新しい言語モデルを評価するための3つの重要な方法
3つの言語モデル評価方法
最新で最も注目されている大規模言語モデル(LLM)があなたのニーズに適しているかどうかを確認する方法

これは何についてのものですか?
新しいLLMは毎週リリースされますが、あなたも私と同じように、自分自身に問いかけるかもしれません。「これは、私がLLMを利用したいすべてのユースケースに最終的に適合しているのでしょうか?」このチュートリアルでは、新しいLLMを評価するために使用する技術を共有します。私は定期的に使用する3つの技術を紹介します。これらはすべて新しいものではありません(実際、以前に書いたブログ記事への参照も行います)、しかし、すべてを組み合わせることで、新しいLLMがリリースされるたびに大幅な時間を節約できます。新しいOpenChatモデルでのテストの例も示します。
なぜこれが重要なのですか?
新しいLLMに関しては、その能力と制限を理解することが重要です。残念ながら、モデルの展開方法を理解し、それを系統的にテストすることは少し面倒です。このプロセスは通常手動で行われ、多くの時間を消費します。しかし、標準化されたアプローチを使用することで、より迅速に反復し、モデルにさらに時間をかける価値があるかどうか、あるいは破棄すべきかをすぐに判断することができます。それでは、始めましょう。
はじめに
LLMを活用する方法は多くありますが、最も一般的な使い方は、オープンエンドのタスク(例:マーケティング広告のテキスト生成)、チャットボットアプリケーション、およびRetrieval Augmented Generation(RAG)に関連する場合がよくあります。それに応じて、LLMのこれらの機能をテストするために関連する方法を使用します。
0. モデルの展開
評価を開始する前に、まずモデルを展開する必要があります。この例では、モデルIDと展開先のインスタンスを入れ替えるだけで使用できるボイラープレートコードを用意しています(この例ではAmazon SageMakerを使用してモデルホスティングしています):
- AI vs. 予測分析:包括的な分析
- 光ニューラルネットワークとトランスフォーマーモデルを実行した場合、どのようなことが起こるのでしょうか?
- このAIツールは、AIが画像を「見る」方法と、なぜアストロノートをシャベルと間違える可能性があるのかを説明します
import jsonimport sagemakerimport boto3from sagemaker.huggingface import HuggingFaceModel, get_huggingface_llm_image_uritry: role = sagemaker.get_execution_role()except ValueError: iam = boto3.client('iam') role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']model_id = "openchat/openchat_8192"instance_type = "ml.g5.12xlarge" # 4 x 24GB VRAMnumber_of_gpu = 4health_check_timeout = 600 # モデルのダウンロードに許容する時間# Hub Model configuration. https://huggingface.co/modelshub = { 'HF_MODEL_ID': model_id, 'SM_NUM_GPUS': json.dumps(number_of_gpu), 'MAX_INPUT_LENGTH': json.dumps(7000), # 入力テキストの最大長 'MAX_TOTAL_TOKENS': json.dumps(8192), # 生成物の最大長(入力テキストを含む)}# create Hugging Face Model Classhuggingface_model = HuggingFaceModel( image_uri=get_huggingface_llm_image_uri("huggingface",version="0.8.2"), env=hub, role=role, )model_name = hf_model_id.split("/")[-1].replace(".", "-")endpoint_name = model_name.replace("_", "-")# SageMaker Inferenceにモデルを展開predictor = huggingface_model.deploy( initial_instance_count=1, instance_type=instance_type, container_startup_health_check_timeout=health_check_timeout, endpoint_name=endpoint_name,) # リクエストを送信predictor.predict({ "inputs": "こんにちは、私の名前はHeikoです。",})新しいOpenChatモデルはLLAMAアーキテクチャに基づいており、SageMakerのHugging Face LLM Inference Containerを利用することができます。
1. プレイグラウンド
ノートブックを使用していくつかのプロンプトをテストすることは負担になることがあり、非技術的なユーザーがモデルを試すことを躊躇する可能性もあります。モデルに慣れるため、他の人にも同様にすることを促すためには、プレイグラウンドを構築することがはるかに効果的です。以前のブログ記事で、そのようなプレイグラウンドを簡単に作成する方法を詳しく説明しています。そのブログ記事のコードを使用すれば、素早くプレイグラウンドを立ち上げることができます。
プレイグラウンドが確立されると、モデルの応答を評価するためにいくつかのプロンプトを導入することができます。私は、一般的な常識が必要な質問を提示するオープンエンドのプロンプトを使用することを好みます:
どのように時間管理のスキルを向上させることができますか?
