Acme 分散強化学習のための新しいフレームワーク
'Acme 分散強化学習の新しいフレームワーク'
全体的に、Acmeの高レベルの目標は以下の通りです:
- 手法と結果の再現性を可能にすること — これにより、RL問題が困難または容易になる要素が明確になります。
- 新しいアルゴリズムの設計を(自分たちとコミュニティ全体で)簡素化すること — 次のRLエージェントを誰でもより簡単に作成できるようにしたいです!
- RLエージェントの可読性を向上させること — 論文からコードに移行する際に隠れた驚きがないようにします。
これらの目標を達成するために、Acmeの設計は大規模、VoAGI、および小規模な実験のギャップを埋めるようになっています。これはさまざまなスケールでエージェントの設計について注意深く考えることで実現されました。
最上位レベルでは、Acmeを環境に接続する(つまり、アクションを選択するエージェント)と環境を接続する古典的なRLインターフェース(導入的なRLテキストで見つけることができます)と考えることができます。このエージェントは、アクションの選択、観察の作成、自己の更新のためのメソッドを持つシンプルなインターフェースです。内部的には、学習エージェントは問題を「行動」と「データからの学習」のコンポーネントに分割します。表面的には、これにより、さまざまなエージェント間で行動の部分を再利用することができます。しかし、もっと重要なことは、これが学習プロセスを分割し並列化するための重要な境界を提供することです。ここからさらにスケールダウンし、環境が存在せず固定のデータセットのみ存在するバッチRL設定にもシームレスに対応することができます。これらの異なる複雑さのレベルのイラストを以下に示します:
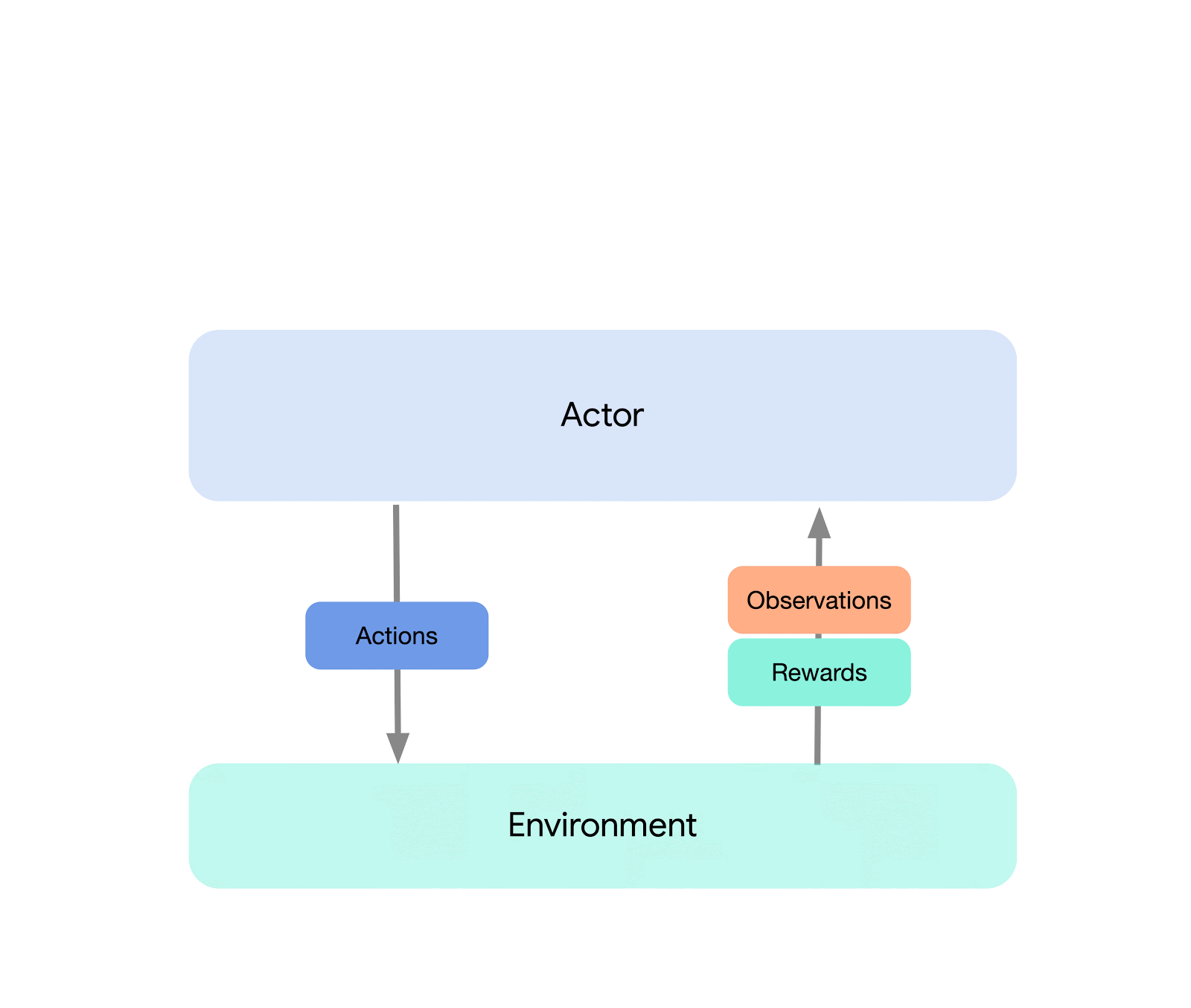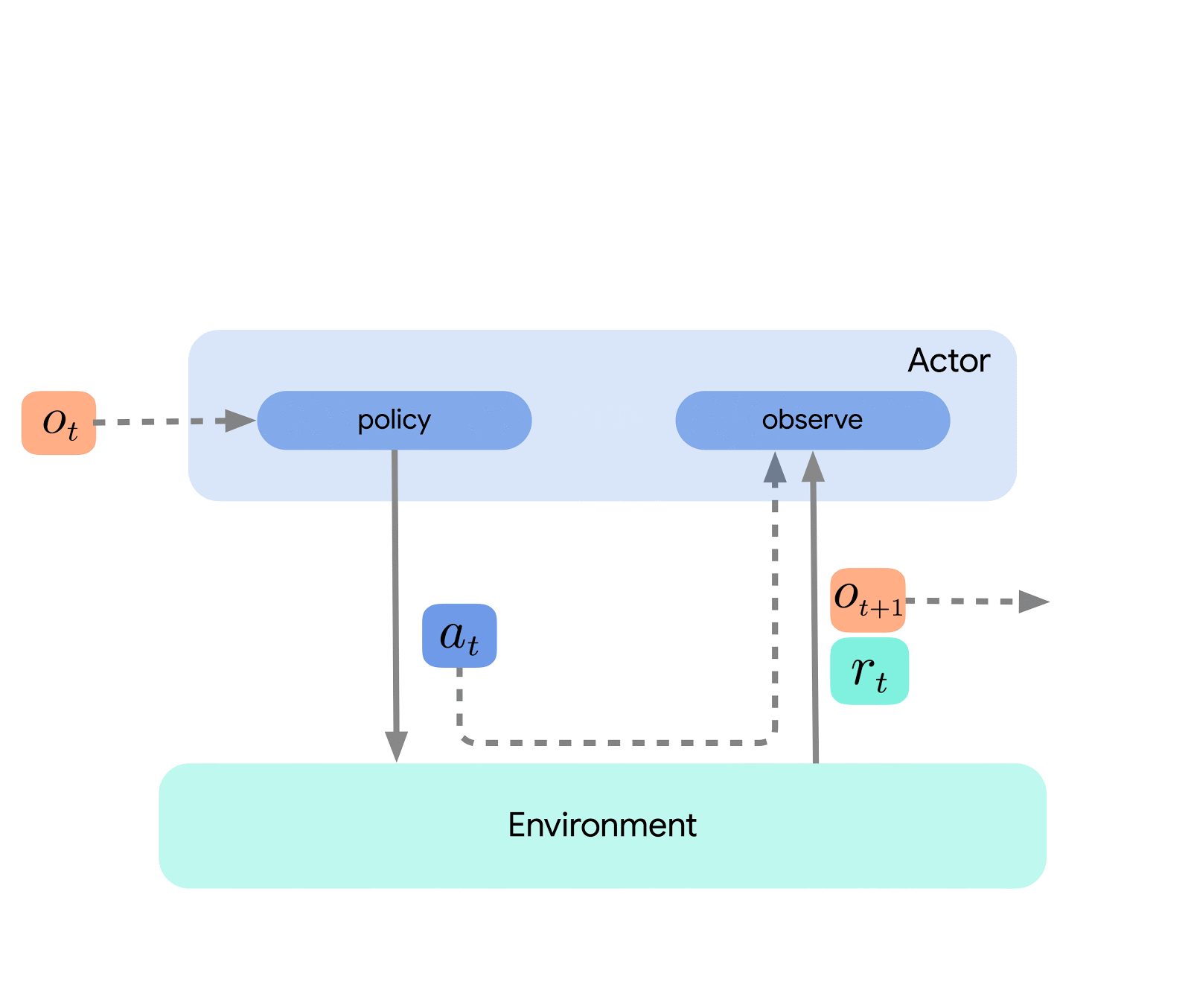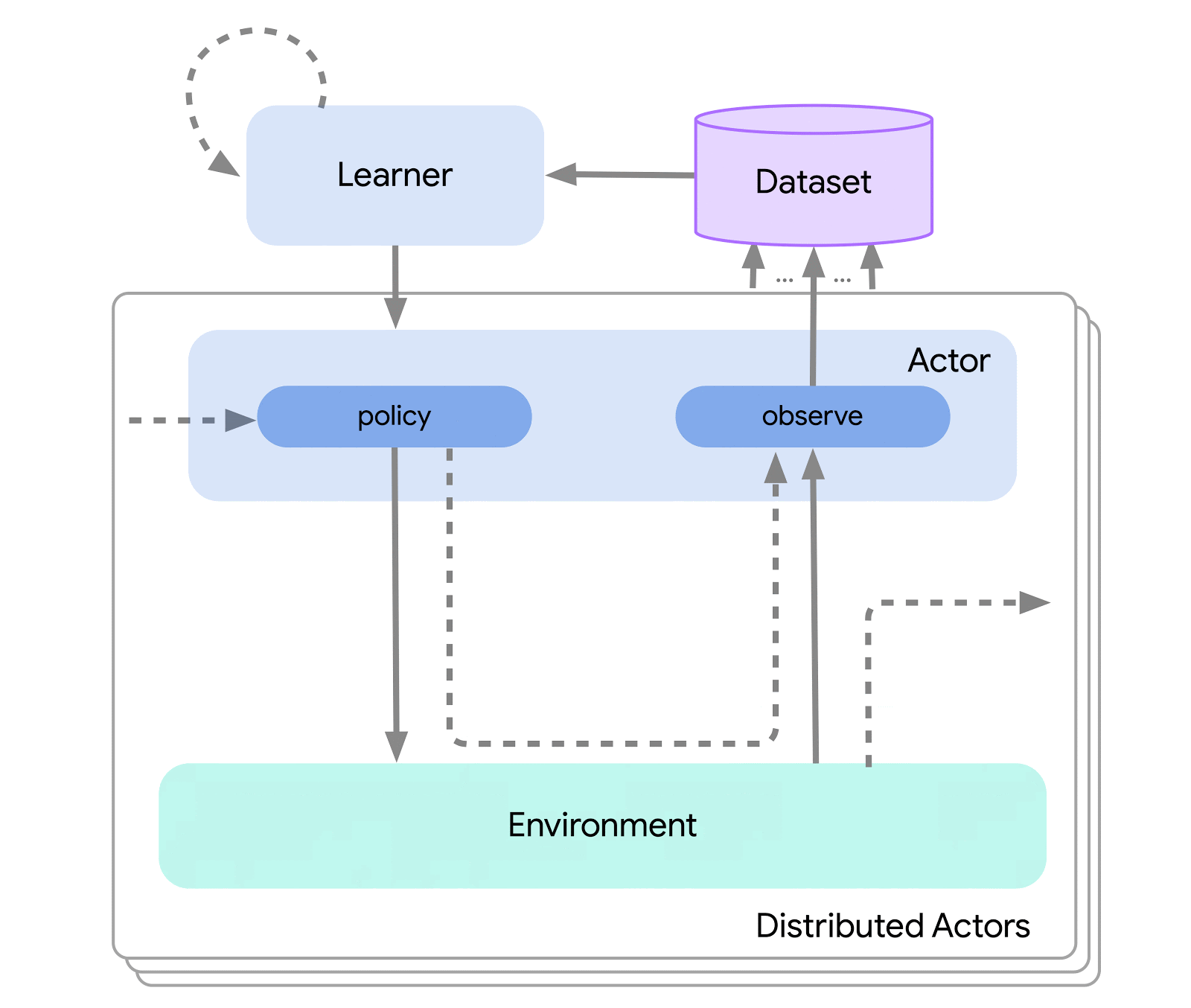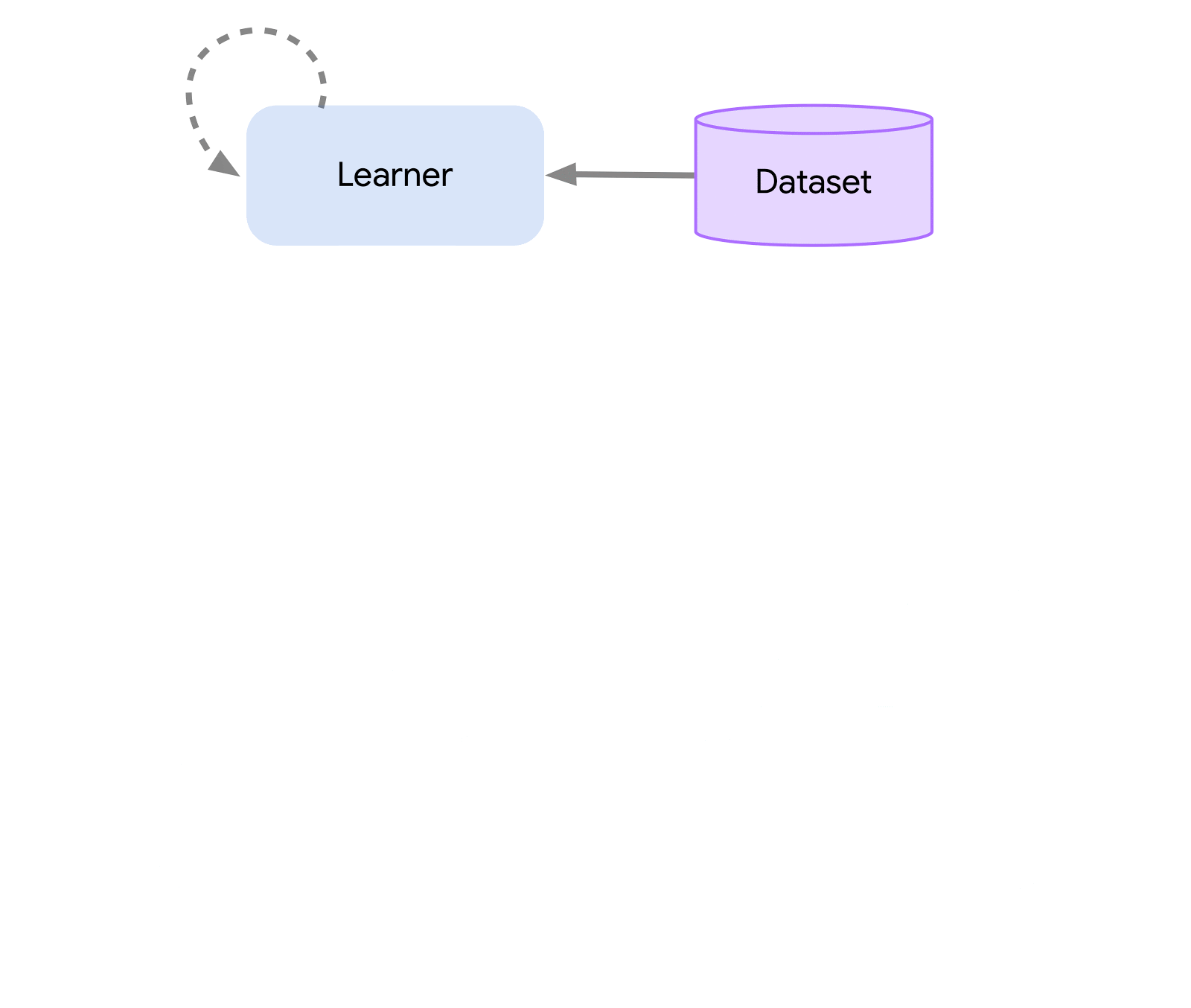
この設計により、同じ行動と学習コードを使用しながら、小規模なシナリオで新しいエージェントを簡単に作成、テスト、デバッグすることができます。