AIが私たちのコーディング方法を変えていく方法
AIがコーディング方法を変える方法
ChatGPTとStack Overflowからの証拠

要約: この記事では、AIと仕事に関する私の最新の研究の概要(AIが生産性に与える影響を探りながら、長期的な効果についての議論を展開)、ChatGPTとStack Overflowを用いた準実験的手法(差分の差法)の例、そして簡単なSQLクエリでStack Overflowからデータを抽出する方法を紹介します。
完全な科学論文へのリンク(引用してください): https://arxiv.org/abs/2308.11302
ほとんどの技術革命と同様に、ChatGPTのリリースは魅了と恐怖と共に行われました。一方で、たった2ヶ月で1億人以上の月間アクティブユーザーを獲得し、歴代最速の成長を遂げた消費者向けアプリとなりました。他方で、ゴールドマン・サックスの報告書によれば、このような技術は世界中で3億人以上の雇用を置き換える可能性があるとされています [1]。さらに、イーロン・マスクを含む1,000人以上の技術リーダーや研究者が最先端のAI開発の一時停止を求める公開書簡に署名しました [2]。
“私たちは先のことを予見することはできないが、やるべきことはたくさんある。” アラン・チューリング
アラン・チューリングの引用に則り、この記事はAIの遠い未来やその影響を豪快に予測することを目指していません。しかし、私は私たちに影響を与える主要な観測可能な結果に焦点を当てています:AIが私たちのコーディングのやり方を変えているということです。
ChatGPTの誕生により世界は変わりました。少なくとも、毎日コーディングをする人として、私の世界は一夜にして変わりました。正しい解決策を見つけるためにGoogleで数時間を費やすことや、Stack Overflowの回答を探し出し、解決策を自分の問題に合わせて適切な変数名や行列の次元に翻訳することをやめ、代わりにChatGPTに質問するだけで済むようになりました。このチャットボットは瞬時に答えを教えてくれるだけでなく、それが私の具体的な状況に合致している(例:正しい名前、データフレームの次元、変数の型など)のです。私は感動し、生産性が急激に向上しました。
したがって、ChatGPTのリリースの大規模な効果と生産性、そして最終的には私たちの働き方に与える潜在的な影響を探ることにしました。私はStack Overflowのデータを使用して、以下の3つの仮説(H)を検証しました。
H1: ChatGPTはStack Overflowでの質問数を減少させる。 ChatGPTが数秒でコーディングの問題を解決できるなら、質問をすることや回答を待つことに時間がかかるコーディングコミュニティプラットフォーム上での質問数の減少が予想されます。
H2: ChatGPTは質問の品質を向上させる。 ChatGPTが広く使用されている場合、Stack Overflow上の残りの質問はより詳細に文書化される必要があります。なぜなら、ChatGPTがすでに少し助けている可能性があるからです。
H3: 残りの質問はより複雑です。 残りの質問はより難解である可能性があるため、回答がChatGPTでは得られない可能性があります。したがって、私たちは未回答の質問の割合が増加するかどうかを検証します。さらに、質問ごとの閲覧数が変化するかどうかも検証します。質問ごとの閲覧数が安定している場合、残りの質問の複雑さが増加していることと、この結果がプラットフォーム上の活動の減少だけで引き起こされているわけではないことを示す追加の証拠となります。
これらの仮説を検証するために、私はStack Overflow上でのChatGPTの突然のリリースを利用します。2022年11月、OpenAIがチャットボットを公開した際、他の代替手段(例:Google Bard)は利用できず、アクセスも無料でした(OpenAI ChatGPT 4やCode Interpreterのような有料サブスクリプションに限定されていませんでした)。そのため、このオンラインコーディングコミュニティにおけるアクティビティがショック前後でどのように変化したかを観察することが可能です。ただし、このショックがいかに「クリーン」であるとしても、他の効果によって潜在的な誤差が生じる可能性があり、因果関係に疑問が生じます。特に、季節性(例:リリース後の年末休暇)や、質問が新しいほど閲覧数が低くなり、回答が見つかる確率も低くなるという事実が影響を及ぼす可能性があります。
理想的には、季節性などの潜在的な混乱要因の影響を軽減し、因果関係を測定するためにChatGPTリリース前の世界を観察したいところですが、それは不可能です(因果推論の根本的な問題です)。ただし、私はChatGPTのコーディング関連の回答の品質が言語によって異なることを利用し、準実験的手法(差分の差法)を使用して他の要因が効果に混入するリスクを制限します。