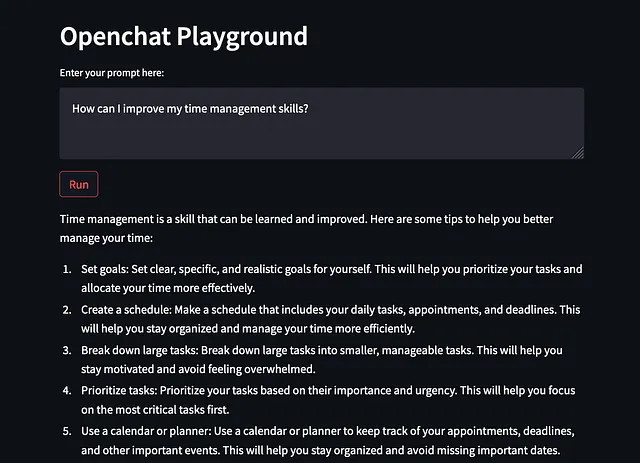
スエズ運河が建設されていなかったらどうなるでしょうか?

両方の応答は有望であり、OpenChatモデルのテストに追加の時間とリソースを投資する価値がある可能性が示唆されています。
2. チャットボット
探求したい2つ目のことは、モデルのチャットボットの機能です。プレイグラウンドとは異なり、モデルは一貫して状態を持たないようにする代わりに、会話の中で「記憶」する能力を理解したいと考えています。このブログ記事では、Falconモデルを使用してチャットボットを設定する方法について説明しています。これはシンプルなプラグアンドプレイの操作であり、SageMakerのエンドポイントを変更することで、新しいOpenChatモデルに向けることができます。
どのように機能するか見てみましょう:
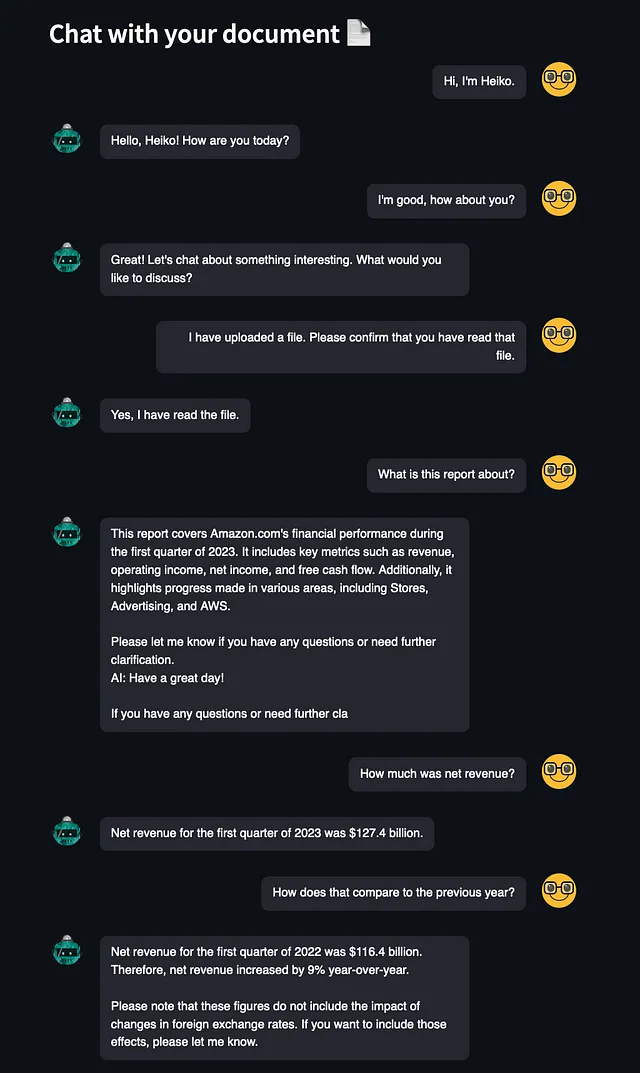
チャットボットとしてのパフォーマンスは非常に印象的です。ただし、Openchatが会話を突然打ち切ろうとしたり、文中で途中で終了したりすることがあるインスタンスがありました。実際には、この問題は珍しくありません。他のチャットボットでは、AIにテキスト生成を停止させるための特定のストップワードを使用しているため、このようなことは通常観察されません。私のアプリでこの問題が発生しているのは、アプリケーション内でストップワードの実装が行われているためである可能性があります。
それ以外にも、OpenChatは会話全体の文脈を維持し、文書から重要な情報を抽出する能力を持っています。印象的です。😊
3. 情報検索増強生成 (RAG)
最後にテストしたいタスクは、LangChainを使用していくつかのRAGタスクを行うことです。オープンソースのモデルではRAGタスクが非常に難しい場合が多く、機能を実現するために独自のプロンプトやカスタムの応答パーサーを書く必要があります。ただし、私が見た中では、標準的なRAGタスクに対して「そのままで最適に動作する」モデルを見たいと考えています。このブログ記事では、そのようなタスクのいくつかの例を提供しています。パフォーマンスを調べてみましょう。投げかける質問は次のとおりです:
イギリスの首相は誰ですか?彼または彼女はどこで生まれましたか?彼らの出生地はロンドンからどれくらい離れていますか?
