AWS上で動作する深層学習ベースの先進運転支援システムのための自動ラベリングモジュール
'AWS上で動作する自動ラベリングモジュール'
コンピュータビジョン(CV)では、興味のあるオブジェクトを識別するためのタグを追加したり、オブジェクトの位置を特定するための境界ボックスを追加することをラベリングと呼びます。これは、深層学習モデルを訓練するためのトレーニングデータを準備するための事前のタスクの1つです。さまざまなCVのユースケースで、高品質なラベルを画像やビデオから生成するために何十万時間もの作業時間が費やされています。これらのラベルを作成するために、Amazon SageMaker Data Labelingを次の2つの方法で使用できます:
- Amazon SageMaker Ground Truth Plus-このサービスは、MLタスクに訓練された専門の労働力を提供し、データのセキュリティ、プライバシー、規制要件を満たすのに役立ちます。データをアップロードすると、Ground Truth Plusチームがデータラベリングのワークフローと労働力を代わりに作成および管理します。
- Amazon SageMaker Ground Truth-または、独自のデータラベリングのワークフローと労働力を管理して、データにラベルを付けることもできます。
特に、深層学習ベースの自律走行車(AV)および高度運転支援システム(ADAS)では、同期したLiDAR、RADAR、およびマルチカメラのストリームを含む複雑なマルチモーダルデータにラベルを付ける必要があります。例として、以下の図には、LiDARデータのポイントクラウドビューに車の周りに3Dバウンディングボックスが表示され、側面に直交したLiDARビュー、およびバウンディングボックスのプロジェクトされたラベルを持つ7つの異なるカメラストリームが表示されています。
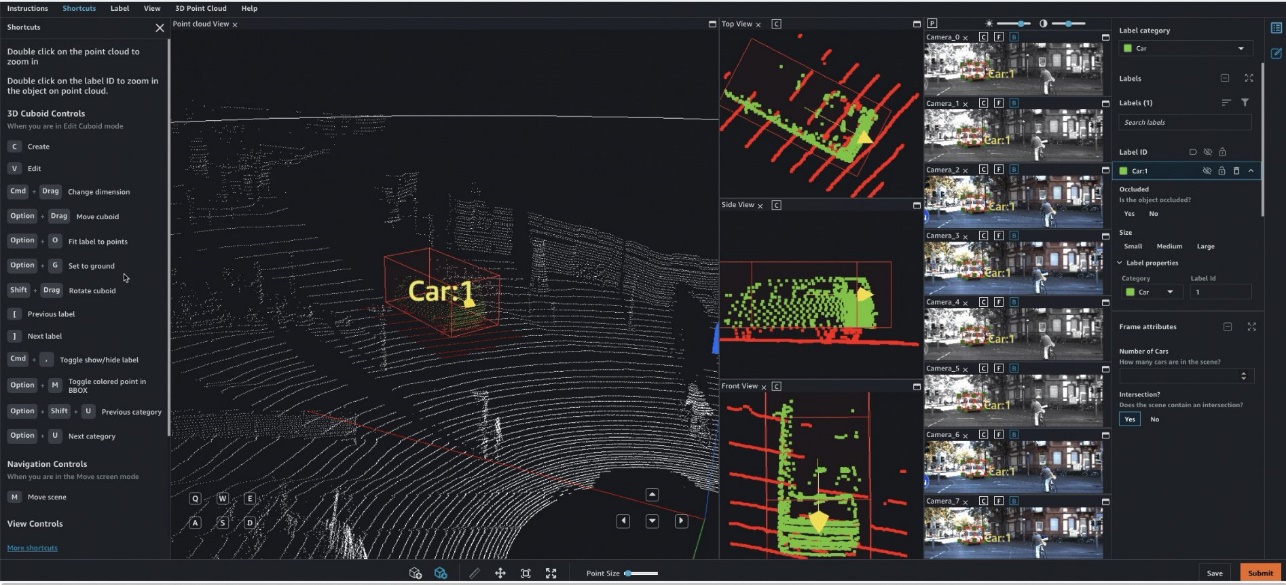
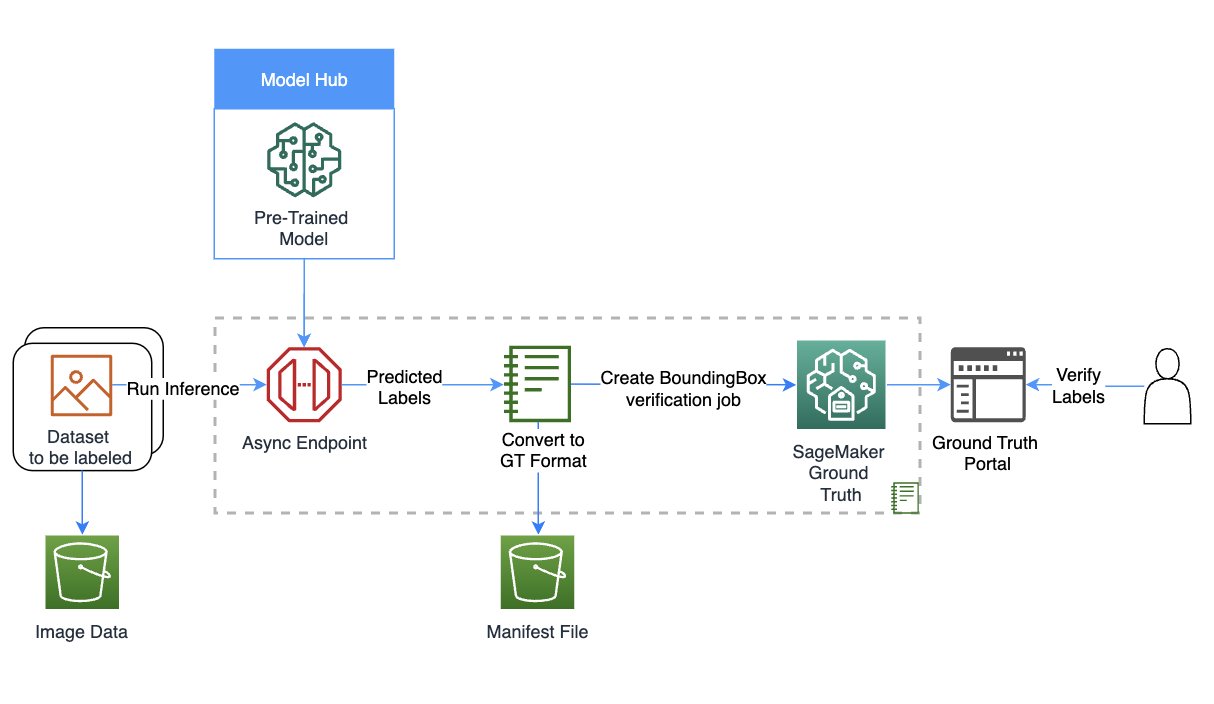
AV/ADASチームは、数千のフレームにラベルを付ける必要があり、ラベルの統合、自動キャリブレーション、フレームの選択、フレームシーケンスの補間、アクティブラーニングなどの手法に頼ることで、単一のラベル付きデータセットを取得します。Ground Truthはこれらの機能をサポートしています。機能の詳細は、Amazon SageMaker Data Labeling Featuresを参照してください。ただし、数万マイルに及ぶ録画されたビデオとLiDARデータに対してラベルを付けることは、AV/ADASシステムを作成する企業にとっては困難で、費用がかかり、時間がかかります。この問題を解決するために現在使用されている手法の1つは、オートラベリングです。これは、AWS上のADASのモジュラーファンクションデザインの次の図で強調されています。