そこで、私はPythonとRのStack Overflow上の活動を比較します。Pythonは、おそらく最も人気のあるプログラミング言語の1つであるため、明らかな選択肢です(例:TIOBEプログラミングコミュニティインデックスで1位にランクされています)。Pythonにはオンライン上で利用できる豊富なリソースがあり、ChatGPTのようなチャットボットのトレーニングセットとして使用できます。そして、Pythonと比較するために、私はRを選びました。PythonはしばしばRの最適な代替として引用され、どちらも無料で利用できます。ただし、Rはある程度人気が低いです(例:TIOBEプログラミングコミュニティインデックスで16位)。そのため、トレーニングデータは小さくなる可能性があり、ChatGPTのパフォーマンスが低下する可能性があります。聞き取り調査の結果、この違いが確認されました(方法の詳細は「方法」セクションに記載)。したがって、RはPythonにとって有効な対照事実を表しています(季節性の影響を受けますが、ChatGPTの影響は無視できると予想されます)。
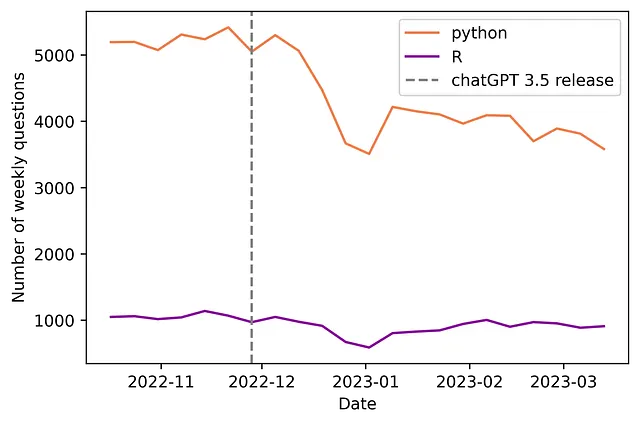
上記の図は、生の週次データを示しています。ChatGPT 3.5のリリース後、Pythonに関するStack Overflow上の週ごとの質問数が急激に減少しました(21.2%の減少)。一方、Rに対する影響は多少小さく(15.8%の減少)なりました。
これらの「質的」な観察結果は、統計モデルによっても確認されています。後で説明する計量経済学モデルでは、Stack Overflow上のPythonの週ごとの質問数が平均で937.7(95%CI:[-1232.8、-642.55];p値=0.000)減少していることが統計的に有意であると見つけました。Diff-in-Diff法を利用した後続の分析では、質問の品質の向上(プラットフォーム上でのスコアによって測定)と、未解決の質問の割合の増加が明らかになりました(一方、質問ごとの平均閲覧数は変わらないようです)。したがって、この研究は、先に定義された3つの仮説に対する証拠を提供しています。
これらの結果は、AIが私たちの仕事において重要な役割を果たしていることを強調しています。生成的AIによって日常の問い合わせに対応することで、個人はより複雑なタスクに取り組むことができ、生産性を向上させることができます。ただし、議論のセクションで重要な長期的な潜在的な逆効果についても議論されています。
この記事の残りの部分では、データと方法を説明し、その後結果を示し、ディスカッションで締めくくります。
データ
データは、Stack Overflowデータエクスプローラーポータル(ライセンス:CC BY-SA)でのSQLクエリを使用して抽出されました。以下に使用したSQLコマンドを示します:
SELECT Id, CreationDate, Score, ViewCount, AnswerCountFROM PostsWHERE Tags LIKE '%<python>%'AND CreationDate BETWEEN '2022–10–01' AND '2023–04–30'AND PostTypeId = 1;次に、ノイズを減らすためにデータを週ごとに集計し、2022年10月17日から2023年3月19日までのデータセットを取得しました。このデータセットには、週ごとの投稿数、閲覧数、質問あたりの閲覧数、質問ごとの平均スコア、未解決の質問の割合の情報が含まれています。スコアは、質問が「研究の努力があり、有用で明確である」とユーザーによって投票されたものです。
方法
因果効果を測定するために、私はDiff-in-Diffモデルを使用しています。これは、通常は時間の経過による変化を利用し、処理された単位(たとえばPythonの質問)と未処理のグループを比較する計量経済学的な方法です。この方法について詳しく知りたい場合は、次の2つの無料の電子書籍でこの方法に言及されている章を読むことをおすすめします:Causal Inference for the Brave and TrueとCausal Inference: The Mixtape。