Acmeは、チェックポイント、スナップショット、低レベルの計算支援など、さまざまな便利なユーティリティも提供しています。これらのツールは、RLアルゴリズムの中でも頻繁に使用されますが、Acmeではそれらをできるだけシンプルかつ理解しやすいものにすることを目指しています。
この設計を可能にするために、Acmeは機械学習(および強化学習)データ向けに特別に開発された革新的で効率的なデータストレージシステムであるReverbを使用しています。Reverbは、分散強化学習アルゴリズムの経験再生のためのシステムとして主に使用されますが、FIFOや優先度付きキューなどの他のデータ構造表現もサポートしています。これにより、オンポリシーおよびオフポリシーアルゴリズムの両方でシームレスに使用することができます。AcmeとReverbは最初から互換性があるように設計されていますが、Reverbは単独でも完全に使用できるため、ぜひ試してみてください!
インフラストラクチャとともに、Acmeを使用して構築したいくつかのエージェントの単一プロセスの実例も公開しています。これらは連続制御(D4PG、MPOなど)、離散Q学習(DQN、R2D2)などをカバーしています。アクティング/学習の境界を分割することにより、最小限の変更でこれらのエージェントを分散的に実行することができます。最初のリリースでは、学生や研究者によって主に使用される単一プロセスエージェントを重点的に扱っています。
また、これらのエージェントをコントロールスイート、Atari、およびbsuiteという環境で詳細にベンチマークしています。
Acmeフレームワークを使用して訓練されたエージェントを表示するビデオのプレイリスト
さらなる結果は論文で入手できますが、連続制御タスクの単一エージェント(D4PG)のパフォーマンスをアクターステップとウォールクロック時間の両方で測定したプロットをいくつか示します。データがリプレイに挿入される速度を制限する方法により(詳細な議論については論文を参照してください)、エージェントが環境との相互作用(アクターステップ)の数に対して受け取る報酬と比較すると、ほぼ同じパフォーマンスが見られます。しかし、エージェントがさらに並列化されると、学習速度が向上します。観測が小さな特徴空間に制約されている比較的小規模なドメインでは、この並列化のわずかな増加(4つのアクター)でも、最適なポリシーを学習するのにかかる時間が半分以下になります:

しかし、観測が比較的高コストな画像であるより複雑なドメインでは、はるかに大きな利益が得られます:

また、データの収集がより費用がかかり、学習プロセスが一般的に長いAtariゲームなどのドメインでは、利益はさらに大きくなる可能性があります。ただし、これらの結果は、分散および非分散の設定の間で同じ行動コードと学習コードを共有していることに注意することが重要です。したがって、これらのエージェントと結果をより小規模なスケールで実験することは完全に実現可能です。実際、新しいエージェントを開発する際にはいつもこれを行っています!
この設計の詳細な説明およびベースラインエージェントのさらなる結果については、弊社の論文をご覧ください。または、よりよい結果を得るために、弊社のGitHubリポジトリをご覧いただき、Acmeを使って独自のエージェントを簡素化する方法をご確認ください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