このポストでは、SageMakerの機能(Amazon SageMaker JumpStartモデルや非同期推論機能)を使用し、Ground Truthの機能と組み合わせてオートラベリングを実行する方法を示します。
オートラベリングの概要
オートラベリング(時にはプリラベリングとも呼ばれる)は、手動ラベリングタスクの前または並行して行われます。このモジュールでは、特定のタスク(例:歩行者検出またはレーンセグメンテーション)に対してトレーニングされた最善のモデルを使用して、高品質なラベルを生成します。手動のラベラーは、生成されたデータセットのラベルを単に検証または調整するだけです。これは、これらの大規模なデータセットをゼロからラベル付けするよりも簡単で、高速で、安価です。トレーニングまたはバリデーションモジュールなどのダウンストリームモジュールは、これらのラベルをそのまま使用できます。
アクティブラーニングは、オートラベリングに密接に関連する別の概念です。これは、従業員がラベルを付ける必要があるデータを特定する機械学習(ML)の技術です。Ground Truthの自動データラベリング機能はアクティブラーニングの例です。Ground Truthが自動データラベリングジョブを開始すると、入力データオブジェクトのランダムなサンプルが選択され、人間の労働者に送信されます。ラベル付きデータが返されると、それを使用してトレーニングセットとバリデーションセットが作成されます。Ground Truthは、これらのデータセットを使用して、オートラベリングに使用するモデルをトレーニングおよびバリデーションします。その後、Ground Truthはバッチ変換ジョブを実行して、未ラベルのデータに対するラベルと新しいデータの信頼スコアを生成します。信頼スコアの低いラベル付きデータは、人間のラベラーに送信されます。このトレーニング、バリデーション、バッチ変換のプロセスは、データセット全体がラベル付けされるまで繰り返されます。
対照的に、オートラベリングは、高品質の事前トレーニング済みモデルが存在することを前提としています(会社内部でプライベートに存在するか、ハブ内で公開されている)。このモデルは、信頼できるラベルを生成するために使用され、ラベルの検証タスク、トレーニング、シミュレーションなどのダウンストリームタスクに使用できます。AV/ADASシステムの場合、この事前トレーニング済みモデルは車のエッジに展開され、クラウド上で大規模なバッチ推論ジョブで使用され、高品質なラベルが生成されます。
JumpStartは、幅広い問題タイプに対する事前トレーニング済みのオープンソースモデルを提供し、機械学習の始め方をサポートします。JumpStartを使用して、組織内でモデルを共有することができます。さあ、始めましょう!