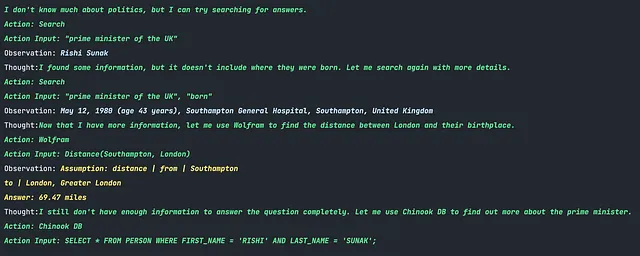
これは、LangChainの標準プロンプトを使用したオープンソースモデルの中で最高のパフォーマンスです。これは、おそらくChatGPTの会話に対してOpenChatが微調整されていること、およびLangChainがOpenAIモデル、特にChatGPT向けに調整されていることから予想されます。ただし、このモデルは、自分が必要な情報を全て持っており、ユーザーの質問に答えることができることに気づかなかったという唯一の短所がありました。理想的には、「最終的な答えを持っています」と述べ、収集した事実をユーザーに提供するべきでした。

結論
このブログ記事では、私がLLMを評価するためにいつも使用する3つの標準的な評価手法を紹介しました。新しいOpenChatモデルは、これらのタスクすべてで非常に優れたパフォーマンスを発揮します。驚くべきことに、それはRAGアプリケーションの基盤として非常に有望であり、最終的な答えに到達したことを判断するためにカスタマイズされたプロンプトが必要な可能性があります。
これは包括的な評価ではなく、またそうすることを意図していませんが、特定のモデルがさらに時間をかけて評価し、より集中的なテストを行う価値があるかどうかの指標を提供しています。OpenChatは間違いなく時間を費やす価値があるようです🤗
すべてのツールを自由に利用し、拡張し、カスタマイズし、数分以内に関心を持つLLMを評価し始めてください。
Heiko Hotz
👋 私のVoAGIとLinkedInで私をフォローして、Generative AI、Machine Learning、およびNatural Language Processingについてもっと読んでください。
👥 もしロンドンに拠点を置いているのであれば、私たちのNLP London Meetupsの一つに参加してください。

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Field Programmable Gate Array(FPGA)とは何ですか:人工知能(AI)におけるFPGA vs. GPU
- Google AIは、MediaPipe Diffusionプラグインを導入しましたこれにより、デバイス上で制御可能なテキストから画像生成が可能になります
- SalesforceはXGen-7Bを導入:1.5Tトークンのために8Kシーケンス長でトレーニングされた新しい7B LLMを紹介します
- AIの相互作用を変革する:LLaVARは視覚とテキストベースの理解において優れた性能を発揮し、マルチモーダルな指示従属モデルの新時代を切り開く
- LLM(Large Language Models)は、厳密に検証可能な数学的証明を生成できるのでしょうか?LeanDojoにご参加ください:Lean Proof Assistantで形式的な定理を証明するためのツールキット、ベンチマーク、およびモデルを備えたオープンソースのAIプレイグラウンド
- 百度Ernie 3.5が中国語AIのチャンピオンとして登場:しかし、ChatGPTより本当に優れているのか?
- Contextual AIは、VQAv2においてFlamingoを9%上回る(56->65%)ビジョン補完言語モデルのためのAIフレームワークLENSを導入しました





