムフォレストクラスを初期化する
rf = RandomForestClassifier(random_state=2)
# 特徴選択後のトレーニングデータでランダムフォレストを訓練する
rf.fit(X_train, y_train)
# 特徴選択後のテストデータで訓練済みモデルを予測する
y_predict = rf.predict(X_test)
# 正解率と分類レポートを出力する
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# 混同行列をプロットする
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)以下に出力結果があります。
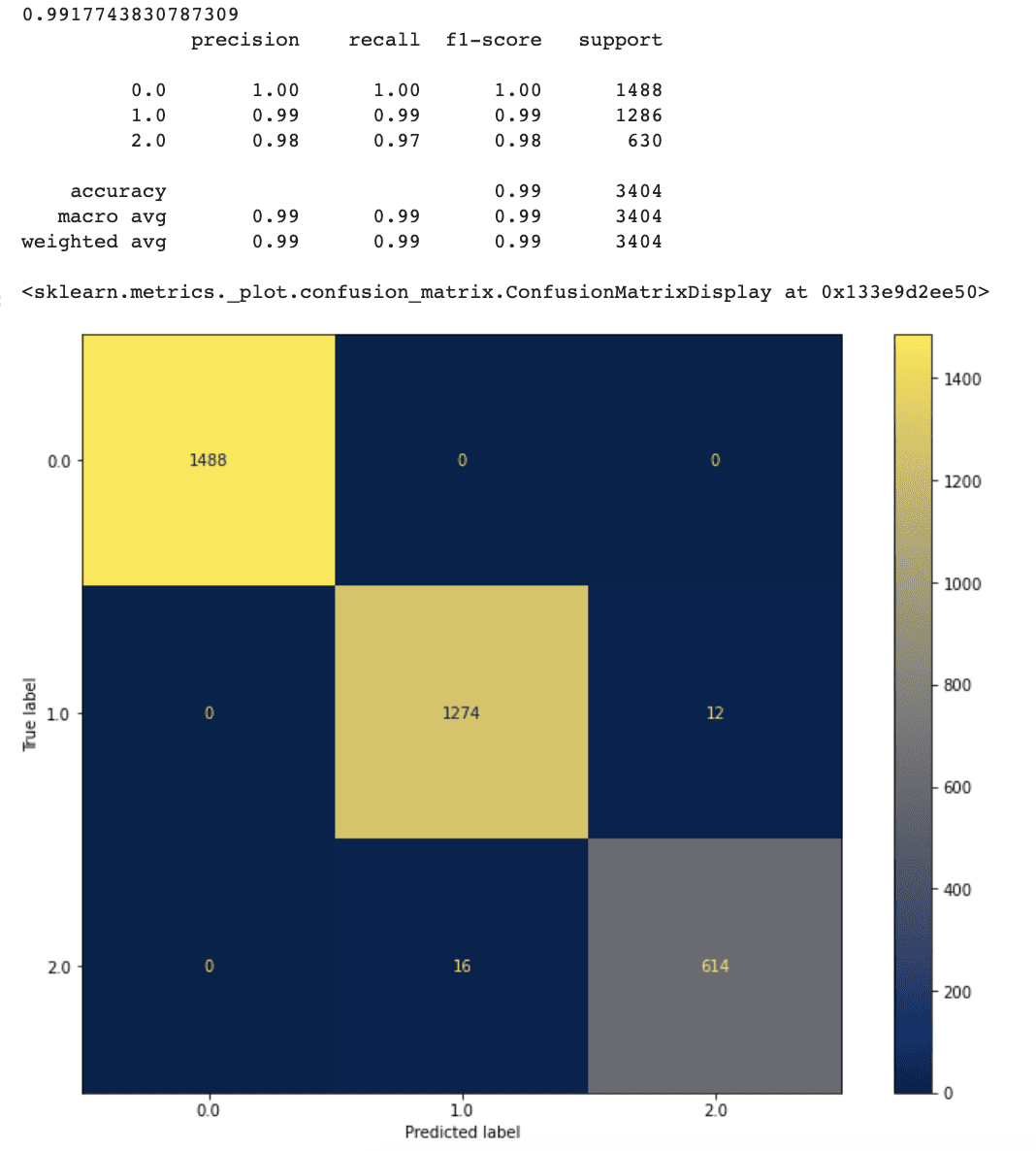
新しいアプローチはかなりうまく機能しているようです。
特徴選択を行った後、正解率は99.1%に向上しました。
モデルの偽陽性率と偽陰性率も、以前のモデルと比較してわずかに低下しています。
これは、特徴が多いほど必ずしも良いモデルになるわけではないことを示しています。無関係な特徴はモデルの予測精度を下げる原因となるノイズを作り出す可能性があります。
さて、モデルのパフォーマンスがこれほど向上したので、さらに向上させるための他の方法を見つけましょう。
重み付き特徴選択を行ったランダムフォレスト分類器
最初のセクションでは、特徴がやや不均衡であることに気付きました。’Rotten’(0で表される)、’Fresh’(1で表される)、および’Certified-Fresh’(2で表される)の3つの異なる値があります。
まず、特徴の分布を見てみましょう。
以下は、ラベルの分布を視覚化するコードです。
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])以下に出力結果があります。
‘Certified Fresh’(「認定フレッシュ」)の特徴を持つデータの量は、他のものよりもはるかに少ないことが明らかです。
データの不均衡の問題を解決するためには、SMOTEアルゴリズムなどのアプローチを使用して、少数派クラスをオーバーサンプリングするか、トレーニングフェーズ中にモデルにクラスの重み情報を提供することができます。
ここでは、2番目のアプローチを使用します。
クラスの重みを計算するために、scikit-learnライブラリのcompute_class_weight()関数を使用します。
この関数の中で、class_weightパラメータは’imbalanced’に設定され、df_featureのtomatometer_status列の一意の値がclassesパラメータに設定されます。
yパラメータは、df_featureのtomatometer_status列の値に設定されます。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)次に、クラスの重みを対応するインデックスにマッピングするための辞書が作成されます。
これは、class_weightリストをdict()関数とzip()関数を使用して辞書に変換することで行われます。
range()関数は、class_weightリストの長さに対応する整数のシーケンスを生成するために使用され、これが辞書のキーとして使用されます。