ソリューションの概要
この投稿では、例のノートブックのすべてのセルを説明することなく、主要な手順を概説します。一緒に進めたり、自分で試したりするには、Amazon SageMaker StudioでJupyterノートブックを実行できます。
次の図は、ソリューションの概要を示しています。
役割とセッションの設定
この例では、ml.m5.largeインスタンスタイプのStudioでData Science 3.0カーネルを使用しました。最初に、基本的なインポートと後でノートブックで使用するための役割とセッションの設定を行います:
import sagemaker, boto3, json
from sagemaker import get_execution_role
from utils import *SageMakerを使用してモデルを作成する
このステップでは、自動ラベリングタスク用のモデルを作成します。モデルを作成するための3つのオプションから選択できます:
- JumpStartからモデルを作成する – JumpStartを使用すると、事前にトレーニングされたモデルで推論を実行できます。新しいデータセットでファインチューニングする必要はありません
- チームまたは組織と共有されたJumpStartを使用する – 組織内のチームが開発したモデルを使用したい場合にこのオプションを使用できます
- 既存のエンドポイントを使用する – アカウントに既にデプロイされているモデルがある場合にこのオプションを使用できます
最初のオプションを使用するには、JumpStartからモデルを選択します(ここでは、mxnet-is-mask-rcnn-fpn-resnet101-v1d-cocoを使用します)。モデルのリストは、JumpStartが提供するmodels_manifest.jsonファイルで利用できます。
このJumpStartモデルは、インスタンスセグメンテーションタスクで公開されてトレーニングされたものですが、プライベートモデルも使用できます。以下のコードでは、image_uris、model_uris、script_urisを使用して、このMXNetモデルをsagemaker.model.Model APIでモデルを作成するための適切なパラメータ値を取得します:
from sagemaker import image_uris, model_uris, script_uris, hyperparameters
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
endpoint_name = name_from_base(f"jumpstart-example-infer-{model_id}")
inference_instance_type = "ml.p3.2xlarge"
# 推論用のDockerコンテナURIを取得します
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # model_idから自動的に推論されます
image_scope="inference",
model_id=model_id,
model_version=model_version,
instance_type=inference_instance_type,
)
# 推論スクリプトのURIを取得します。モデルのロード、推論処理などのスクリプトが含まれます。
deploy_source_uri = script_uris.retrieve(
model_id=model_id, model_version=model_version, script_scope="inference"
)
# ベースモデルのURIを取得します
base_model_uri = model_uris.retrieve(
model_id=model_id, model_version=model_version, model_scope="inference"
)
# SageMakerモデルインスタンスを作成します
model = Model(
image_uri=deploy_image_uri,
source_dir=deploy_source_uri,
model_data=base_model_uri,
entry_point="inference.py", # source_dir内のエントリーポイントファイルで、deploy_source_uriに存在するもの
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
)非同期推論とスケーリングの設定
モデルをデプロイする前に、非同期推論の設定を行います。非同期推論を選択した理由は、大きなペイロードサイズを処理できるため、ほぼリアルタイムのレイテンシ要件を満たすことができるためです。さらに、エンドポイントを自動スケーリングして、リクエストの処理がない場合にインスタンス数をゼロに設定するスケーリングポリシーを適用することもできます。以下のコードでは、max_concurrent_invocations_per_instanceを4に設定しています。また、エンドポイントを必要に応じてスケールアップし、自動ラベリングジョブが完了した後にゼロにスケールダウンするように自動スケーリングを設定しています。
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
async_config = AsyncInferenceConfig(
output_path=f"s3://{sess.default_bucket()}/asyncinference/output",
max_concurrent_invocations_per_instance=4)
.
.
