新しい研究によって、テキストをスムーズに音声化することができるようになりました | Google
新しい研究によって、テキストを音声化することが可能になりました | Google
明示的に指定せずに、シーケンスの長さの不一致を克服する。
要約
テキスト音声(マルチモーダルモデル)のトレーニングには、独自の問題があります。オーディオのサンプルレートが高い場合、オーディオのシーケンスの長さは対応するテキストよりもはるかに長くなります。テキストとオーディオを同時にトレーニングするために、この不均衡を克服する必要があります(明示的に注釈付きのトレーニングデータを生成せずに怠惰に)。この論文はその問題を解決します。
概要
昨年、テキストによる画像生成の進歩が目覚ましいものとなり、テキストと画像のドメインが共同で表現されるクロスモーダル表現空間の考えに基づくものとなりました。
自動音声認識(ASR)においては、この考え方が音声とテキストの両方を訓練データとして使用し、非対称な音声とテキストのシーケンス長の不一致を特別に扱うことなく、非常に大きなパラメータモデルにスケールすることができる共同音声テキストエンコーダとして応用されています。これらの手法は有望ですが、音声とテキストのシーケンス長の不一致には、アップサンプリングヒューリスティクスまたは明示的なアラインメントモデルによる特別な処理が必要でした。
本研究では、共同音声テキストエンコーダはシーケンスの長さを無視することにより、モダリティ間で一貫した表現を自然に実現することを証明し、一貫性の損失が長さの違いを許し、最良のアラインメントを仮定することができると主張しています。このような損失が、大規模なモノリンガルおよびマルチリンガルシステムの下流ワードエラーレート(WER)を改善することを示しています。
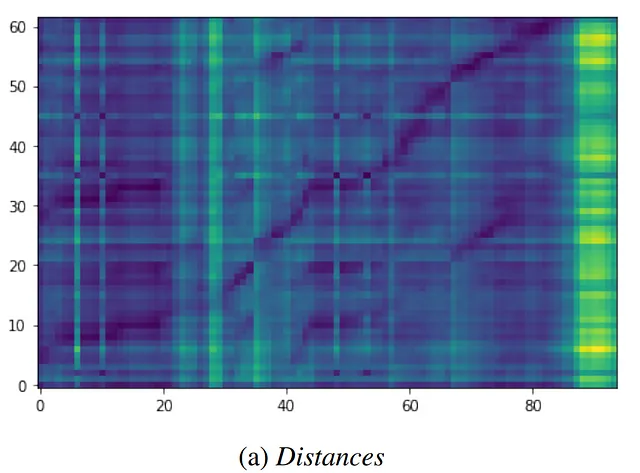
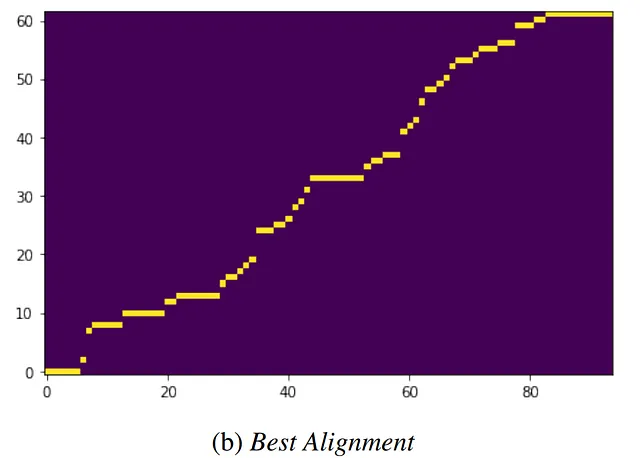
解決の理論
両方のモダリティ(ここでは、音声とテキスト)で大規模なエンコーダを別々にトレーニングします。この方法では、各モダリティは対になっていない例を提供し、メタモデルは時間次元でペアの例をマッピングする方法を学習します。この表現は、画像+テキストのモダリティで最先端のパフォーマンスを提供できます。ただし、オーディオ+テキストのモダリティ組み合わせではうまく機能しません。
音声認識は、2つのシーケンスモダリティの特定の課題を提供します。…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」という文を日本語に翻訳すると、以下のようになります: 「ライス大学とIITカーンプールは、共同研究賞の受賞者を発表します」
- CMUの研究者たちは、視覚的な先行知識をロボティクスのタスクに転送するためのシンプルなディスタンスラーニングAIメソッドを開発しました:ベースラインに比べてポリシーラーニングを20%改善
- 「MITとハーバードの研究者は、脳内の生物学的な要素を使ってトランスフォーマーを作る方法を説明する可能性のある仮説を提出しました」
- Google DeepMindの研究者は、機能を維持しながら、トランスフォーマーベースのニューラルネットワークのサイズを段階的に増やすための6つの組み合わせ可能な変換を提案しています
- 「LangChainとGPT-4を使用した多言語対応のFEMAディザスターボットの研究」
- コンピュータ科学の研究者たちは、モジュラーで柔軟なロボットを作りました
- MITの研究者は、ディープラーニングと物理学を組み合わせて、動きによって損傷を受けたMRIスキャンを修正する方法を開発しました