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()最後に、辞書を見てみましょう。
class_weight_dict以下は全体のコードです。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dict以下は出力です。
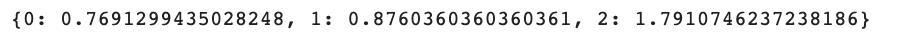
クラス0(「Rotten」)が最も重い重みを持ち、クラス2(「Certified-Fresh」)が最も重い重みを持ちます。
ランダムフォレスト分類器を適用する際に、この重み情報を引数として含めることができます。
残りのコードは以前に何度も行ったものと同じです。
クラス重みデータを使用して新しいランダムフォレストモデルを構築し、トレーニングセットで訓練し、テストデータを予測し、正解率スコアと混同行列を表示しましょう。
以下はコードです。
# Initialize Random Forest model with weight information
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
# Train the model on the training data
rf_weighted.fit(X_train, y_train)
# Predict the test data with the trained model
y_predict = rf_weighted.predict(X_test)
#Print accuracy score and classification report
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
#Plot confusion matrix
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, X_test, y_test, cmap ='cividis', ax=ax)以下は出力です。

クラスの重みを追加したことで、モデルの性能が向上し、正確度が99.2%になりました。
「Fresh」ラベルの正しい予測数も1つ増えました。
データの不均衡問題に対処するためにクラスの重みを使用することは、トレーニングフェーズ全体でより重要な重みを持つラベルにモデルがより注意を払うようにするため、有用な方法です。
このデータサイエンスプロジェクトへのリンク: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
Nate Rosidiはデータサイエンティストであり、プロダクト戦略における役割を担当しています。また、アナリティクスを教える非常勤講師でもあり、StrataScratchというトップ企業からの実際のインタビューの質問を用いて、データサイエンティストがインタビューに備えるのを支援するプラットフォームの創設者でもあります。Twitter: StrataScratchまたはLinkedInで彼とつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