.
response = client.put_scaling_policy(
PolicyName="Invocations-ScalingPolicy",
ServiceNamespace="sagemaker", # リソースを提供するAWSサービスの名前空間
ResourceId=resource_id, # エンドポイント名
ScalableDimension="sagemaker:variant:DesiredInstanceCount", # SageMakerはインスタンス数のみサポート
PolicyType="TargetTrackingScaling", # 'StepScaling'|'TargetTrackingScaling'
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 5.0, # メトリックのターゲット値。ここではメトリックはSageMakerVariantInvocationsPerInstance
"CustomizedMetricSpecification": {
"MetricName": "ApproximateBacklogSizePerInstance",
"Namespace": "AWS/SageMaker",
"Dimensions": [{"Name": "EndpointName", "Value": endpoint_name}],
"Statistic": "Average",
},
"ScaleInCooldown": 300,
"ScaleOutCooldown": 300
},
)データのダウンロードと推論の実行
AWSオープンデータカタログのFord Multi-AV Seasonalデータセットを使用します。
まず、推論のためのデータをダウンロードして準備します。ノートブックではデータセットの前処理手順を提供していますが、データセットに応じて変更することができます。そして、SageMaker APIを使用して非同期の推論ジョブを次のように開始できます:
import glob
import time
max_images = 10
input_locations,output_locations, = [], []
for i, file in enumerate(glob.glob("data/processedimages/*.png")):
input_1_s3_location = upload_image(sess,file,sess.default_bucket())
input_locations.append(input_1_s3_location)
async_response = base_model_predictor.predict_async(input_path=input_1_s3_location)
output_locations.append(async_response.output_path)
if i > max_images:
breakこれには、非同期の推論にアップロードしたデータの量に応じて、最大30分以上かかる場合があります。次のように、これらの推論のうちの1つを可視化できます:
plot_response('data/single.out')
非同期の推論の出力をGround Truthの入力マニフェストに変換する
このステップでは、Ground Truthでのバウンディングボックスの検証ジョブのための入力マニフェストを作成します。Ground TruthのUIテンプレートとラベルカテゴリファイルをアップロードし、検証ジョブを作成します。この記事にリンクされたノートブックでは、プライベートワークフォースを使用してラベリングを実行していますが、他のタイプのワークフォースを使用する場合はこれを変更できます。詳細については、ノートブックの完全なコードを参照してください。
Ground Truthでの自動ラベリングプロセスからラベルを検証する
このステップでは、ラベリングポータルにアクセスして検証を完了します。詳細については、こちらを参照してください。
ワークフォースメンバーとしてポータルにアクセスすると、JumpStartモデルによって作成されたバウンディングボックスを表示し、必要に応じて調整することができます。

このテンプレートを使用して、タスク固有のモデルで自動ラベリングを繰り返し実行し、ラベルをマージし、生成されたラベル付きデータセットを下流のタスクで使用することができます。
クリーンアップ
このステップでは、以前のステップで作成したエンドポイントとモデルを削除してクリーンアップします:
# SageMakerエンドポイントの削除
base_model_predictor.delete_model()
base_model_predictor.delete_endpoint()結論
この記事では、JumpStartと非同期の推論を使用した自動ラベリングプロセスについて説明しました。自動ラベリングプロセスの結果を使用して、実世界のデータセットでラベル付けデータを変換して可視化する方法を示しました。このソリューションを使用して、タスク固有の多くのモデルで自動ラベリングを実行し、ラベルをマージして生成されたラベル付きデータセットを下流のタスクで使用することができます。また、自動ラベリングプロセスの一環としてSegment Anything Modelなどのツールを使用してセグメントマスクを生成することも検討できます。このシリーズの将来の記事では、パーセプションモジュールとセグメンテーションについて詳しく説明します。JumpStartと非同期の推論についての詳細は、それぞれSageMaker JumpStartとAsynchronous inferenceを参照してください。このコンテンツをAV/ADAS以外のユースケースに再利用し、お困りの際にはAWSにお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 光ニューラルネットワークとトランスフォーマーモデルを実行した場合、どのようなことが起こるのでしょうか?
- このAIツールは、AIが画像を「見る」方法と、なぜアストロノートをシャベルと間違える可能性があるのかを説明します
- Field Programmable Gate Array(FPGA)とは何ですか:人工知能(AI)におけるFPGA vs. GPU
- Google AIは、MediaPipe Diffusionプラグインを導入しましたこれにより、デバイス上で制御可能なテキストから画像生成が可能になります
- SalesforceはXGen-7Bを導入:1.5Tトークンのために8Kシーケンス長でトレーニングされた新しい7B LLMを紹介します
- AIの相互作用を変革する:LLaVARは視覚とテキストベースの理解において優れた性能を発揮し、マルチモーダルな指示従属モデルの新時代を切り開く
- LLM(Large Language Models)は、厳密に検証可能な数学的証明を生成できるのでしょうか?LeanDojoにご参加ください:Lean Proof Assistantで形式的な定理を証明するためのツールキット、ベンチマーク、およびモデルを備えたオープンソースのAIプレイグラウンド