簡単に言えば、Diff-in-Diffモデルは、因果効果を特定するためにダブルディファレンスを計算します。まず、処理された単位(Pythonの質問におけるChatGPTのリリースの効果)について、処理前(ChatGPTのリリース前)と処理後の期間の2つの単純な差を計算します。しかし、前述のように、処理と関連する別の効果(たとえば季節性)がまだ混同要因となっている可能性があります。この問題に対処するために、モデルではダブルディファレンスを計算し、処理された部分(Python)の最初の差が、制御グループ(R)の2つ目の差と異なるかどうかを確認します。制御グループには処理効果(または無視できる程度の効果)が期待される一方で、季節性などが影響を与える可能性があるため、この潜在的な混同要因を排除し、因果効果を測定できます。
ここでは、やや形式的な表現を示します。
処置群の最初の差:
E[Yᵢₜ| Treatedᵢ, Postₜ]-E[Yᵢₜ| Treatedᵢ, Preₜ] = λₜ+β
ここで、iとtはそれぞれ言語(RまたはPython)と週を指し、treatedはPythonに関連する質問を指し、PostはChatGPTが利用可能な期間を指します。この単純な差は、ChatGPTの因果効果(β)と一部の時間効果λₜ(例:季節性)を表す可能性があります。
対照群の最初の差:
E[Yᵢₜ| Controlᵢ, Postₜ]-E[Yᵢₜ| Controlᵢ, Preₜ] = λₜ
対照群の単純な差は、処置効果を含まず(未処置であるため)、λₜのみを含みます。
したがって、ダブルディファレンスは以下のようになります:
DiD = ( λₜ+β) — λₜ = β
両群においてλₜが同一であるという仮定の下で(平行な傾向の仮定、後述)、ダブルディファレンスを用いて因果効果βを特定することができます。
このモデルの本質は、平行な傾向の仮定にあります。因果効果を主張するためには、ChatGPTがない場合でも、Python(処置群)とR(未処置群)のStack Overflow上の投稿の進化が治療期間(2022年11月以降)において同じであるという確信を持つ必要があります。しかし、これは明らかに観察することができないため、直接テストすることもできません(因果推論の根本的な問題を参照)。 (この概念と因果推論について詳しく学びたい場合は、Towards Data Scienceの私のビデオや記事をご覧ください:因果関係の科学と芸術)。ただし、ショック前の傾向が平行であるかどうかをテストすることは可能であり、これにより、対照群が潜在的に良い「対照事実」となる可能性があります。データを用いた2つの異なるプラセボテストの結果、ChatGPTの前の期間では平行な傾向の仮定を棄却することはできないことが示されました(各テストのp値はそれぞれ0.722と0.397です(オンラインの付録Bを参照))。
形式的な定義:
Yᵢₜ = β₀ + β₁ Pythonᵢ + β₂ ChatGPTₜ + β₃ Pythonᵢ × ChatGPTₜ + uᵢₜ
ここで、「i」と「t」はそれぞれStack Overflowの質問のトピック(i ∈ {R; Python})と週を表し、Yᵢₜはアウトカム変数を表します:質問の数(H1)、平均質問スコア(H2)、未回答の質問の割合(H3)。Pythonᵢは、質問がPythonに関連している場合に値が1になり、それ以外の場合は0になるバイナリ変数です。ChatGPTₜは、ChatGPTのリリース以降に1の値を取り、それ以外の場合は0になる別のバイナリ変数です。uᵢₜは、コーディング言語レベル(i)でクラスタリングされた誤差項です。
このモデルの本質は、平行な傾向の仮定にあります。因果効果を主張するためには、ChatGPTがない場合でも、Python(処置群)とR(未処置群)のStack Overflow上の投稿の進化が治療期間(2022年11月以降)において同じであるという確信を持つ必要があります。しかし、これは明らかに観察することができないため、直接テストすることもできません(因果推論の根本的な問題を参照)。 (この概念と因果推論について詳しく学びたい場合は、「The Science and Art of Causality」の私のビデオや記事をご覧ください)。ただし、ショック前の傾向が平行であるかどうかをテストすることは可能であり、これにより、対照群が良い「対照事実」となる可能性があります。この場合、データを用いた2つの異なるプラセボテストによって、ChatGPTの前の期間では平行な傾向の仮定を棄却することはできないことが示されました(各テストのp値はそれぞれ0.722と0.397です(オンラインの付録Bを参照))。
結果
H1: ChatGPTはStack Overflowでの質問数を減少させる。
導入で述べたように、Diff-in-Diffモデルによると、Stack OverflowのPythonにおける週ごとの質問数は937.7(95% CI:[-1232.8、-642.55]、p値=0.000)減少しました(図2参照)。これは週ごとの質問数の18%の減少を表します。
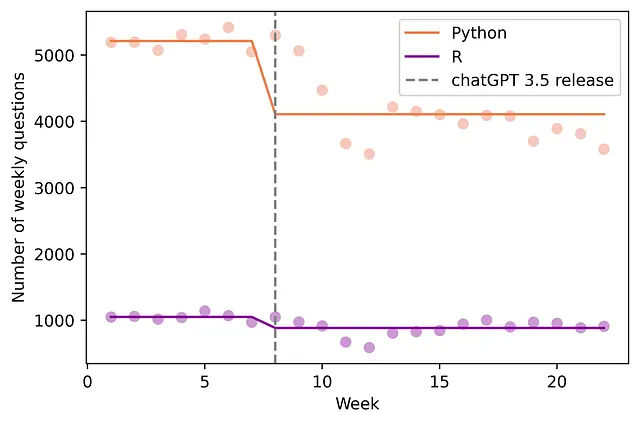
H2: ChatGPTは質問の質を向上させます。
ChatGPTは質問に回答するのに役立つかもしれません(H1を参照)。しかし、チャットボットが問題を解決できない場合、問題や解決策の要素についてさらに情報を得ることができる可能性があります。このプラットフォームでは、ユーザーは各質問について「この質問は研究努力があり、有用で明確である」と思う場合はスコアを1ポイント増やし、そうでない場合はスコアを1ポイント減らすことができるため、この仮説を検証することができます。この2回帰分析によると、質問のスコアは平均で0.07ポイント増加します(95%CI:[-0.0127 , 0.1518 ]; p値:0.095)(図3を参照)。これは41.2%増加を表します。

H3: 残りの質問はより複雑です。
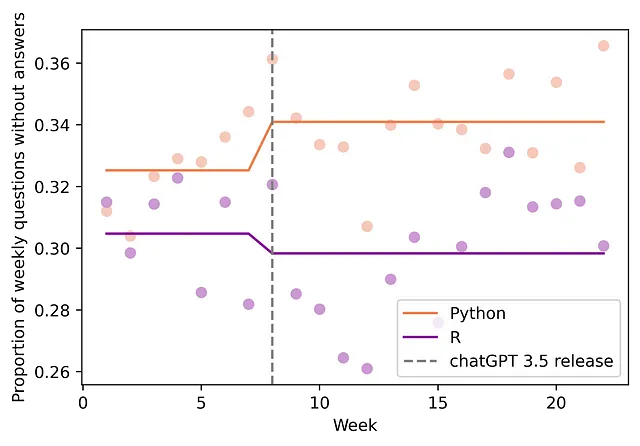
ChatGPTが有意な助けを提供できること(質問を解決し、他の質問を文書化する)の一部の証拠があるので、残りの質問がより複雑であることを確認したいと考えています。そのために、2つのことを調べることにします。まず、未回答の質問の割合が上昇していることを発見しました(未回答は質問がより複雑である兆候である可能性があります)。具体的には、未回答の質問の割合が2.21ポイント増加しました(95%CI:[ 0.12, 0.30]; p値:0.039)(図4を参照)。これは6.8%の増加を表します。次に、質問ごとの閲覧数が変わっていないことも分かりました(閲覧数が変わらないという帰無仮説を棄却することはできず、p値は0.477です)。この2つ目のテストにより、未回答の質問がトラフィックの低下によるものではないという代替説明を一部排除することができます。
議論
これらの結果は、生成AIが日常的な質問に対処することで、私たちが専門知識を必要とするより複雑な問題に集中することができるなど、私たちの仕事を革新する可能性を支持しています。
この約束は興味深いものですが、その裏には逆の影響があります。まず、低質な仕事はチャットボットに置き換えられるかもしれません。次に、そのようなツールは学習方法に(否定的な)影響を与えるかもしれません。個人的には、コーディングは自転車や水泳のようなものだと考えています。動画を見たり授業を受けたりするだけでは十分ではありません。自分自身で試して失敗する必要があります。回答が良すぎて勉強を強制しないと、多くの人々が学習に苦労するかもしれません。さらに、Stack Overflow上の質問の数が減少すると、生成AIモデルの訓練セットの貴重な情報源が減少する可能性があり、長期的なパフォーマンスに影響を与えるかもしれません。
これらの長期的な悪影響はまだ明確ではなく、注意深い分析が必要です。コメントでご意見をお聞かせください。
[0] Gallea, Quentin. “From Mundane to Meaningful: AI’s Influence on Work Dynamics — evidence from ChatGPT and Stack Overflow” arXiv econ.GN (2023)
[1] Hatzius, Jan. “The Potentially Large Effects of Artificial Intelligence on Economic Growth (Briggs/Kodnani).” Goldman Sachs (2023).
[2] https://www.nytimes.com/2023/03/29/technology/ai-artificial-intelligence-musk-risks.html
[3] Bhat, Vasudev, et al. “Min (e) d your tags: Analysis of question response time in stackoverflow.” 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014). IEEE, (2014)
[2] https://www.nytimes.com/2023/03/29/technology/ai-artificial-intelligence-musk-risks.html
[3] バット、ヴァスデヴ、他。 “Min(e)d your tags:stackoverflowでの質問の応答時間の分析”。 2014年IEEE / ACM国際会議「ソーシャルネットワーク分析とマイニングの進歩(ASONAM 2014)」。 IEEE、(2014)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





